






一、加载数据集
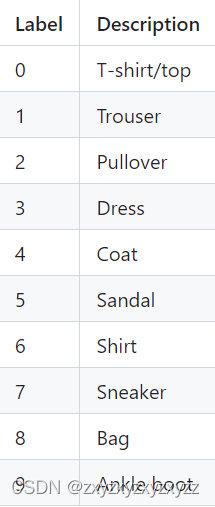
在开始训练之前,首先需要下载数据集并对其进行预处理。我们以Fashion-MNIST数据集为例,这是一个包含10种时尚物品的数据集。
import torch
from torchvision import datasets, transforms
def load_dataset():
# 数据预处理流程 将数据转化为张量并对其进行归一化
data_transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5, ), (0.5, ))])
# 下载训练数据并创建训练数据加载器
train_set = datasets.FashionMNIST("dataset/", download=True, train=True, transform=data_transform)
trainloader = torch.utils.data.DataLoader(train_set, batch_size=64, shuffle=True)
# 下载测试数据并创建测试数据加载器
test_set = datasets.FashionMNIST("dataset/", download=True, train=False, transform=data_transform)
testloader = torch.utils.data.DataLoader(test_set, batch_size=64, shuffle=True)
# 返回训练数据和测试数据加载器
return trainloader, testloader二、搭建模型
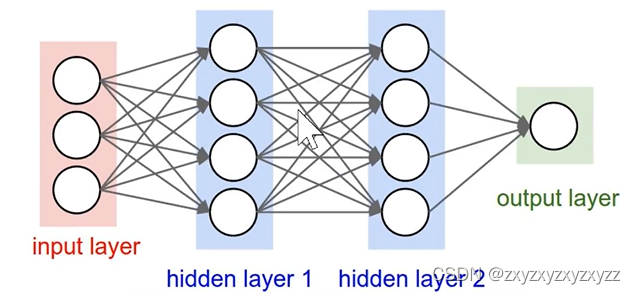
我们简要搭建一个由全连接层构成的神经网络结构,如下图所示。
from torch import nn
import torch.nn.functional as F
class Classifier(nn.Module):
def __init__(self):
super().__init__()
# 模型神经网络结构
self.fc1 = nn.Linear(784, 256)
self.fc2 = nn.Linear(256, 128)
self.fc3 = nn.Linear(128, 64)
self.fc4 = nn.Linear(64, 10)
# 随机掐死一部分神经元
self.dropout = nn.Dropout(p=0.2)
def forward(self, x):
x = x.view(x.shape[0], -1)
# 模型前向传播过程
x = self.dropout(F.relu(self.fc1(x)))
x = self.dropout(F.relu(self.fc2(x)))
x = self.dropout(F.relu(self.fc3(x)))
x = F.log_softmax(self.fc4(x), dim=1)
return x
三、训练过程
在加载数据集并搭建好模型后,就可以开始训练了。首先,我们定义一个用于训练的类。然后,我们在开始训练前,先设定好一些基本的参数,例如损失函数,优化器,epoch等。
import torch
from models import Classifier
from torch import nn, optim
import matplotlib.pyplot as plt
from datasets import load_dataset
class training():
def __init__(self):
self.epoch = 15
def training(self):
# best_model用于保存测试效果最好的模型参数,best_loss用于保存效果最好的模型测试loss
best_model = {}
best_loss = 1
# 初始化模型
model = Classifier()
# 创建训练数据和测试数据加载器
trainloader, testloader = load_dataset()
# 定义loss
loss_function = nn.NLLLoss()
# 定义优化器
optimizer = optim.Adam(model.parameters(), lr=0.003)
# train_losses和test_losses分别用于记录训练过程中每个epoch的loss
train_losses, test_losses = [], []
print("------------开始训练------------")
# 开始训练
for i in range(self.epoch):
running_loss = 0
# 导入一个批次的数据
for images, labels in trainloader:
# 梯度清零
optimizer.zero_grad()
# 推理
predicts = model(images)
# 计算loss
loss = loss_function(predicts, labels)
# 反向传播
loss.backward()
# 优化参数
optimizer.step()
# 将张量转化为标量 方便累加
running_loss += loss.item()
else:
test_loss = 0
# 准确度
accuracy = 0
with torch.no_grad():
# 使模型进入评估模式,例如取消dropout
model.eval()
for images, labels in testloader:
# 推理
predicts = model(images)
test_loss += loss_function(predicts, labels)
# 计算每种类别的概率 最大值为1
pr = torch.exp(predicts)
# 取最大的概率和类别
top_p, top_class = pr.topk(1, dim=1)
# 转化为0,1,方便计算准确度
res = top_class == labels.view(*top_class.shape)
# 计算准确度
accuracy += torch.mean(res.type(torch.FloatTensor))
# 使模型进入训练模式
model.train()
# 计算当前epoch的loss
epoch_train_loss = running_loss/len(trainloader)
epoch_test_loss = test_loss/len(testloader)
epoch_accuracy = accuracy/len(testloader)
# 记录所有epoch的loss
train_losses.append(epoch_train_loss)
test_losses.append(epoch_test_loss)
# 保存最佳模型
if epoch_test_loss < best_loss:
best_model = model.state_dict()
best_loss = epoch_test_loss
print("epoch:{}/{}..".format(i+1, self.epoch),
"epoch_train_loss:{}..".format(epoch_train_loss),
"epoch_test_loss:{}..".format(epoch_test_loss),
"epoch_accuracy:{}".format(epoch_accuracy))
torch.save(best_model, "saved_models/best_model.pth")
plt.plot(train_losses, label="train_losses")
plt.plot(test_losses, label="test_losses")
plt.legend()
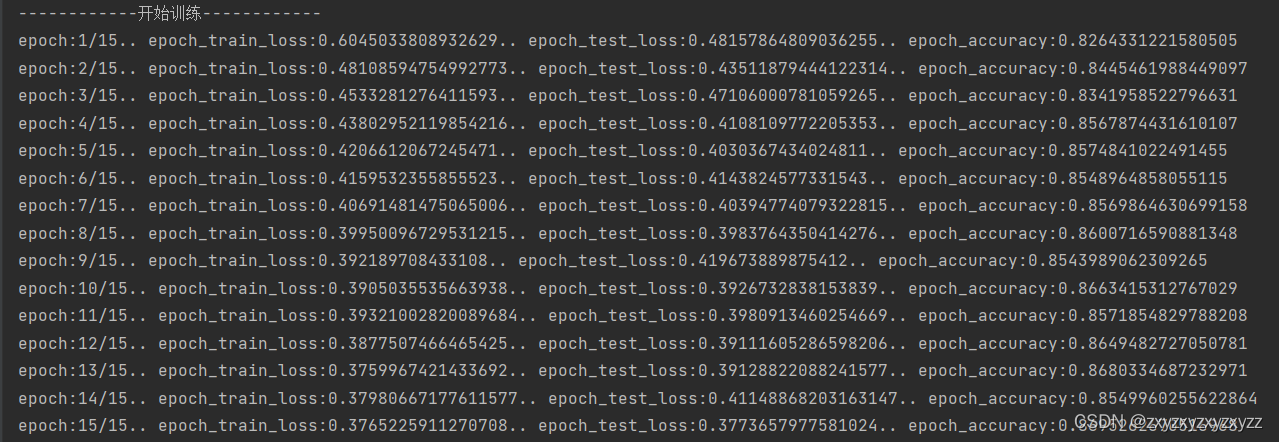
plt.show()训练结果:

















 8189
8189

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









