







One-Shot-Voice-Cloning: 革命性的单样本声音克隆技术
在人工智能和语音技术飞速发展的今天,声音克隆技术正在成为一个备受关注的研究热点。其中,One-Shot-Voice-Cloning项目凭借其创新的技术方案和出色的性能,正在引领这一领域的发展。本文将深入介绍这个基于Unet-TTS的单样本声音克隆项目,探讨其核心技术、应用前景以及对语音合成领域的深远影响。
什么是One-Shot-Voice-Cloning?
One-Shot-Voice-Cloning是由CMsmartvoice团队开发的一个开源项目,旨在实现高质量的单样本声音克隆。所谓单样本声音克隆,是指仅需要一段很短的目标音频(通常只需几秒钟),就能学习并模仿该音频的说话人声音特征,进而合成任意文本的语音。这项技术的核心在于它能够快速捕捉说话人的声音特征,并将其应用于新的语音合成中,实现声音的精准克隆。
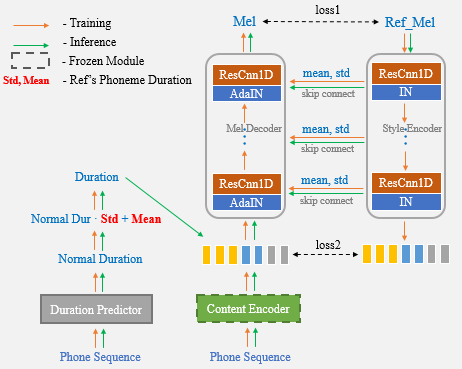
核心技术:Unet-TTS
One-Shot-Voice-Cloning的核心技术基于Unet-TTS模型。Unet-TTS是一种创新的语音合成模型,它借鉴了图像处理领域广泛使用的U-Net网络结构,并将其应用于语音合成任务中。这种结构能够有效地捕捉音频信号的多尺度特征,从而实现更加精细和自然的语音合成。
Unet-TTS模型的主要优势包括:
-
高效的特征提取:U-Net结构能够同时捕捉音频
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 454
454

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









