




 相关性算分是排序文档的关键,基于倒排索引,通过TF、DF和IDF等参数评估相关度。BM25是Elasticsearch 5.x后的默认模型,优化了TF/IDF,当词频过高时降低其权重,超过一定数量的词不再计入算分,有助于论文查重,建议使用专业词汇。
相关性算分是排序文档的关键,基于倒排索引,通过TF、DF和IDF等参数评估相关度。BM25是Elasticsearch 5.x后的默认模型,优化了TF/IDF,当词频过高时降低其权重,超过一定数量的词不再计入算分,有助于论文查重,建议使用专业词汇。
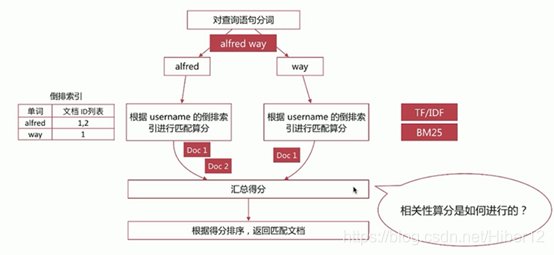
相关性算分:指文档与查询语句间的相关度,通过倒排索引可以获取与查询语句相匹配的文档列表
如何将最符合用户查询需求的文档放到前列呢?
本质问题是一个排序的问题,排序的依据是相关性算分,确定倒排索引哪个文档排在前面
影响相关度算分的参数:
1、TF(Term Frequency):词频,即单词在文档中出现的次数,词频越高,相关度越高
2、Document Frequency(DF):文档词频,即单词出现的文档数
3、IDF(Inverse Document Frequency):逆向文档词频,与文档词频相反,即1/DF。即单词出现的文档数越少,相关度越高(如果一个单词在文档集出现越少,算为越重要单词)
4、Field-length Norm:文档越短,相关度越高
——TF/IDE模型
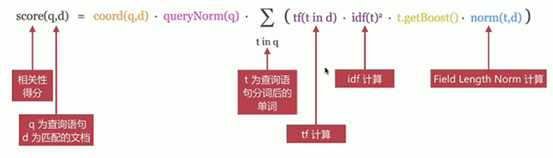
——BM25模型(5.X之后的默认模型)
对之前算分进行优化
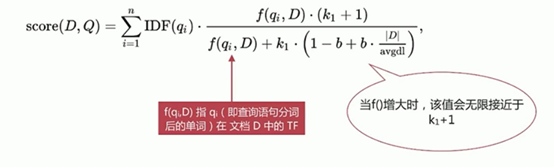
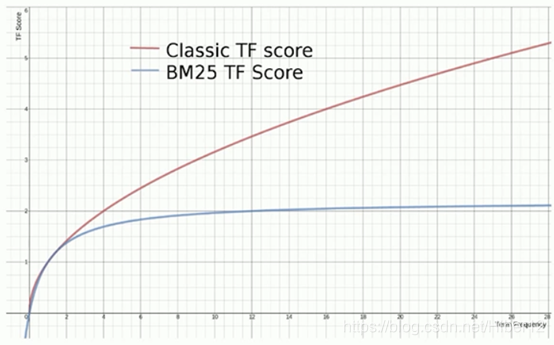
BM25相比TF/IDF的一大优化是降低了tf在过大时的权重,避免词频对查询影响过大
总结一句话就是:BM25算法的优化,如果你单个词超过一定数量,这个词超过的那部分,将不进行算分!
这也就是应用到论文查重了,多写专业用词,避免常规用词!

















 2971
2971

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









