




数据就是最好的描述和证明,接下来,我们综合看看OpenAI和Google家的Gemini的模型对比结果如何
综合对比
综合评分如下:
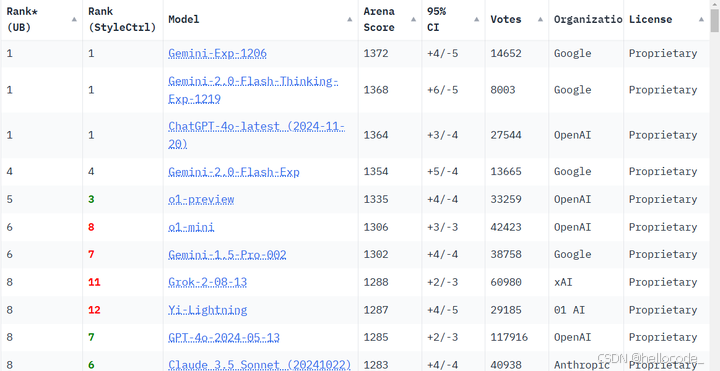
从图上可以看到,12月22号之前还是Gemini的模型占领第一,OpenAI的ChatGPT-4o紧跟其后,总比比分稍逊Gemini。
如何订阅升级ChatGPT会员?
PS: 因为笔者平时使用最多的是ChatGPT和Claude,需要升级ChatGPTPlus/Pro会员的童鞋可以参考:ChatGPT订阅升级教程
稳定性
接下来我们再看看各个模型的稳定性对比
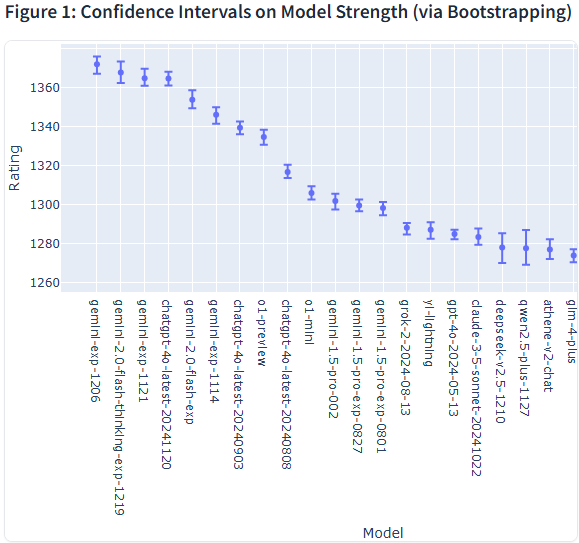
上图图标说明:模型强度的置信区间(Confidence Interval, CI)指的是模型评分的统计范围,用于表明在重复测评中,模型真实表现可能落在哪个区间。
具体来说:上下限范围:置信区间通常以“±某值”表示,比如95%置信区间为+5.84 / -6.00,表示实际分数有95%的概率落在这个范围内。
用途:它反映了模型评分的稳定性。如果置信区间较窄,说明评分更稳定、误差更小
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5534
5534

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









