




序
本文主要研究一下langchain4j的Advanced RAG
核心流程
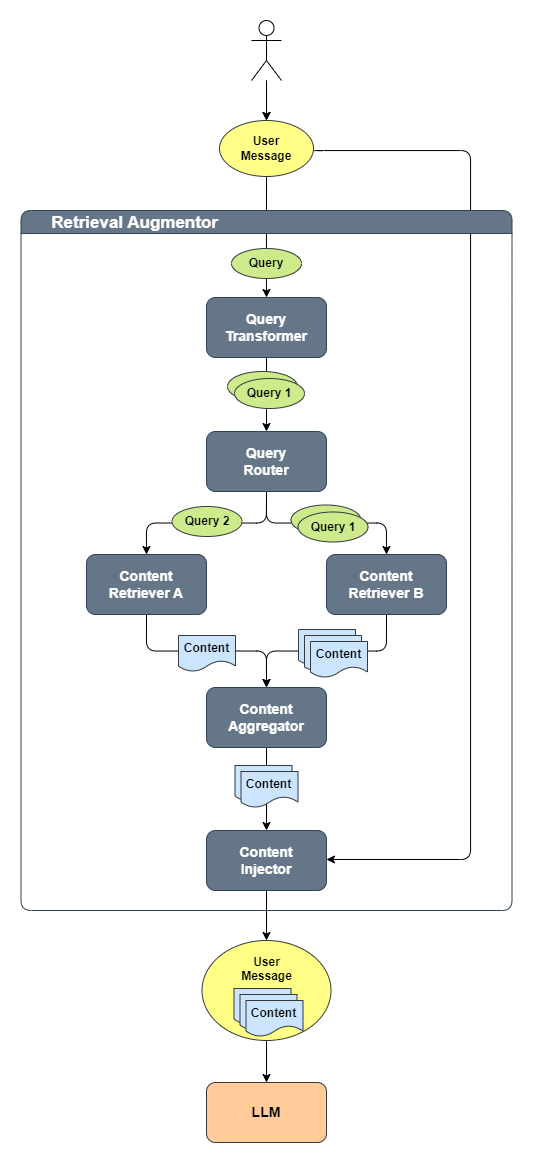
- 将UserMessage转换为一个原始的Query
- QueryTransformer将原始的Query转换为多个Query
- 每个Query通过QueryRouter被路由到一个或多个ContentRetriever
- 每个ContentRetriever检索对应Query相关的Content
- ContentAggregator将所有检索到的Content合并成一个最终排序的列表
- 这个内容列表被注入到原始的UserMessage中
- 最后包含原始查询以及注入的相关内容的UserMessage被发送到LLM
示例
public class _02_Advanced_RAG_with_Query_Routing_Example {
/**
* Please refer to {@link Naive_RAG_Example} for a basic context.
* <p>
* Advanced RAG in LangChain4j is described here: https://github.com/langchain4j/langchain4j/pull/538
* <p>
* This example showcases the implementation of a more advanced RAG application
* using a technique known as "query routing".
* <p>
* Often, private data is spread across multiple sources and formats.
* This might include internal company documentation on Confluence, your project's code in a Git repository,
* a relational database with user data, or a search engine with the products you sell, among others.
* In a RAG flow that utilizes data from multiple sources, you will likely have multiple
* {@link EmbeddingStore}s or {@link ContentRetriever}s.
* While you could route each user query to all available {@link ContentRetriever}s,
* this approach might be inefficient and counterproductive.
* <p>
* "Query routing" is the solution to this challenge. It involves directing a query to the most appropriate
* {@link ContentRetriever} (or several). Routing can be implemented in various ways:
* - Using rules (e.g., depending on the user's privileges, location, etc.).
* - Using keywords (e.g., if a query contains words X1, X2, X3, route it to {@link ContentRetriever} X, etc.).
* - Using semantic similarity (see EmbeddingModelTextClassifierExample in this repository).
* - Using an LLM to make a routing decision.
* <p>
* For scenarios 1, 2, and 3, you can implement a custom {@link QueryRouter}.
* For scenario 4, this example will demonstrate how to use a {@link LanguageModelQueryRouter}.
*/
public static void main(String[] args) {
Assistant assistant = createAssistant();
// First, ask "What is the legacy of John Doe?"
// Then, ask "Can I cancel my reservation?"
// Now, see the logs to observe how the queries are routed to different retrievers.
startConversationWith(assistant);
}
private static Assistant createAssistant() {
EmbeddingModel embeddingModel = new BgeSmallEnV15QuantizedEmbeddingModel();
// Let's create a separate embedding store specifically for biographies.
EmbeddingStore<TextSegment> biographyEmbeddingStore =
embed(toPath("documents/biography-of-john-doe.txt"), embeddingModel);
ContentRetriever biographyContentRetriever = EmbeddingStoreContentRetriever.builder()
.embeddingStore(biographyEmbeddingStore)
.embeddingModel(embeddingModel)
.maxResults(2)
.minScore(0.6)
.build();
// Additionally, let's create a separate embedding store dedicated to terms of use.
EmbeddingStore<TextSegment> termsOfUseEmbeddingStore =
embed(toPath("documents/miles-of-smiles-terms-of-use.txt"), embeddingModel);
ContentRetriever termsOfUseContentRetriever = EmbeddingStoreContentRetriever.builder()
.embeddingStore(termsOfUseEmbeddingStore)
.embeddingModel(embeddingModel)
.maxResults(2)
.minScore(0.6)
.build();
ChatLanguageModel chatLanguageModel = OpenAiChatModel.builder()
.apiKey(OPENAI_API_KEY)
.modelName(GPT_4_O_MINI)
.build();
// Let's create a query router.
Map<ContentRetriever, String> retrieverToDescription = new HashMap<>();
retrieverToDescription.put(biographyContentRetriever, "biography of John Doe");
retrieverToDescription.put(termsOfUseContentRetriever, "terms of use of car rental company");
QueryRouter queryRouter = new LanguageModelQueryRouter(chatLanguageModel, retrieverToDescription);
RetrievalAugmentor retrievalAugmentor = DefaultRetrievalAugmentor.builder()
.queryRouter(queryRouter)
.build();
return AiServices.builder(Assistant.class)
.chatLanguageModel(chatLanguageModel)
.retrievalAugmentor(retrievalAugmentor)
.chatMemory(MessageWindowChatMemory.withMaxMessages(10))
.build();
}
private static EmbeddingStore<TextSegment> embed(Path documentPath, EmbeddingModel embeddingModel) {
DocumentParser documentParser = new TextDocumentParser();
Document document = loadDocument(documentPath, documentParser);
DocumentSplitter splitter = DocumentSplitters.recursive(300, 0);
List<TextSegment> segments = splitter.split(document);
List<Embedding> embeddings = embeddingModel.embedAll(segments).content();
EmbeddingStore<TextSegment> embeddingStore = new InMemoryEmbeddingStore<>();
embeddingStore.addAll(embeddings, segments);
return embeddingStore;
}
}
这里使用了DefaultRetrievalAugmentor来设置了LanguageModelQueryRouter,这里设置了biographyContentRetriever、termsOfUseContentRetriever两个ContentRetriever。
源码解析
RetrievalAugmentor
dev/langchain4j/rag/RetrievalAugmentor.java
@Experimental
public interface RetrievalAugmentor {
/**
* Augments the {@link ChatMessage} provided in the {@link AugmentationRequest} with retrieved {@link Content}s.
* <br>
* This method has a default implementation in order to <b>temporarily</b> support
* current custom implementations of {@code RetrievalAugmentor}. The default implementation will be removed soon.
*
* @param augmentationRequest The {@code AugmentationRequest} containing the {@code ChatMessage} to augment.
* @return The {@link AugmentationResult} containing the augmented {@code ChatMessage}.
*/
default AugmentationResult augment(AugmentationRequest augmentationRequest) {
if (!(augmentationRequest.chatMessage() instanceof UserMessage)) {
throw runtime("Please implement 'AugmentationResult augment(AugmentationRequest)' method " +
"in order to augment " + augmentationRequest.chatMessage().getClass());
}
UserMessage augmented = augment((UserMessage) augmentationRequest.chatMessage(), augmentationRequest.metadata());
return AugmentationResult.builder()
.chatMessage(augmented)
.build();
}
/**
* Augments the provided {@link UserMessage} with retrieved content.
*
* @param userMessage The {@link UserMessage} to be augmented.
* @param metadata The {@link Metadata} that may be useful or necessary for retrieval and augmentation.
* @return The augmented {@link UserMessage}.
* @deprecated Use/implement {@link #augment(AugmentationRequest)} instead.
*/
@Deprecated
UserMessage augment(UserMessage userMessage, Metadata metadata);
}
RetrievalAugmentor接口定义了augment(AugmentationRequest augmentationRequest)方法,它作为langchain4j的RAG入口,负责根据AugmentationRequest来检索相关Content,它提供了默认实现主要是适配废弃的
augment(UserMessage userMessage, Metadata metadata)方法
DefaultRetrievalAugmentor
dev/langchain4j/rag/DefaultRetrievalAugmentor.java
public class DefaultRetrievalAugmentor implements RetrievalAugmentor {
private static final Logger log = LoggerFactory.getLogger(DefaultRetrievalAugmentor.class);
private final QueryTransformer queryTransformer;
private final QueryRouter queryRouter;
private final ContentAggregator contentAggregator;
private final ContentInjector contentInjector;
private final Executor executor;
public DefaultRetrievalAugmentor(QueryTransformer queryTransformer,
QueryRouter queryRouter,
ContentAggregator contentAggregator,
ContentInjector contentInjector,
Executor executor) {
this.queryTransformer = getOrDefault(queryTransformer, DefaultQueryTransformer::new);
this.queryRouter = ensureNotNull(queryRouter, "queryRouter");
this.contentAggregator = getOrDefault(contentAggregator, DefaultContentAggregator::new);
this.contentInjector = getOrDefault(contentInjector, DefaultContentInjector::new);
this.executor = getOrDefa 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 935
935

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









