




Gemini 2.5 Pro 上线了,早上打开Gemini已经开到了对应的模型:2.5 Pro(experimental)。
每次Gemini发布一个模型,OpenAI就会发布一个爆炸功能,这次的GPT-4o的图像生成(大家想要体验GPT-4o的可以参考本文:littlemagic8.github.io/2025/03/26/chatgpt4o-image-generation/),
让Gemini黯然失色,但是大家在竞技场的积分(目前Gemini-2.5-Pro排名第一)还是展示出了对Gemini的喜爱,毕竟是真的有实力的模型!
接下来,我们先介绍Gemini-2.5-Pro模型,然后教大家怎么白嫖一个月的Gemini的会员,然后先给大家体验一把这个牛逼的推理模型,对于实现一个双缓冲日志的效果生成的结果,我真的很满意,大家一起跟我来看看吧!大家自己可以去看看用来code review、用来病例诊断的效果如何,在评论区交流一下吧~
Gemini-2.5-Pro介绍
在官方的介绍中,Gemini 2.5:我们最智能的 AI 模型,Gemini 2.5 是一种思维模型,旨在解决日益复杂的问题。Google的第一个 2.5 模型 Gemini 2.5 Pro Experimental 在常见基准测试中遥遥领先,并展示了强大的推理和代码能力。
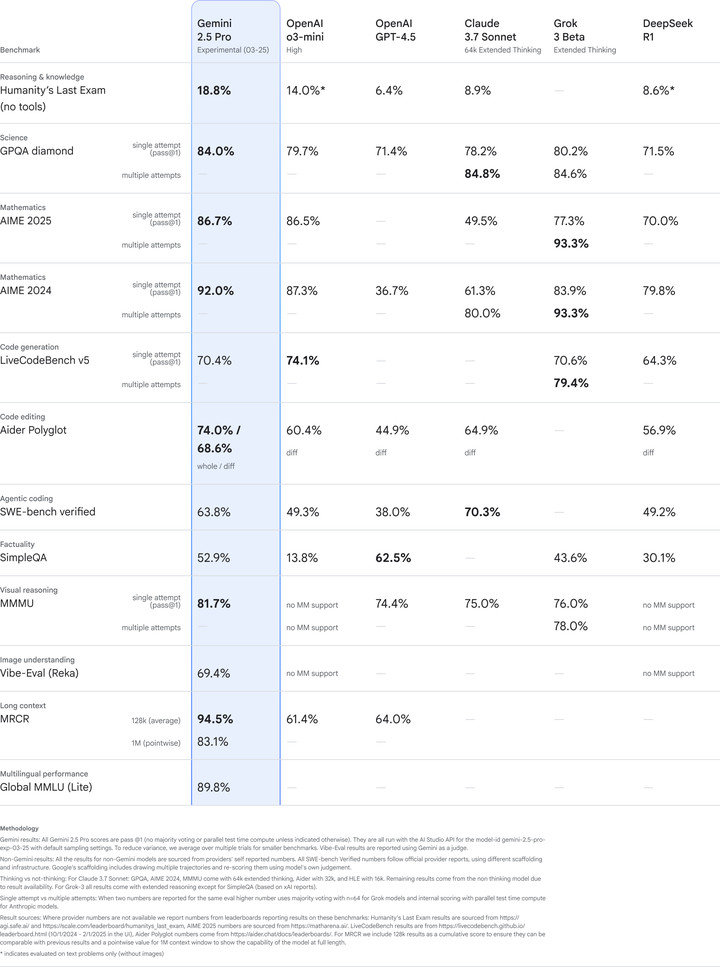
Gemini 2.5 Pro Experimental 是我们最先进的复杂任务模型。它在LMArena排行榜(衡量人类偏好)上遥遥领先,表明该模型具有出色的性能和高品质的风格。
2.5 Pro 还表现出强大的推理和编码能力,在常见的编码、数学和科学基准测试中处于领先地位。
Gemini 2.5 Pro 现已在Google AI Studio和Gemini app中面向 Gemini Advanced 用户推出,并将很快在Vertex AI中推出。我们还将在未来几周内推出定价,使人们能够使用具有更高速率限制的 2.5 Pro 进行大规模生产使用。
今天我也去体验了一把2.5 Pro,真的不错,就像雇佣了一个Google内部的员工来完成代码,还是老规矩,先教大家白嫖免费一个月的Gemini Advanced。然后再给出我们的实际例子!
如何如何免费使用Gemini-2.5-Pro模型?
关于Gemini 2.5 Pro 这个模型,需要是Gemini Advanced会员才能使用,如果你是新用户或者老用户,都可以参考下面的教程。
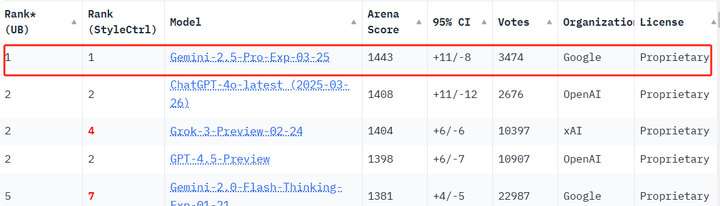
而且在竞技场,Gemini 2.5 Pro 的跑分是第一!超越了马斯克全球最聪明的模型Grok3的1404分。
Gemini Advanced 订阅使用教程
Gemini对于新用户,是可以免费获取Gemini Advanced一个月的,具体的条件需要:
新用户 + 绑定银行卡信息
针对国内用户常见的境外支付壁垒(双币卡支付失败等问题),推荐采用Visa 或 Mastercard 类型的信用卡,但是这这种卡大多数用户都没有。
就只剩“虚拟信用卡”这一条了,大家别看虚拟这两个字,其实虚拟信用卡的别名是 “不记名预充值卡”,也就是不记录这种卡是谁的,你充多少钱就可以花多少钱,这种也是国外安全合规的支付方式。
Master虚拟卡官网注册:Go Wildcard虚拟卡
这个虚拟卡,我已经用了2年了。
先注册一个新的谷歌用户,成功登录后,就可以看到这几个[Gemini Advanced 升级/try ]标志,点击其中一个就行。

就会进入升级Gemini Advanced 的页面,页面有这个显示,就是代表你可以免费获取一个月的Gemini Advanced。

接下来,我们去申请注册一张Master虚拟卡来进行绑卡,然后再取消即可。
1、申请之后,可以选择需要订阅的服务:Google。
Master虚拟卡申请:Go Wildcard虚拟卡
2、充值
接着使用支付宝给Master虚拟卡充值对应的金额,如:5美金。你是新用户,充值5美金就行,绑卡之后,再把5美金提现回支付就行。
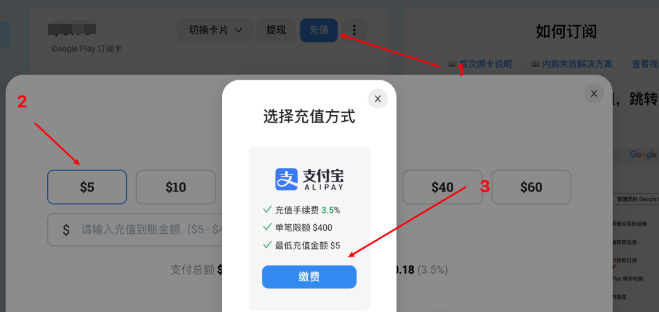
完成之后,确保Master虚拟卡有余额,就可以进行绑卡,绑卡成功之后就可以获取到一个月的Gemini Advanced。
3、Gemini中添加卡片
回到Gemini页面,点击开始订阅之后,就可以添加你的卡,这个卡你就可以用你刚刚申请的Master虚拟卡。
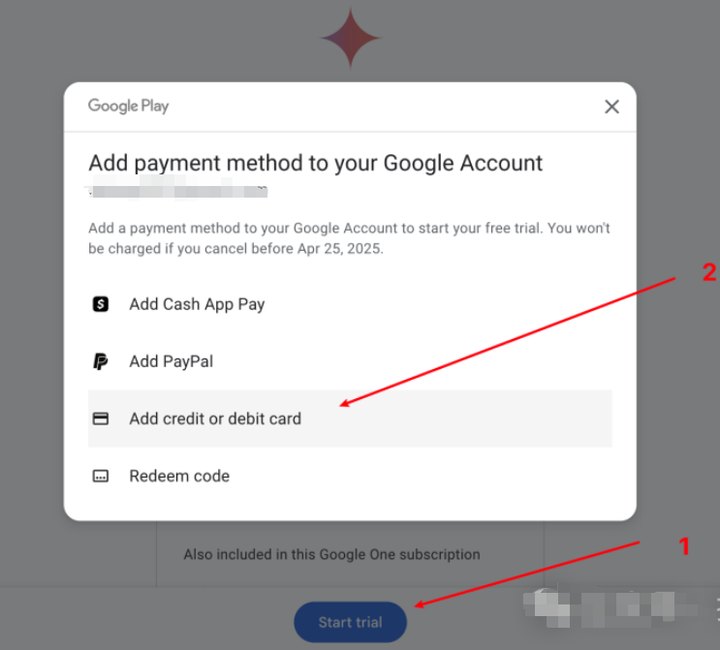
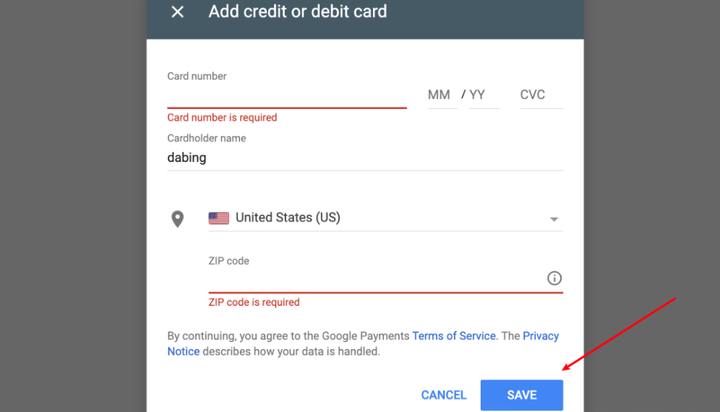
4、绑定卡片信息
这些信息都在Master虚拟卡上面,直接把虚拟卡的信息全部填入到这里面,然后点击保存就行。
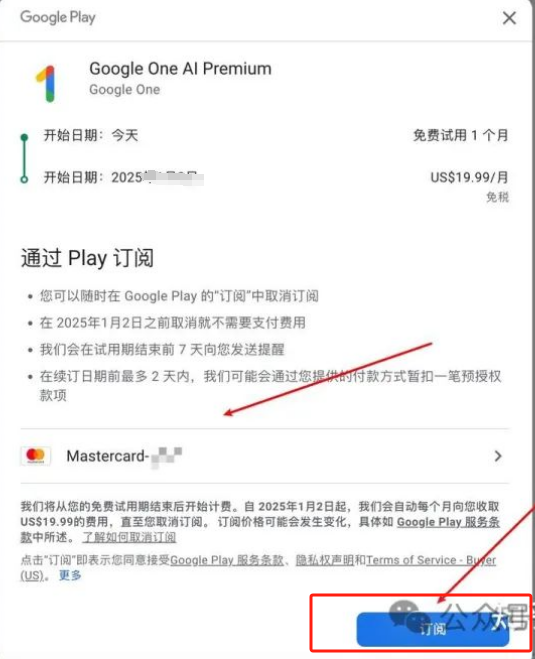
5、订阅Gemini Advanced服务
保存之后,就可以选择你的卡号点击【订阅】,就可以开通免费使用Gemini Advanced Pro 服务啦。
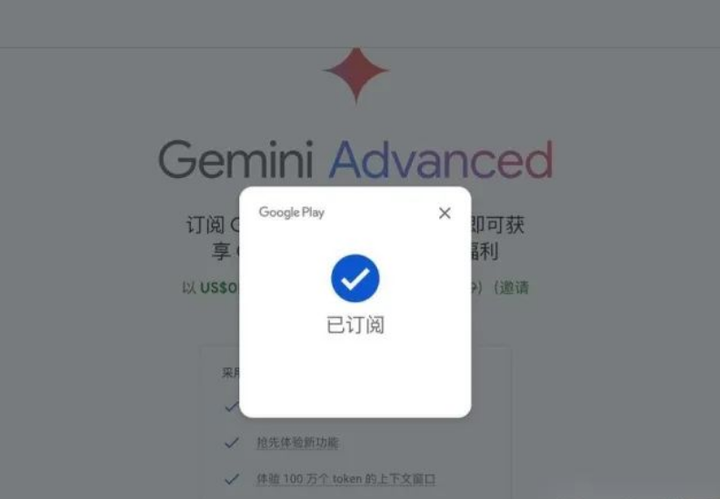
6、取消自动续费订阅,避免扣费失败等情况
订阅成功之后,下面我们需要进行一个取消自动续费订阅,避免下个月自动扣费。
让我们回到 Gemini的【首页】,点击【设置】再点击【管理订阅】。
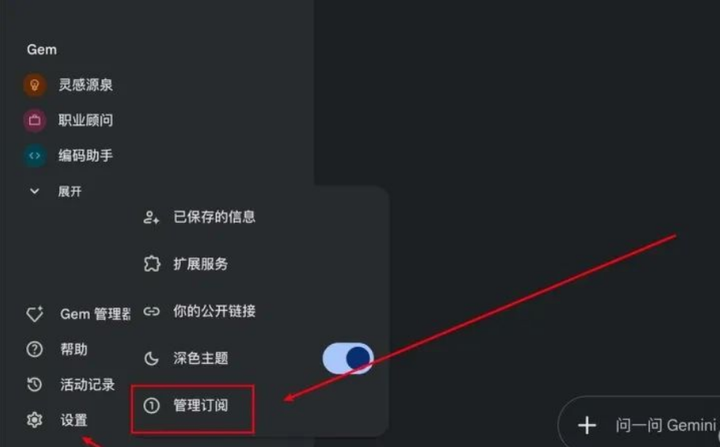
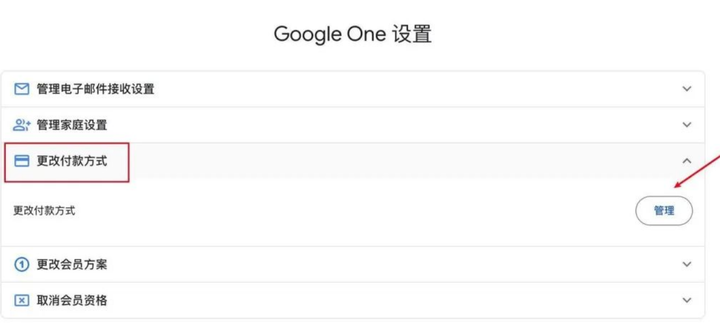
在Google One上选择【更改付款方式】,点击【管理】,就会显示你的绑定信息,接着再点击订阅订阅信息的【管理】。

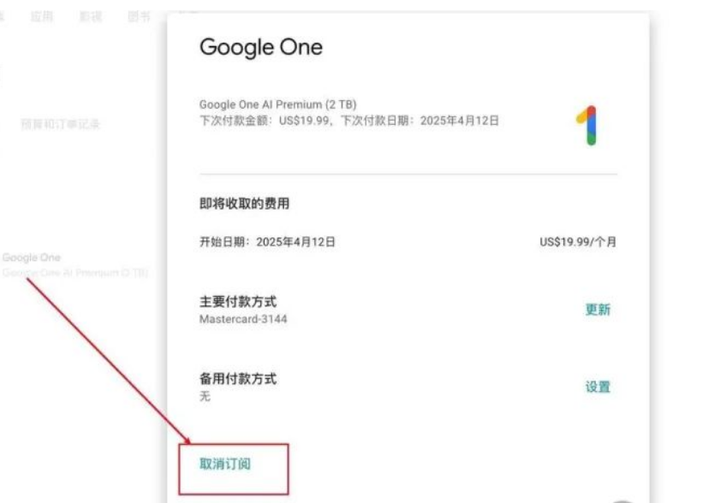
然后会弹出信息,点击【取消订阅】之后进行一个确认,就可以成功取消掉啦。
现在就完成了,熟悉操作的话,大概几分钟就可以完成。现在就可以使用Gemini 2.5 Pro这个模型啦
实例:双缓冲日志实现并测试
prompt:你是一个C语言专家工程师,请基于c语言实现一个双缓冲日志文件,用于日常系统日志打印落盘同时使用google Test书写UT详细测试日志实现的性能和功能正确性
UT测试结果
单线程的速率是:540540/s

多线程的速率是:465116/s

log代码实现:
项目文件结构
.
├── CMakeLists.txt
├── include
│ └── logger.h
├── src
│ └── logger.c
└── test
└── logger_test.cc
更多详细代码详细可以参考下面:Gemini-2.5-Pro推理模型体验之后表示绝绝子像Google员工在给你实现代码一样,如何免费订阅使用Gemini-2.5-Pro模型体验一个月的Gemini Advanced Pro会员?如何使用Gemini-2.5-Pro
Okay, here is a C implementation of a double-buffered logging system with Google Test unit tests for functionality and performance.
**1. Project Structure:**
```
.
├── CMakeLists.txt
├── include
│ └── logger.h
├── src
│ └── logger.c
└── test
└── logger_test.cc
```
**2. Header File (`include/logger.h`)**
```c
#ifndef LOGGER_H
#define LOGGER_H
#include <stdarg.h>
#include <stdbool.h>
#include <stddef.h> // For size_t
// --- Configuration ---
#define LOG_BUFFER_SIZE (1024 * 64) // Size of each buffer (e.g., 64KB)
#define MAX_LOG_MSG_SIZE 1024 // Max size of a single formatted log message
#define LOG_FILE_DEFAULT "app.log" // Default log file name
// --- Log Levels ---
typedef enum {
LOG_DEBUG,
LOG_INFO,
LOG_WARN,
LOG_ERROR,
LOG_FATAL
} LogLevel;
/**
* @brief Initializes the double-buffered logging system.
*
* Must be called before any other log functions. Creates the background
* flushing thread.
*
* @param filename The path to the log file. If NULL, uses LOG_FILE_DEFAULT.
* @return 0 on success,  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 8100
8100


 到【灌水乐园】发言
到【灌水乐园】发言








