




目录标题
下面是 PolarDB for PostgreSQL 与 PFS 文件系统 的深入解析,以及与原生 PostgreSQL 主备复制的对比:
📘 一、核心概念与架构
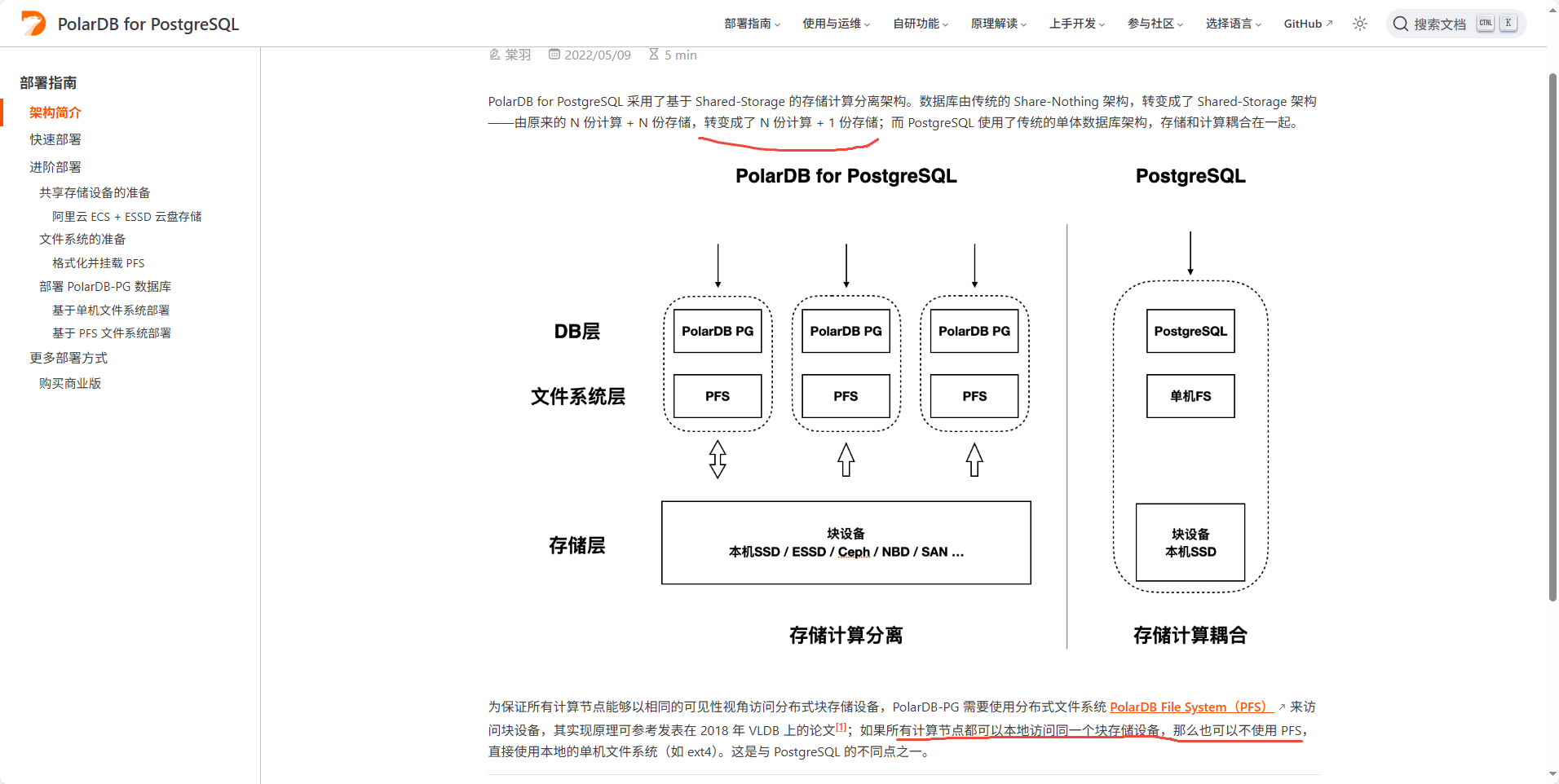
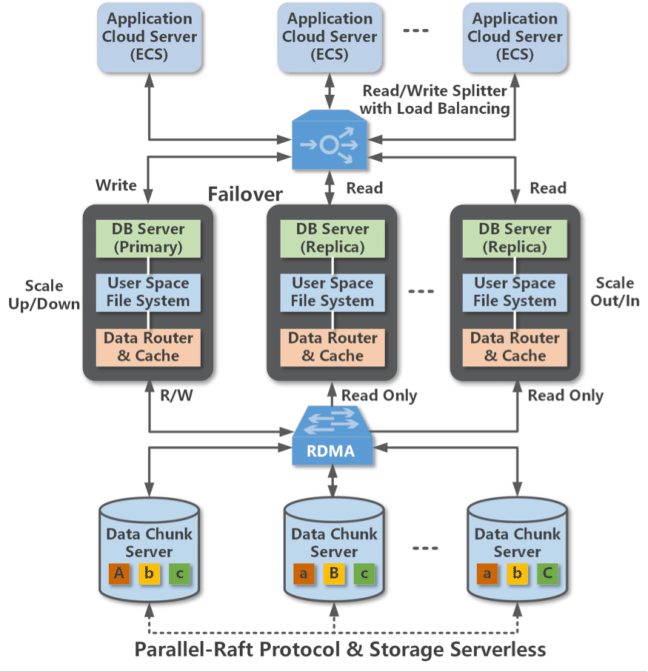
1. 存储–计算分离架构
- PolarDB 的 计算节点(Primary + 多个 Read‑Only) 全部共享一份存储,由后端分布式存储与 PolarDB File System(PFS) 提供统一的数据访问视图 (docs.polardbpg.com, help.aliyun.com)。
- 这样,无需复制数据,计算节点可弹性扩缩容,同时读延时大幅降低,仅同步 WAL 元数据 (docs.polardbpg.com)。
2. PFS — PolarDB File System
- PFS 是用户态 POSIX-like 分布式文件系统,实现 一致性可见、低延迟、支持多个计算节点协调访问底层块存储 (apsaradb.github.io)。
- 它解决多节点对同块设备读写的同步问题,底层通过 log-index + Lazy replay 等机制保证 RW/RO 节点一致性 (github.com)。
3. HTAP + MPP 分析引擎
-
PolarDB 内建两个执行引擎:
- OLTP 引擎:处理高并发事务
- OLAP 分布式执行引擎:针对大查询通过 MPP 并发分片扫描存储,提升复杂查询性能 (docs.polardbpg.com)。
-
顺序扫描时,PFS 适配功能包括:
- 预读机制:128KB 一次批量读取;
- 预扩展机制:4MB 大块扩展,优化写表、索引创建性能 (docs.polardbpg.com)。
🔄 二、与原生 PostgreSQL 主备复制的区别
| 特性 | 原生 PostgreSQL 主备复制 | PolarDB for PostgreSQL(PFS 架构) |
|---|---|---|
| 数据存储方式 | 各节点本地存储独立复制 WAL 发送,网络负载高,维护成本高 | 共享分布式存储,无需全量复制,计算节点直接访问 |
| 延迟 | WAL 传输与 replay 导致至少 几十毫秒 | 仅同步元数据,通过 LogIndex + Lazy & Parallel replay 实现毫秒级同步 (docs.polardbpg.com) |
| 弹性扩缩容 | 新副本需复制完整数据,时间长 | 动态添加计算节点即接入共享存储,几秒级完成,存储节点独立扩展 |
| 读写分离 | 手动配置,副本延迟、故障恢复需人工干预 | 内置读写分离和智能负载均衡,故障自动切换 |
| OLAP 能力 | 单节点并行,资源受限 | MPP 分布式执行,跨多 RO 节点并发协作,IO 带宽线性增长 |
⚙️ 三、PolarDB PFS 技术细节
— 一致性保障
- 主节点写入后同步 WAL 元数据,并广播最新 LSN 到各读节点,由其 replay 保持可见性一致 (researchgate.net)
- 通过 MVCC 与 LogIndex 技术,实现跨节点并发访问的一致性 (github.com)
— I/O 性能优化
- 批量预读 / 预扩展等机制优化顺序读写效率;4MB 扩页、128KB 预读提升吞吐数十倍 (docs.polardbpg.com)
— MPP 分布式查询
- Scan operator 按 4MB 分片并行执行,跨多个 RO 节点并发读取底层多个磁盘的数据片段 (alibabacloud.com)
- BufferPool 缓存为各节点所累加利用,进一步提升 cache hit 与并行性能
✅ 四、总结与建议
- 如果你需要高并发写 + 且常有复杂分析查询,且追求响应一致、快速扩展:PolarDB + PFS 架构远优于传统主备复制。
- 支持毫秒级延迟、秒级故障恢复、自适应扩容以及本地 + 分布式查询一站式能力,是云原生 OLTP/OLAP 混合场景的理想选择。
后续讨论主题,比如 PFS 实操部署步骤、性能调优建议或与 PG 原生复制切换流程对比。

















 3024
3024

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









