







0导入&加载数据
import os
import tarfile
import urllib
import urllib.request
DOWNLOAD_ROOT = "https://raw.githubusercontent.com/ageron/handson-ml2/master/"
HOUSING_PATH = os.path.join("datasets", "housing") # 把目录和文件名合成一个路径
HOUSING_URL = DOWNLOAD_ROOT + "datasets/housing/housing.tgz"
def fetch_housing_data(housing_url=HOUSING_URL, housing_path=HOUSING_PATH):
if not os.path.isdir(housing_path): # 判断路径是否为目录
os.makedirs(housing_path) # 递归创建目录
tgz_path = os.path.join(housing_path, "housing.tgz")
urllib.request.urlretrieve(housing_url, tgz_path) # 将URL检索到磁盘上的临时位置
housing_tgz = tarfile.open(tgz_path) # 打开
housing_tgz.extractall(path=housing_path) # 解压
housing_tgz.close() # 关闭
fetch_housing_data()
import pandas as pd
def load_housing_data(housing_path=HOUSING_PATH):
csv_path = os.path.join(housing_path, "housing.csv")
return pd.read_csv(csv_path) # 加载数据
housing = load_housing_data()
housing.head()

1 可视化
import seaborn as sns
sns.set() # 设置/重设美学参数
sns.pairplot(housing, height=2) # 散点图矩阵

2 相关分析
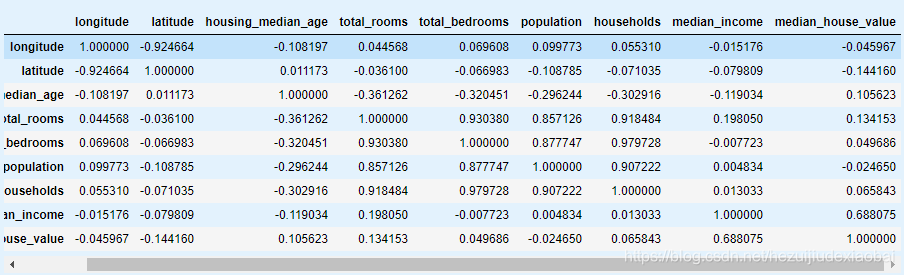
housing.corr() # 相关阵
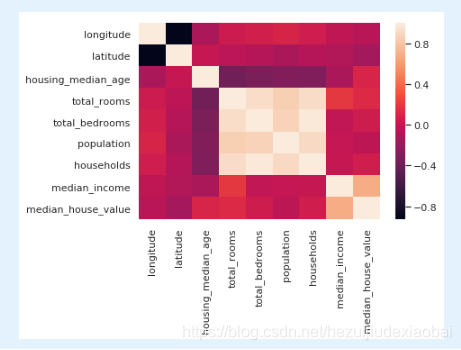
R = housing.corr()
sns.heatmap(R)
3 回归建模
housing = housing.dropna() # 去除缺失值NaN
import statsmodels.api as sm
features = list(housing) # 提取列名
features.remove('median_house_value')
features.remove('ocean_proximity') # 非数值类型
labels = ['median_house_value']
X = sm.add_constant(housing[features]) # 特征(添加一列1)
y = housing['median_house_value'] # 标签
model = sm.OLS(y, X)
result = model.fit()
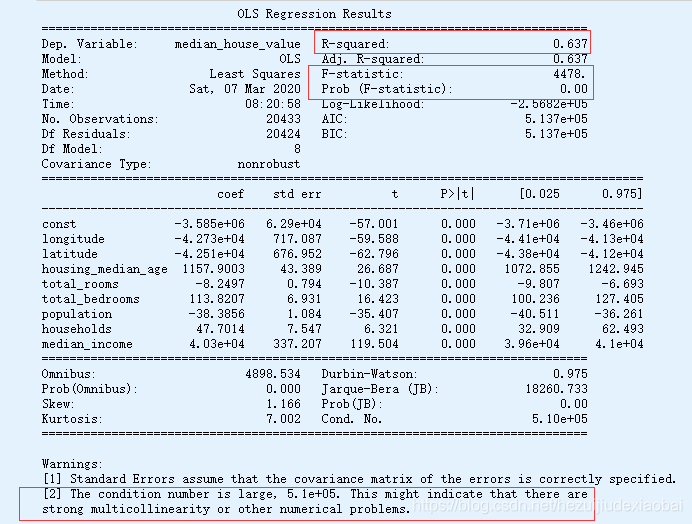
3.1 参数估计
result.params

print(result.summary())
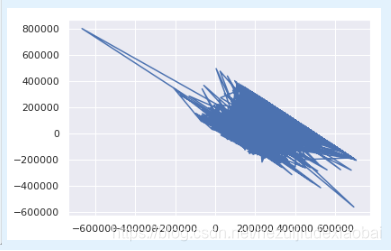
3.2 残差图
import matplotlib.pyplot as plt
plt.plot(result.predict(), result.resid)
4 使用Sklean做回归
4.1 建模
from sklearn import linear_model
from sklearn.model_selection import train_test_split
# 随机产生训练集&测试集
trainSet, testSet = train_test_split(housing, test_size=0.2, random_state=2020)
# 回归建模
model = linear_model.LinearRegression()
model.fit(trainSet[features], trainSet[labels])

4.2 建模结果
model.coef_

model.intercept_

4.3 评估
均方误差
import numpy as np
np.mean((model.predict(testSet[features]) - testSet[labels])**2)
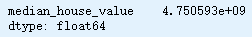
决定系数 R 2 R^2 R2
model.score(testSet[features], testSet[labels])

模型表现超级差
未完待续……



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









