



 本文讨论了在ES和MySQL中处理大量数据时的深度分页问题,提供了三种解决方案:修改分页深度、滚动查询和使用search_after排序。特别关注了避免内存溢出和提高查询效率的方法。
本文讨论了在ES和MySQL中处理大量数据时的深度分页问题,提供了三种解决方案:修改分页深度、滚动查询和使用search_after排序。特别关注了避免内存溢出和提高查询效率的方法。
文章目录
es 深度分页
es 深度分页问题,有点忘记了,这里记录一下
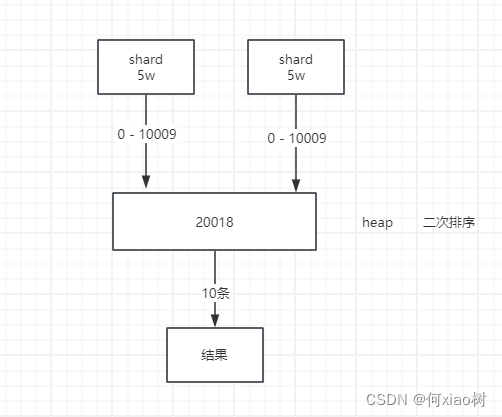
当索引库中有
10w条数据,比如是商品数据;用户就是要查在1w到后10条数据,怎么查询。
- es查询是从各个分片中取出前
1w到后10条数据,然后进行数据汇总,在对汇总的数据进行排序后,取出1w到后10条数据- 这个汇总后的数据排序是在
heap内存中进行的,如果数据量过大的话,可能会导致OOM- 频繁的深度分页查询,会导致频繁的
FGC,导致服务卡顿
但是嘿,我就是查怎么办?
- 默认es指定分页深度
max_result_window是10000条,超过这个数据量默认是不允许查询的。
方法一: 修改该索引的,分页深度;比如修改为 10w条
- 有风险,容易溢出、或效率低下
## 修改分页深度
PUT goods/_settings
{
"max_result_window":100000
}
# 查数据
GET goods/_search
{
"from" : 10000 , "size" : 10
}

方法二:滚动查询一部分数据一部分的查,无需修改分页深度
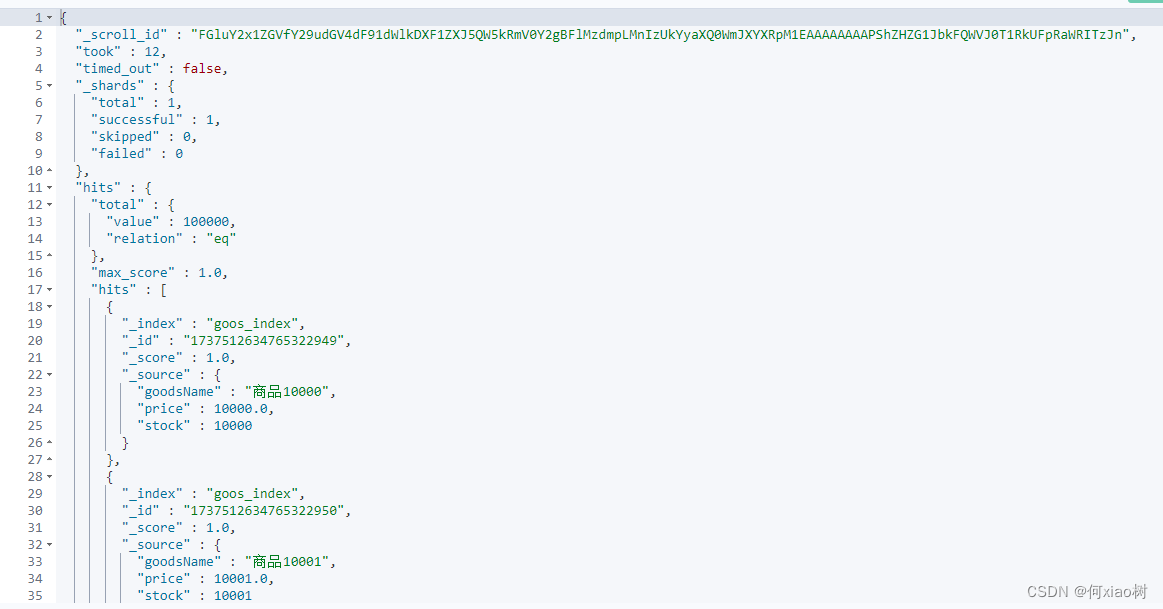
scroll 查询是可以避免在处理大量数据时,将所有结果一次性加载到内存中所带来的内存压力。通过使用scroll,只有当前批次的结果需要被加载到内存中,而不是整个结果.- 第一次
scroll会将结果保存快照,存活时间 1m(分钟)- 在第二次滚动,会根据当前
scroll_id定位到快照,查询下一批次的结果,然后的在程序里取出1w~10009- 但是
scroll查询会占用Elasticsearch的资源,因为它需要维护结果集的快照Scrolls,默认 滚动次数限制在500
GET goods/_search?scroll=1m
{
"size" : 10000
}
POST /_search/scroll
{
"scroll" : "1m",
"scroll_id" : "${上次查询的滚动id}"
}
方法3:
search_after排序唯一,根据上次返回排序数组值,当做 search_after请求参数
- 使用
search_after参数将第一次查询结果中最后一个文档的排序值作为起- es根据这个排序值,找到下一页的文档,并将最后一个文档的排序值记录下来
- 不支持向前搜索,只能向后执行
- 每次只能向后搜索1页数据
GET goods/_search
{
"sort": [
{
"price": {
"order": "asc"
}
}
],
"from" : 9990 , "size" : 10
}
GET goos_index/_search
{
"sort": [
{
"price": {
"order": "asc"
}
}
],
"search_after": [
9999.0
]
}

MySQL 深度分页
2000w条记录的表,需要查询第100w、1000w以及后10条数据
-- 取1000w行数据
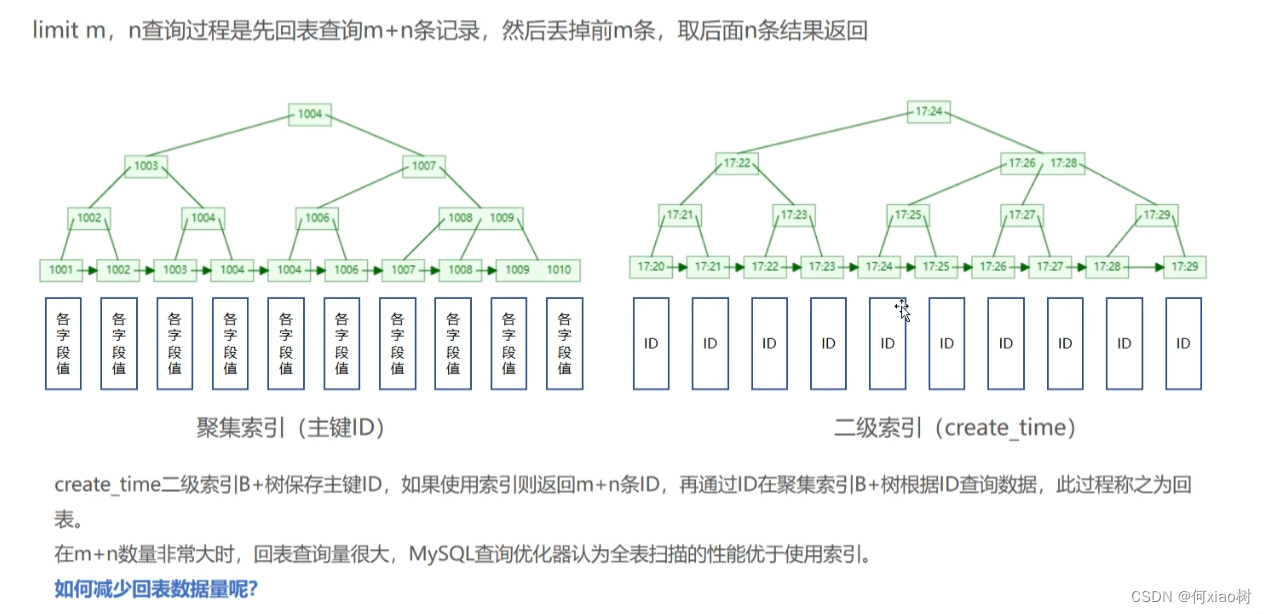
select * from person order by p.create_time desc limit 10000000,100
select *查询时,如果以 创建时间建一个索引,idx_create_time ,因为没有覆盖索引,所以需要回表,要回表1000w次
- 所以查询很慢,我们需要避免回表。
- 借鉴一下图 ↓
先用 覆盖索引的子查询,缩短查询时间范围
select p.* from person p
where p.create_time <= (select create_time from person t order by t.create_time desc limit 10000000,1)
order by p.create_time desc limit 10
悲催的面试 /(ㄒoㄒ)/~~


















 2642
2642

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









