







K-NN 算法(k-Nearest Neighbor),也叫 k 近邻算法,可按如下三步学习:
1、了解k-NN的算法思想及原理
2、最后用我们熟悉的Python代码实现
一、了解k-NN的算法思想
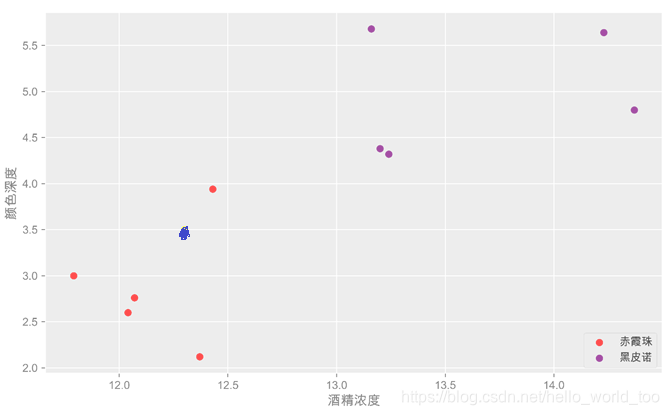
上面有红色和紫色两个类别,离蓝色点最近的3个点都是红点,所以红点和紫色类别的投票数是3:0,红色取胜,所以黄色点属于红色,也就是新的一杯属于「赤霞珠」
(一)算法原理
这就是k-近邻算法,它的本质是通过距离判断两个样本是否相似,如果距离够近就认为他们足够相似属于同一类别。
当然只对比一个样本是不够的,误差会很大,我们需要找到离其最近的k个样本,并将这些样本称之为「近邻」(nearest neighbor)。对这k个近邻,查看它们的都属于何种类别(这些类别我们称作「标签」(labels))。
然后根据“少数服从多数,一点算一票”原则进行判断,数量最多的的标签类别就是新样本的标签类别。其中涉及到的原理是“越相近越相似”,这也是KNN的基本假设。
(二)算法模型
可以看到k-近邻算法就是通过距离来解决分类问题。这里我们解决的二分类问题,整个算法结构如下:
- 算距离
给定测试对象 𝐼𝑡𝑒𝑚,计算它与训练集中每个对象的距离。
依据公式计算 𝐼𝑡𝑒𝑚 与 𝐷_1,𝐷_2, ……𝐷_𝑗之间的相似度,得到𝑆𝑖𝑚(𝐼𝑡𝑒𝑚,𝐷_1 ), 𝑆𝑖𝑚(𝐼𝑡𝑒𝑚,𝐷_2 ), 𝑆𝑖𝑚(𝐼𝑡𝑒𝑚,𝐷_𝑗 ). - 找邻居
圈定距离最近的k个训练对象,作为测试对象的近邻。
将𝑆𝑖𝑚(𝐼𝑡𝑒𝑚,𝐷_1 ), 𝑆𝑖𝑚(𝐼𝑡𝑒𝑚,𝐷_2 ), 𝑆𝑖𝑚(𝐼𝑡𝑒𝑚,𝐷_𝑗 )排序,若是超过相似度阈值𝑡,则放入邻居集合𝑁𝑁. - 做分类
根据这k个近邻归属的主要类别,来对测试对象进行分类。
自邻居集合𝑁𝑁中取出前k名,查看它们的标签,对这k个点的标签求和,以多数决,得到𝐼𝑡𝑒𝑚可能类别。
(三)模型中距离的确认
k-NN算法基本思是在对新的实例时,根据其 k 个最近邻的训练实例的类别,通过多数表决等方式进行预测。k-近邻法实际上利用了训练数据集对特征向量空间进行划分,并作为其分类的 “模型” 。
该算法的「距离」在二维坐标轴就表示两点之间的距离,计算距离的公式有很多,我们常用欧拉公式,即“欧氏距离”。回忆一下,一个平面直角坐标系上,如何计算两点之间的距离?一个立体直角坐标系上,又如何计算两点之间的距离?

二、Python代码实现
(一)简单的KNN举例
1、导入一些包
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.datasets import make_blobs
2、模拟数据
# 模拟出一些数据集出来
X, y = make_blobs(n_samples = 50, # 要生成多少个样本
n_features= 2,
centers = [[0,0], [1,1], [1,-1]], # 每个中心点的位置
cluster_std = [0.5, 0.5, 0.5], # 每个类别的点的离散程度
random_state = 42 # 随机数种子
)
plt.scatter(X[:, 0], X[:, 1], c = y) # 将每个样本点的颜色标上去
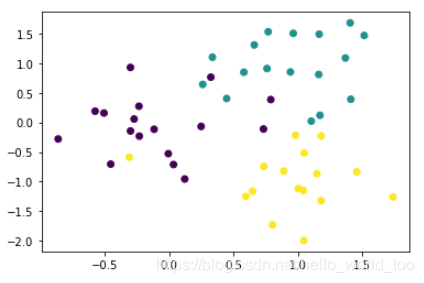
3、计算测试点到每一个点的距离的平方
# 计算每一个点到测试点距离的平方
Xtest = [0.6, -0.1]
d2 = np.power(X - Xtest, 2).sum(axis = 1) #2表示平方
d2
#将计算的举例转化为DateFrame
# 把计算出来的距离与标签拼接起来
data = pd.DataFrame(X, columns = ['X1', 'X2']) #转成DataFrame的格式
data['label'] = y #添加y的值作为label列
data['distance_2'] = d2 #添加d2的值作为d2distance_2列
data.head()
4、确认K值,并按距离排序,选取前K的标签
#确认前k个点
k = 5
#开始投票,根据distance_2的值进行排序,取前K位的label的值;然后再对前K为的label类型进行计数,选取最多那个label类型
cloest_label = data.sort_values(by = 'distance_2').iloc[:k, :]['label']
final_result = cloest_label.value_counts().index[0]
final_result
5、封装成函数
# 将上述分步执行的,封装成一个函数
def knn_frank(X, y, Xtest, k):
d2 = np.power(X - Xtest, 2).sum(axis = 1) #求距离的平方
data = pd.DataFrame(X) #转成DateFrame格式
data['label'] = y #将y值作为label列添加
data['distance_2'] = d2 #将d2值作为distance_2列添加
cloest_label = data.sort_values(by = 'distance_2').iloc[:k, :]['label'] #根据distance_2的值进行排序,取前K位的label的值
final_result = cloest_label.value_counts().index[0] #对前K为的label类型进行计数,选取最多那个label类型
return final_result
#测试
knn_frank(X = X, y = y, Xtest = [1, -1], k = 3)
#输出2(类别判断)
~~~
#### 6、对训练集数据标签进行预测
#评估模型,写了一个小函数,将训练集,依次来进行预测,观测这些数据集的真实的标签和预测标签
#这样的话,可以尝试来判断模型的好坏
y_pred = []
for i in X:
y_pred.append(knn_frank(X = X, y = y, Xtest = i, k = 3))
print(y_pred," ")
#查看模型的表现
data = pd.DataFrame(X, columns = [‘X1’, ‘X2’])
data[‘Y_True’] = y
data[‘Y_Pred’] = y_pred
data.head()
print((data[‘Y_True’] == data[‘Y_Pred’]).mean())
~~
(二)sklearn 掉包实现
#sklearn 实现
from sklearn.neighbors import KNeighborsClassifier
#实例化, 我是需要设置好超参数
clf = KNeighborsClassifier(n_neighbors = 1)
#训练数据
clf.fit(X, y)
#学习好之后,重要的信息就全部存到clf,这些信息描述的是X和Y之间的规律
clf.score(X, y)
这是没有做任何调整情况下的直接调包,相对比较简单,接下来从三个方面对模型进行优化
- 交叉验证
- 归一化出来
- 增加权重比例
1、交叉验证
交叉验证掉包,对训练集进行5等分
#交叉验证
from sklearn.model_selection import cross_val_score
#实例化一个模型
clf = KNeighborsClassifier(n_neighbors = 4)
cv_score = cross_val_score(clf , X_train , y_train ,cv =5)#cv为对训练集分成5等份进行交叉验证
cv_score.mean(), cv_score.std() #计算5个等分下的拟合度均值和标准差
# 均值:查看模型的平均效果
kange = range(1,51)
cv_mean = []
cv_std = []
# 绘制带交叉验证的学习曲线
for i in kange:
clf = KNeighborsClassifier(n_neighbors = i)
cv_score = cross_val_score(clf ,X_train , y_train ,cv = 5)
cv_mean.append(cv_score.mean())
cv_std.append(cv_score.std())
cv_mean = np.array(cv_mean)
cv_std = np.array(cv_std)
# 绘制学习曲线
plt.plot(kange, cv_mean ,color = "k")
plt.plot(kange, cv_mean+0.5*cv_std , c = "red" ,linestyle = "--")
plt.plot(kange, cv_mean-0.8*cv_std , c = "red" ,linestyle = "--")
plt.show()
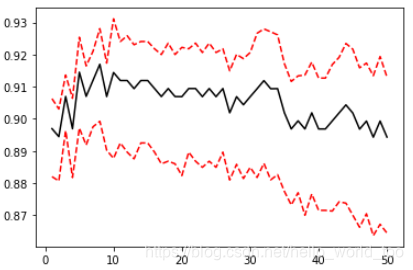
大致确认最优K值,将K值代入测试集进行验证
# 大致的确定了训练集下交叉验证所得到的最优的参数值
# 尝试,用最优的参数值来进行训练集的训练
# 给出最后测试集上的效果
# 如果测试集上的效果不怎么样,没办法,只能尝试对数据做处理,或者上更加好的算法
clf = KNeighborsClassifier(n_neighbors=8)
clf.fit(X_train , y_train)
clf.score(X_train , y_train) , clf.score(X_test , y_test)
(0.9346733668341709, 0.9649122807017544)
为什么要进行交叉验证?
- 确定了 k 之后,我们还能够发现一件事:每次运行的时候学习曲线都在变化,模型的效果时好时坏,这是为什么呢?
- 实际上,这是由于「训练集」和「测试集」的划分不同造成的。模型每次都使用不同的训练集进行训练,不同的测试集进行测试,自然也就会有不同的模型结果。在业务当中,我们的训练数据往往是已有的历史数据,但我们的测试数据却是新进入系统的一系列还没有标签的未知数据。我们的确追求模型的效果,追求的是模型在未知数据集上的效果,在陌生数据集上表现优秀的能力被称为泛化能力,即我们追求的是模型的泛化能力,只有在众多不同的训练集和测试集上都表现优秀,模型才是一个稳定的模型,模型才具有真正意义上的泛化能力
- 最标准,最严谨的交叉验证应该有三组数据:训练集、验证集和测试集。当我们获取一组数据后,先将数据集分成整体的训练集和测试集,然后我们把训练集放入交叉验证中,从训练集中分割更小的训练集(k-1份)和验证集(1份),此时我们返回的交叉验证结果其实是验证集上的结果。我们使用验证集寻找最佳参数,确认一个我们认为泛化能力最佳的模型,然后我们将这个模型使用在测试集上,观察模型的表现。
2、归一化处理
data2 = pd.DataFrame(X_train , columns= name)
data2.head()
# 先切分整体的数据集, 利用mms,学习训练集的信息, 用他们来转换训练集,转换测试集
# 可以避免之前所描述的信息的泄露
X_train, X_test, y_train, y_test = train_test_split(X, # array或者是DF
y, # 标签
test_size=0.3, # 切分出来的测试集的占比
random_state=210# 随机数种子
)
#实现归一化
from sklearn.preprocessing import MinMaxScaler
mms = MinMaxScaler()
mms = mms.fit(X_train)
x_train = mms.transform(X_train)
x_test = mms.transform(X_test)
##训练和结果一步导出
clf = KNeighborsClassifier(n_neighbors=4)
clf.fit(x_train ,y_train)
clf.score(x_train ,y_train) ,clf.score(x_test ,y_test)
(0.9824120603015075, 0.9590643274853801)
#查看不同K值下的拟合度变化
kange = range(1,51)
cv_mean = []
cv_std = []
for i in kange:
clf = KNeighborsClassifier(n_neighbors=i)
cv_score = cross_val_score(clf ,x_train ,y_train ,cv =5)
cv_mean.append(cv_score.mean())
cv_std.append(cv_score.std())
cv_mean = np.array(cv_mean)
cv_std = np.array(cv_std)
#绘制学习曲线
plt.plot(kange ,cv_mean ,color = "k")
plt.plot(kange ,cv_mean+0.5*cv_std ,c = "red" ,linestyle ="--")
plt.plot(kange ,cv_mean-0.5*cv_std ,c = "red" ,linestyle ="--")
plt.show()
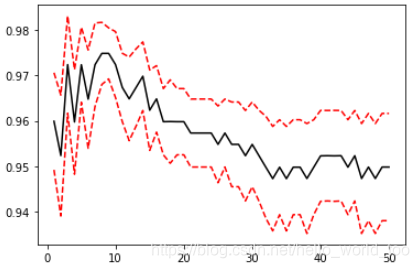
#确认最优K值下拟合度
clf = KNeighborsClassifier(n_neighbors=9)
clf.fit(x_train ,y_train)
clf.score(x_train ,y_train) ,clf.score(x_test ,y_test)
(0.9824120603015075, 0.9707602339181286)
为什么要进行归一化处理?
有的特征数值很大,有的特征数值很小,这种现象在机器学习中被称为 “量纲不统一”。NN是距离类模型,欧氏距离的计算公式中存在着特征上的平方和:

如果某个特征 𝑥_𝑖 的取值非常大,其他特征的取值和它比起来都不算什么,那距离的大小很大程度上都会由这个巨大特征 𝑥_𝑖 来决定,其他的特征之间的距离可能就无法对 𝑑(𝐴,𝐵) 的大小产生什么影响了,这种现象会让KNN这样的距离类模型的效果大打折扣。
3、增加权重比例
#根据前K个点到测试点的距离的远近进行权重区分
#加上权重
KNeighborsClassifier(n_neighbors=9 ,weights= "distance")
clf.fit(x_train ,y_train)
clf.score(x_train ,y_train) ,clf.score(x_test ,y_test)
#增加权重后不同K值下拟合度的变化
# 均值:查看模型的平均效果
krange = range(1, 51)
cv_mean = []
cv_std = []
# 绘制带交叉验证的学习曲线
for i in krange:
clf = KNeighborsClassifier(n_neighbors = i, weights = 'distance')
cv_score = cross_val_score(clf, x_train, y_train, cv = 5)
cv_mean.append(cv_score.mean())
cv_std.append(cv_score.std())
cv_mean = np.array(cv_mean)
cv_std = np.array(cv_std)
# 绘制学习曲线
plt.plot(krange, cv_mean, color = 'k')
plt.plot(krange, cv_mean + 0.5 * cv_std, c = 'red', linestyle = '--')
plt.plot(krange, cv_mean - 0.5 * cv_std, c = 'red', linestyle = '--')
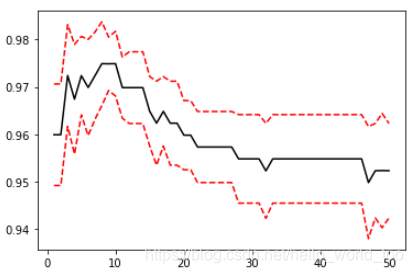
#确认最优K值下拟合度
# 算法带有惩罚的结果下,最好的k值是等于9
clf = KNeighborsClassifier(n_neighbors = 9, weights = 'distance')
clf.fit(x_train, y_train)
clf.score(x_train, y_train), clf.score(x_test, y_test)
为什么要增加权重?
- 对于原始分类模型而言,在选取最近的k个元素之后,将参考这些点的所属类别,并对其进行简单计数,而在计数的过程中这些点 “一点一票”,这些点每个点对分类目标点的分类过程中影响效力相同。
- 但这实际上是不公平的,就算是最近邻的k个点,每个点的分类目标点的距离仍然有远近之别,而近的点往往和目标分类点有更大的可能性属于同一类别(该假设也是KNN分类模型的基本假设)。因此,我们可以选择合适的惩罚因子,让入选的k个点在最终判别目标点属于某类别过程发挥的作用不相同,即让相对较远的点判别效力更弱,而相对较近的点判别效力更强。这一点也可以减少 KNN算法对 k 取值的敏感度。
- 关于惩罚因子的选取有很多种方法,最常用的就是根据每个最近邻 𝑥_𝑖 距离的不同对其作加权,加权方法为设置 𝑤_𝑖 权重,该权重计算公式为:
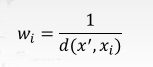

















 2351
2351

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









