







 本教程详细讲解了一套完整的数据科学竞赛流程,以泰坦尼克号生存预测为例,涵盖数据预处理、特征构造、模型建立及优化。通过编码、数据清洗、逻辑回归模型建立、模型特征重要性检测等步骤,教你如何提高预测分数。
本教程详细讲解了一套完整的数据科学竞赛流程,以泰坦尼克号生存预测为例,涵盖数据预处理、特征构造、模型建立及优化。通过编码、数据清洗、逻辑回归模型建立、模型特征重要性检测等步骤,教你如何提高预测分数。
33题实战“泰坦尼克号生存预测”全流程
点击以上链接👆 不用配置环境,直接在线运行
大家好,此次的教程基于泰坦尼克号生存预测的问题,带大家完整的走完一整套数据科学竞赛的流程。并且相关数据集中,我们特地搞来了预测的答案(ground_truth),让大家在学习的过程中,可以实时的感受每一步对于最终线上得分的影响。
参考资料&教程:
零、准备工作
这部分包含导入库、导入数据、理解数据
导入必要的库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
1.导入数据,并查看数据的形状
train = pd.read_csv('/home/kesci/input/titanic_ans7798/train.csv')#训练集
test = pd.read_csv('/home/kesci/input/titanic_ans7798/test.csv')#测试集
train.shape, test.shape
((891, 12), (418, 11))
2.查看数据的细节:查看数据的头5行,查看数据缺失情况
train.head()
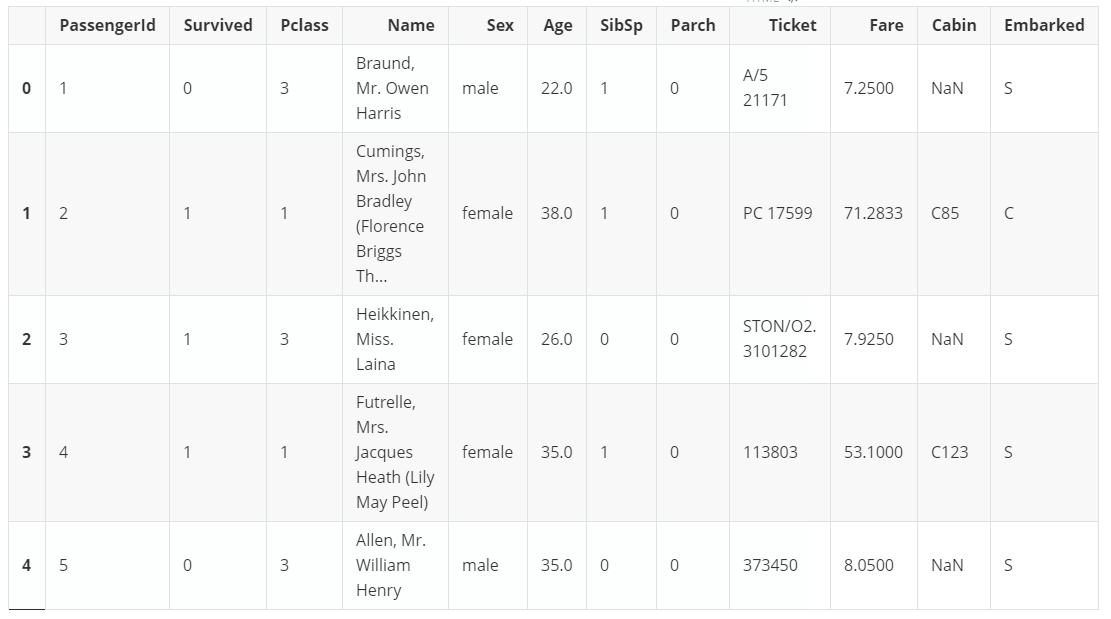
train.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
PassengerId 891 non-null int64
Survived 891 non-null int64
Pclass 891 non-null int64
Name 891 non-null object
Sex 891 non-null object
Age 714 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Ticket 891 non-null object
Fare 891 non-null float64
Cabin 204 non-null object
Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.6+ KB
test.head()
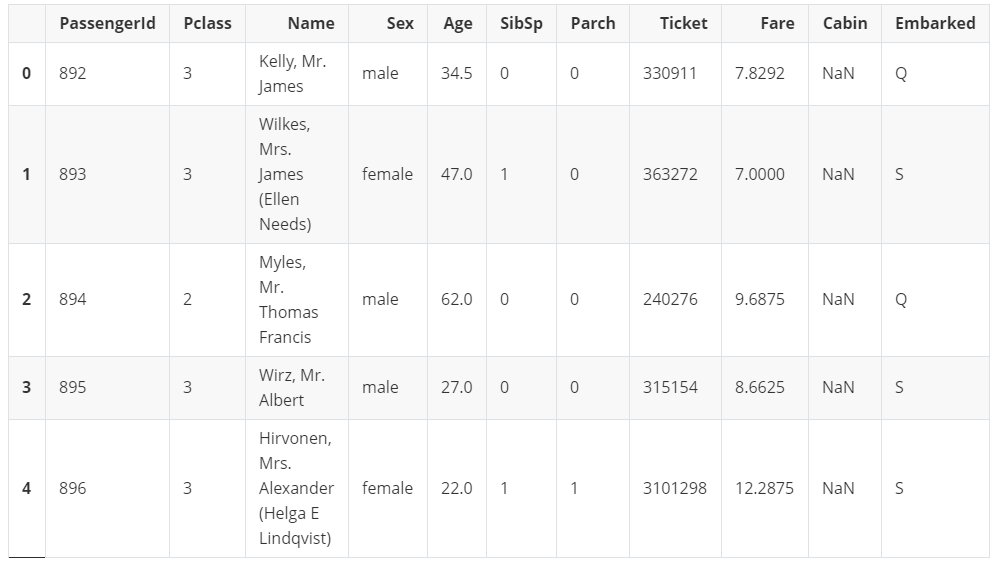
test.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 418 entries, 0 to 417
Data columns (total 11 columns):
PassengerId 418 non-null int64
Pclass 418 non-null int64
Name 418 non-null object
Sex 418 non-null object
Age 332 non-null float64
SibSp 418 non-null int64
Parch 418 non-null int64
Ticket 418 non-null object
Fare 417 non-null float64
Cabin 91 non-null object
Embarked 418 non-null object
dtypes: float64(2), int64(4), object(5)
memory usage: 36.0+ KB
3.将训练集和测试集纵向连接,方便统一清洗
dataset = train.append(test,sort=False)#合并后的数据,方便一起清洗
dataset.head()
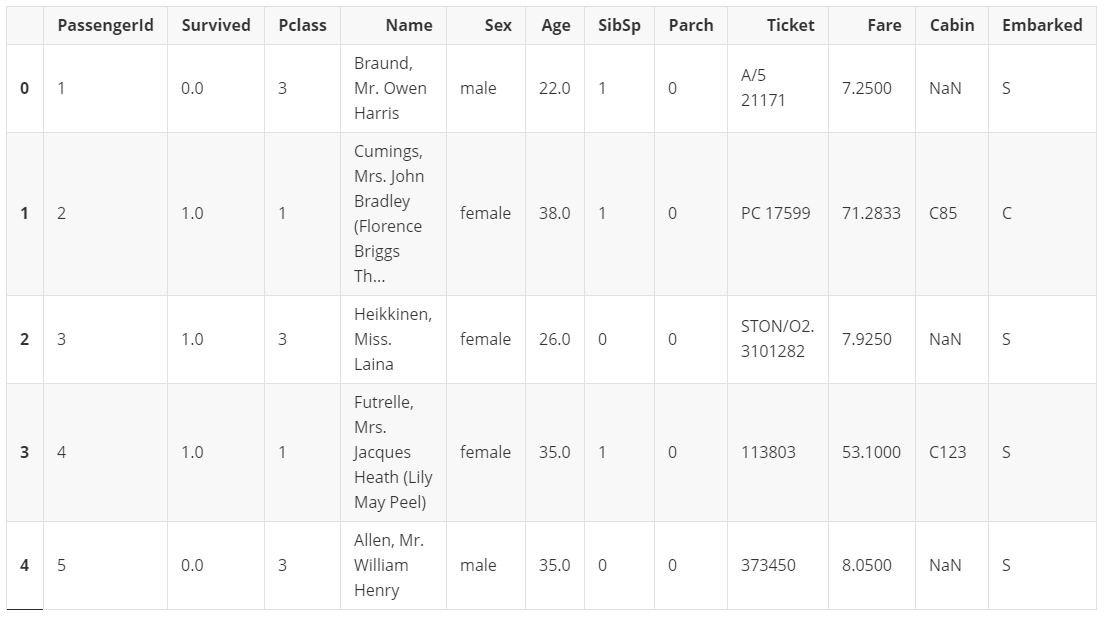
dataset.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 1309 entries, 0 to 417
Data columns (total 12 columns):
PassengerId 1309 non-null int64
Survived 891 non-null float64
Pclass 1309 non-null int64
Name 1309 non-null object
Sex 1309 non-null object
Age 1046 non-null float64
SibSp 1309 non-null int64
Parch 1309 non-null int64
Ticket 1309 non-null object
Fare 1308 non-null float64
Cabin 295 non-null object
Embarked 1307 non-null object
dtypes: float64(3), int64(4), object(5)
memory usage: 132.9+ KB
一、数据预处理
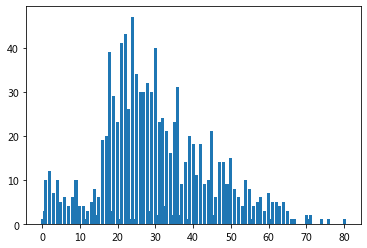
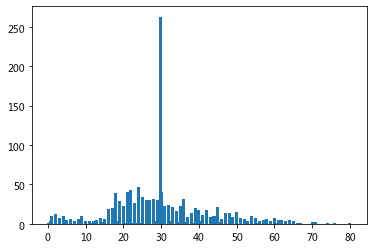
4.Age字段指的是年龄,康康现有数据分布
age = dataset.Age.value_counts()
plt.bar(age.index,age.values)
<BarContainer object of 98 artists>
5.没啥问题,将Age的缺失值充为平均值
dataset.Age = dataset.Age.fillna(dataset.Age.mean())
## 检查一下
age = dataset.Age.value_counts()
plt.bar(age.index,age.values)
6.Cabin字段指的是座位号,康康现有数据分布
cabin = dataset.Cabin.value_counts()
plt.bar(cabin.index,cabin.values)
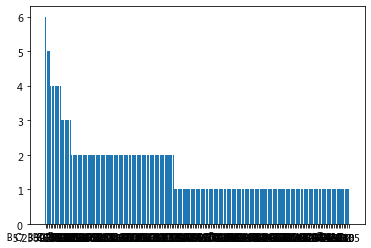
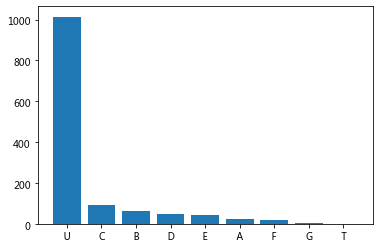
7.密密麻麻啥都看不清,而且每个值只有一个两个,进一步查看原始数据
发现是仓位+座位号的格式,所以将仓位单独做一列,并且把缺失值填充为U
dataset.Cabin = dataset.Cabin.fillna('U') ## 先填充,否则apply无法处理N/A
dataset.Cabin=dataset.Cabin.apply(lambda x: x[0])
## 检查一下
cabin = dataset.Cabin.value_counts()
plt.bar(cabin.index,cabin.values)
8.Embarked字段指的是登船码头,缺失值少,但是还得给他填上,老规矩,先看看
embarked = dataset.Embarked.value_counts()
plt.bar(embarked.index,embarked.values)
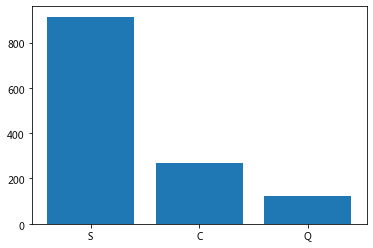
9.就3个值,S最多,就把空白值填充为S
dataset.Embarked  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 372
372

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









