




 本文介绍如何使用K-means聚类算法为YOLOv2生成Anchor Boxes,包括算法步骤与核心代码实现。
本文介绍如何使用K-means聚类算法为YOLOv2生成Anchor Boxes,包括算法步骤与核心代码实现。
在yolov2及之后的版本中作者都用anchor boxes 取代了中心点的方法,那么如何用K-means聚类算法得到anchor boxes呢?这边给出方法及代码:
传统kmeans聚类算法
kmeans算法算是一个比较经典的算法,主要是通过选取k个聚类中心,利用求各点距离的方法来进行聚类,迭代更新聚类中心。
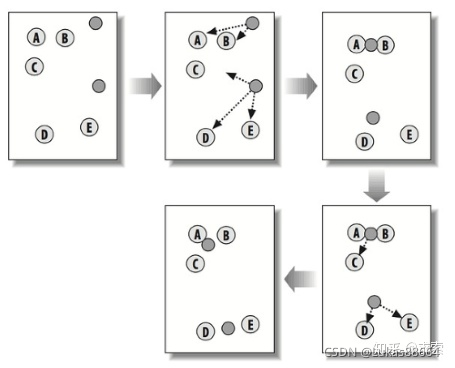
算法步骤:
1.初始化K个簇中心;
2.使用相似性度量(一般是欧氏距离),将每个样本分配给与其距离最近的簇中心;
3.计算每个簇中所有样本的均值,更新簇中心;
4.重复2、3步,直到均簇中心不再变化,或者达到了最大迭代次数。
K-means聚类算法生成anchor boxes
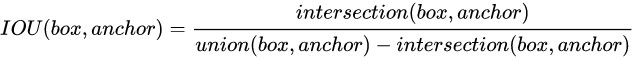
先给出IOU的公式,聚类anchor boxes的欧式距离改为iou。
步骤
对box进行K-means的步骤为:
1.随机选取K个box作为初始anchor;
2.使用IOU度量,将每个box分配给与其iou最大的anchor;
3.计算每个簇中所有box宽和高的均值,更新anchor;
4.重复2、3步,直到anchor不再变化,或者达到了最大迭代次数。
代码还是很值得看一下的:
def iou(boxes, anchors):
"""
Calculate the IOU between  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5007
5007

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









