




 BM25是基于TF - IDF改进的信息检索算法,用于估计文档与查询的相关性。文章介绍了其基本公式、IDF计算方法,阐述了主要流程,包括数据预处理、计算得分函数、匹配程度及返回最匹配文档,还给出了Python简单实现、调用gensim实现及rank - bm25的使用方法。
BM25是基于TF - IDF改进的信息检索算法,用于估计文档与查询的相关性。文章介绍了其基本公式、IDF计算方法,阐述了主要流程,包括数据预处理、计算得分函数、匹配程度及返回最匹配文档,还给出了Python简单实现、调用gensim实现及rank - bm25的使用方法。
1.简介
BM25(Best Matching 25)是一种经典的信息检索算法,是基于 TF-IDF算法的改进版本,旨在解决、TF-IDF算法的一些不足之处。其被广泛应用于信息检索领域的排名函数,用于估计文档D与用户查询Q之间的相关性。它是一种基于概率检索框架的改进,特别是在处理长文档和短查询时表现出色。BM25的核心思想是基于词频(TF)和逆文档频率(IDF)来,同时还引入了文档的长度信息来计算文档D和查询Q之间的相关性。目前被广泛运用的搜索引擎ES就内置了BM25算法进行全文检索。
BM25算法的基本公式
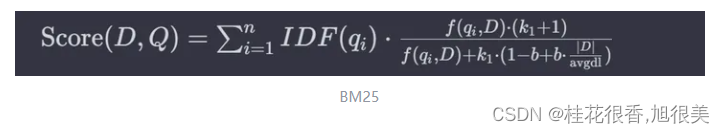
- Score(D,Q) 是文档 D 与查询 Q 的相关性得分。
- qi 是查询中的第 i 个词。
- f(qi, D)是词 qi 在文档 D 中的频率。
- IDF(qi) 是词qi 的逆文档频率。
- |D| 是文档 D的长度。
- avgdl是所有文档的平均长度。
- k1 和 b 是可调的参数,通常 k1 在1.2到2之间, b通常设为0.75。
IDF计算方法
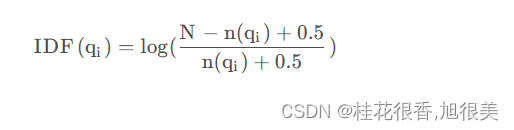
- N 是文档集合中的文档总数
- n(q1)是包含词q1的文档数量
- 词频 (f(qi, D)): 这是查询中的词 q_i在文档 D 中出现的频率。词频是衡量一个词在文档中重要性的基本指标。词频越高,这个词在文档中的重要性通常越大。
- 逆文档频率 (IDF(qi)): 逆文档频率是衡量一个词对于整个文档集合的独特性或信息量的指标。它是由整个文档集合中包含该词的文档数量决定的。一个词在很多文档中出现,其IDF值就会低,反之则高。这意味着罕见的词通常有更高的IDF值,从而在相关性评分中拥有更大的权重。
- 文档长度 (|D|): 这是文档D 中的词汇数量。文档长度用于调整词频的影响,因为较长的文档可能仅因为它们的长度就有更高的词频。
- 平均文档长度 (avgdl): 这是整个文档集合中所有文档长度的平均值。它用于标准化不同文档的长度,以便可以公平比较不同长度的文档。
- 可调参数 (k1 和 b):
- k1 是一个正系数,用于控制词频的饱和度。较高的 k1 值意味着词频对评分的影响更大。
- b 是用于控制文档长度对评分的影响的参数,取值在0到1之间。当 b=1 时,文档长度的影响最大;当b = 0 时,文档长度不影响评分。
2. 主要流程
1 数据预处理
- 首先需要将文档进行数据预处理,包括分词、去除停用词、词干提取和标准化等步骤。
2 计算文档和查询条件中各个项的得分函数
- 该步骤计算每个文档和查询条件中各个项的得分函数,并将其存储在倒排索引中。
3 计算文档与查询条件之间的匹配程度
- 计算文档与查询条件之间的匹配程度得分。该步骤会计算所有匹配的文档的得分值,并按照得分值的大小对文档进行排序。
4 返回最匹配的文档
- 返回最匹配的文档。
3. python 简单实现
import math
from collections import Counter
class BM25:
def __init__(self, docs, k1=1.5, b=0.75):
"""
BM25算法的构造器
:param docs: 分词后的文档列表,每个文档是一个包含词汇的列表
:param k1: BM25算法中的调节参数k1
:param b: BM25算法中的调节参数b
"""
self.docs = docs
self.k1 = k1
self.b = b
self.doc_len = [len(doc) for doc in docs] # 计算每个文档的长度
self.avgdl = sum(self.doc_len) / len(docs) # 计算所有文档的平均长度
self.doc_freqs = [] # 存储每个文档的词频
self.idf = {
} # 存储每个词的逆文档频率
self.initialize()
def initialize(self):
"""
初始化方法,计算所有词的逆文档频率
"""
df = {
} # 用于存储每个词在多少不同文档中出现
for doc in self.docs:
# 为每个文档创建一个词频统计
self.doc_freqs.append(Counter(doc))
# 更新df值
for word in set(doc):
df[word] = df.get(word, 0) + 1
# 计算每个词的IDF值
for word, freq in df.items():
self.idf[word] = math.log((len(self.docs) - freq + 0.5) / (freq + 0.5) + 1)
def score(self, doc, query):
"""
计算文档与查询的BM25得分
:param doc: 文档的索引
:param query: 查询词列表
:return: 该文档与查询的相关性得分
"""
score = 0.0
for word in query:
if word in self.doc_freqs[doc]:
freq = self.doc_freqs[doc][word] # 词在文档中的频率
# 应用BM25计算公式
score += (self.idf[word] * freq * (self.k1 + 1)) / (freq + self.k1 * (1 - self.b + self.b * self.doc_len[doc] / self.avgdl))
return score
# 示例文档集和查询
docs = [["the", "quick", "brown", "fox"],
["the", "lazy", "dog"],
["the", "quick", "dog"],
["the", "quick", "brown", "brown", "fox"]]
query = ["quick", "brown"]
# 初始化BM25模型并计算得分
bm25 = BM25(docs)
scores = [bm25.score(i, query) for i in range(len(docs))]
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









