






1、算法介绍
语音识别(Speech Recognition)也被称为自动语音识别(英语:Automatic Speech Recognition, ASR),是将语音音频转换为文字的技术。
ASR语音识别技术应用广泛,下面列出几个主要领域:
1.语音控制
语音控制可以实现人机交互,包括打电话、播放音乐、调节电视频道等。语音控制一般需结合智能家居等场景使用,是该技术被广泛应用的一个实例。
2.智能客服
智能客服是基于自然语言处理技术,针对用户的问题提供自动回答的服务。在流量高峰期间,客服人员有时难以满足用户的需求,因此智能客服的应用有助于解决此类问题。
3.听写
听写系统是将口头语言转换成文字的系统,主要应用于教育、医疗、司法等领域。听写系统可以帮助用户快速录入文字,提高效率。
4.自动字幕
自动字幕技术是利用ASR语音识别技术实现将语音转换为文字,同时还会在视频或直播内容中加入相应的文本字幕。当有听障人士观看视频时,字幕技术可以帮助他们理解清晰的内容。
2、原理介绍
整个过程遵循“输入-编码-解码-输出”的过程:
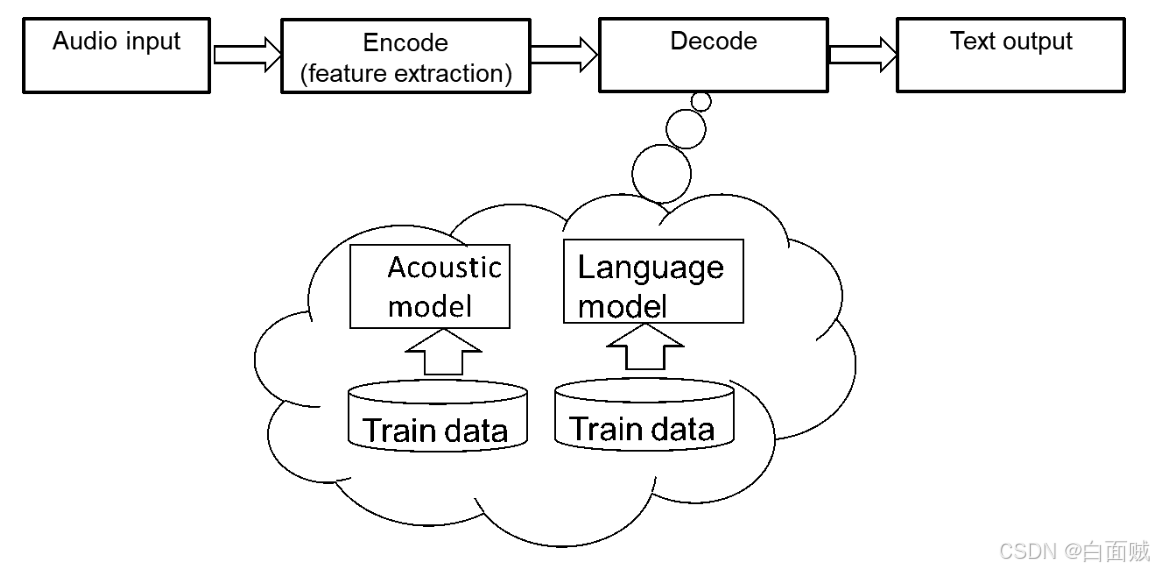
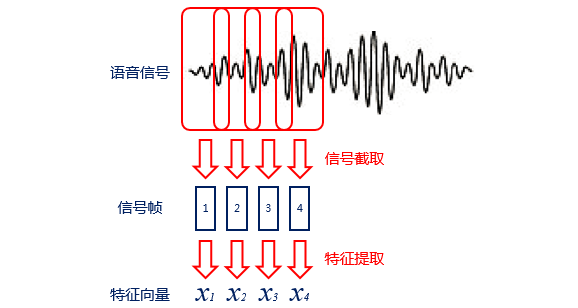
编码过程:语音识别的输入是声音,属于计算机无法直接处理的信号,所以需要编码过程将其转变为数字信息,并提取其中的特征进行处理。编码时一般会将声音信号按照很短的时间间隔,切成小段,成为帧。对于每一帧,可以通过某种规则(例如MFCC特征)提取信号中的特征,将其变成一个多维向量。向量中的每个维度都是这帧信号的一个特征。
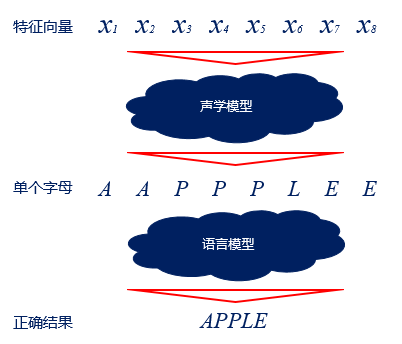
解码过程:解码过程则是将编码得到的向量变成文字的过程,需要经过两个模型的处理,一个模型是声学模型,一个模型是语言模型。声学模型通过处理编码得到的向量,将相邻的帧组合起来变成音素,如中文拼音中的声母和韵母,再组合起来变成单个单词或汉字。语言模型用来调整声学模型所得到的不合逻辑的字词,使识别结果变得通顺。两者都需要大量数据用来训练。
输入是一整段语音,输出是对应的文本,两端都能处理成规则的数学表示形式,只要数据足够,模型合适,我们也许能训练出一个好的端对端模型。
3、算法测评标准
语音识别的精准与否,主要是计算字错率WER、句错率SER,实际工作中,一般识别率的直接指标是“WER(词错误率,Word Error Rate)”
定义:为了使识别出来的词序列和标准的词序列之间保持一致,需要进行替换、删除或者插入某些词,这些插入、替换或删除的词的总个数,除以标准的词序列中词的总个数的百分比,即为WER。
WER公式为:
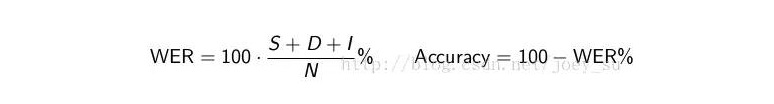
Substitution——替换
Deletion——删除
Insertion——插入
N——单词数目
举例如下
标准词序列:
I went to the hospital yesterday because of a severe cold。
识别词序列:
I went went to the hospital yesterday because a serious cold。
Substitution = 1
Deletion = 1
Insertion = 1
N = 11
那么计算结果:WER = 100*(1+1+1)/11%=27%,同时计算出Accuracy = 73%。
当然实际业务情况,远比这个复杂:
1)WER可以分男女、快慢、口音、数字/英文/中文等情况,分别来看。甚至还有混杂场景。
2)因为有插入词,所以理论上WER有可能大于100%,但实际中、特别是大样本量的时候,是不可能的,否则就太差了,不可能被商用。
3)站在纯产品体验角度,很多人会以为识别率应该等于“句子识别正确的个数/总的句子个数”,即“识别(正确)率等于96%”这种,实际工作中,这个应该指向“SER(句错误率,Sentence Error Rate)”,即“句子识别错误的个数/总的句子个数”。不过据说在实际工作中,一般句错误率是字错误率的2~3倍,所以可能就不怎么看了。
那么目前的行业标准是多少呢?
英语-WER;
IBM:行业标准Switchboard语音识别任务,2016年 6.9%,2017年 5.5%
微软:行业标准Switchboard语音识别任务,2016年 6.3% -> 5.9%,2017年 5.1%,这个目前最低的。
说明:ICASSP2017上IBM说人类速记员WER是5.1%,一般认为5.9% 的字错率是人类速记员的水平。
中文-WER/CER:
小米:2018年 小米电视 2.81%
百度:2016年 短语识别 3.7%
中文-W.Corr:
百度:2016年 识别准确率 97%
搜狗:2016年 识别准确率 97%
讯飞:2016年 识别准确率 97%
4、其他
声音检测 Voice Activity Detection
声音检测常用的指标是识别错率(Detection Error Rate),公式为:
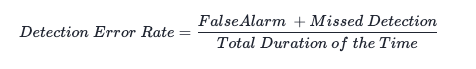
其中
●False Alarm, 将非语音片段识别成为语音片段的时间,简称“狼来了”;
●Missed Speech, 将语音片段识别成为非语音片段的时间,简称“脱靶”;
●Total Duration of the Time, 参考语音标注片段的总时长。
同时,声音检测也可以使用正确率(Accurancy, 预测值将输入标签识别正确的比例),召回率(Recall,预测值中的语音片段占整体语音片段的比例)和准确率(Precision, 检测出来的语音标签中真正的语音标签的比例)。
主要是非标准的语音识别场景,复杂背景音的业务场景。
话者分离 Speaker Diarization
说话人分离(Speaker Diarization),指将语音按照说话人ID分类,解决“Who spoke when”的问题。
其中的难点在于:
1事先不知道有多少个说话人;
2不清楚说话人的ID;
3多人同时说话;
4不同语音的音频条件都不同。
语音会被划分为说话人组,语音非语音的片段或说话人转变等事件会被检测出来。在实际分离过程中,不需要知道说话人是谁。

话者分离常用的指标是分离错误率(Diarization Error Rate, DER)
最后,推荐阅读:
新手语音入门(三): 语音识别ASR算法初探 | 编码与解码 | 声学模型与语音模型 | 贝叶斯公式 | 音素-云社区-华为云
若有收获,就点个赞吧

















 7733
7733

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









