






首先说明,兼容版本质上还是1.x,只不过是用了2.x的包
1.保存模型
# 禁用急切执行,兼容版,直接用急切执行会混乱
tf.compat.v1.disable_eager_execution()
saver = tf.compat.v1.train.Saver()
saver.save(sess, 'D:/model.ckpt')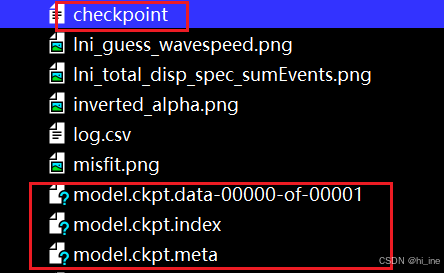
保存的内容--checkpoint的几个文件简介(4个文件)
checkpoint的一般格式如下:
(1)meta文件
.meta文件:一个协议缓冲,保存tensorflow中完整的graph、variables、operation、collection;这是我们恢复模型结构的参照;
meta文件保存的是图结构,通俗地讲就是神经网络的网络结构。当然在使用低层PAI编写神经网络的时候,本质上是一系列运算以及张量构造的一个较为复杂的graph,这个和高层API中的层的概念还是有区别的,但是可以这么去理解,整个graph的结构就是网络结构。一般而言网络结构是不会发生改变,所以可以只保存一个就行了。我们可以使用下面的代码只在第一次保存meta文件。
saver.save(sess, 'my_model.ckpt', global_step=step, write_meta_graph=False)
在后面恢复整个graph的结构的时候,并且还可以使用
tf.train.import_meta_graph(‘xxxxxx.meta’)
能够导入图结构。
(2)data文件
keypoint_model.ckpt-9.data-00000-of-00001:数据文件,保存的是网络的权值,偏置,操作等等。
(3)index文件
keypoint_model.ckpt-9.index 是一个不可变得字符串字典,每一个键都是张量的名称,它的值是一个序列化的BundleEntryProto。 每个BundleEntryProto描述张量的元数据,所谓的元数据就是描述这个Variable 的一些信息的数据。 “数据”文件中的哪个文件包含张量的内容,该文件的偏移量,校验和,一些辅助数据等等。
Note: 以前的版本中tensorflow的model只保存一个文件中。
(4)checkpoint文件——文本文件
checkpoint是一个文本文件,记录了训练过程中在所有中间节点上保存的模型的名称,首行记录的是最后(最近)一次保存的模型名称。checkpoint是检查点文件,文件保存了一个目录下所有的模型文件列表
来自:tensorflow中的检查点checkpoint详解(二)——以tensorflow1.x 的模型保存与恢复为主_tensorflow1.5中怎么恢复检查点中的模型-优快云博客
2.查看文件
from tensorflow.python.tools import inspect_checkpoint as chkp
import sys
# 定义输出文件路径
output_file = "output_tensors.txt"
# 重定向标准输出到文件
with open(output_file, "w") as f:
# 重定向标准输出到文件
sys.stdout = f
# 打印所有张量的名称和数据
chkp.print_tensors_in_checkpoint_file(
file_name="D:/model.ckpt",
tensor_name='',
all_tensors=True,
all_tensor_names=True
)
# 恢复标准输出
sys.stdout = sys.__stdout__
print(f"Tensor details have been saved to {output_file}")把输出的文件张量放到一个txt文件中用作对比
3.恢复模型
saver = tf.compat.v1.train.Saver()
with tf.compat.v1.Session() as sess:
sess.run(tf.compat.v1.global_variables_initializer())
# 导入模型的图结构
new_saver = tf.compat.v1.train.import_meta_graph('D:/model.ckpt.meta')
# 恢复图中的各个变量
new_saver.restore(sess, 'D:1/model.ckpt')
# 获取当前图
graph = tf.compat.v1.get_default_graph()
saver.save(sess, 'D:/model.ckpt')
# 获取输入张量和输出张量
X = graph.get_tensor_by_name('model_inputx:0') # 输入的节点名称
Z = graph.get_tensor_by_name('model_inputz:0') # 输入的节点名称
T = graph.get_tensor_by_name('model_inputt:0')
model_y = graph.get_tensor_by_name('model_output:0')
input_x = XX[:, 0:1].astype(np.float64)
input_z = XX[:, 1:2].astype(np.float64)
input_t = XX[:, 2:3].astype(np.float64)
# 运行模型
result = sess.run(model_y, feed_dict={X: input_x, Z: input_z, T: input_t})其中,输入节点和输出节点是自己命名的,之前通过tensorboard生成过graph,但是生成的是训练图,没有输出节点,我就直接把输入和输出张量命名了,后续直接用命名的就可以了,前边的命名为:
x = tf.compat.v1.placeholder(tf.float64, shape=(None,1),name="model_inputx")
z = tf.compat.v1.placeholder(tf.float64, shape=(None,1),name="model_inputz")
t = tf.compat.v1.placeholder(tf.float64, shape=(None,1),name="model_inputt")然后自己的神经网络预测输出命名为输出。
这样子运行的话我基本上恢复了中断前的损失。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









