






告别繁琐评估!一键搞定 RTDETR 模型批量验证与可视化报告
- 前言
- 一、为什么需要这套工具?
- 二、工具三大超能力
- 1.模型自动 “扫雷”:精准定位所有待评估模型
- 2.批量 “体检”:一键算出所有关键指标
- 3.自动生成 “体检报告”:Excel 里藏着最优解
- 三、如何上手?3 步搞定
- 四、总代码
前言
你是否也曾陷入这样的困境:训练了十几个目标检测模型,却要逐个手动跑验证、抄指标、算均值,最后还要对着一堆零散数据挠头 —— 到底哪个模型才是最优解?
别慌!今天要分享的这套工具,能帮你把模型评估效率直接拉满:从自动扫描文件夹里的所有模型,到批量计算精度 / 召回率 /mAP 等核心指标,再到生成带排名和可视化的 Excel 报告,全程无需手动干预。尤其适合 RTDETR 模型的批量对比,让你把时间花在调优上,而不是机械劳动里。
一、为什么需要这套工具?
做目标检测模型开发时,我们总要面对这些问题:
- 训练好的模型散落在不同文件夹,找起来像 “拆盲盒”
- 每个模型都要手动跑验证、记录数据,重复劳动到崩溃
- 指标太多(精度、召回率、mAP50、FPS…),对比时眼花缭乱
- 汇报时要手动整理表格,格式混乱还容易算错
这套工具的核心就是 “自动化”+“结构化”:让机器做重复工作,让人专注决策。
二、工具三大超能力
1.模型自动 “扫雷”:精准定位所有待评估模型
它就像一个智能扫描仪,能自动钻进你指定的训练文件夹,把所有藏着weights/best.pt的模型揪出来。不管文件夹里有多少个子目录,只要有最优模型权重,它都能准确记录路径、名称等信息,还会贴心地告诉你 “哪个文件夹里没找到模型”。
代码如下(示例):
# 核心逻辑:逐个遍历模型权重
def find_all_models_in_train_folder(train_folder_path):
models_info = []
for model_name in os.listdir(train_folder_path):
# 拼接路径,检查是否有 weights/best.pt
weight_path = os.path.join(model_path, 'weights', 'best.pt')
if os.path.exists(weight_path):
models_info.append({
'path': weight_path, # 模型路径
'model_name': model_name, # 模型名
'full_name': f"{train_folder_path}/{model_name}" # 完整路径
})
else:
print(f" ✗ 跳过 {model_name} (未找到 weights/best.pt)")
return models_info
2.批量 “体检”:一键算出所有关键指标
找到模型后,工具会自动给每个模型做 “全面体检”。基于 Ultralytics 的 RTDETR 接口,它能:
- 自动加载模型,在测试集上跑验证(保证评估标准统一);
- 算出每个类别的精度(Precision)、召回率(Recall)、F1 分数、 mAP50、mAP75、mAP50-95 等核心检测指标;
- 算法性能:FPS(每秒能处理多少张图)、模型大小(MB)、参数量
如下为各项指标参数计算方式:
# 给每个类别算分
for idx in range(类别数):
class_metrics.append({
'name': 类别名,
'precision': float(result.box.p[idx]), # 精度
'recall': float(result.box.r[idx]), # 召回率
'f1': float(result.box.f1[idx]), # F1分数
'ap50': float(result.box.ap50[idx]), # AP@50
'ap75': float(result.box.all_ap[idx, 5]), # AP@75
'ap50_95': float(result.box.ap[idx]) # AP@50-95
})
# 算平均值,方便整体对比
class_metrics.append({
'name': 'all(平均数据)',
'precision': 所有类别精度均值,
'ap50_95': 所有类别mAP50-95均值 # 这个指标最关键!
})
跑验证时,终端会实时输出进度,让你知道 “模型没跑崩,还在干活”。
3.自动生成 “体检报告”:Excel 里藏着最优解
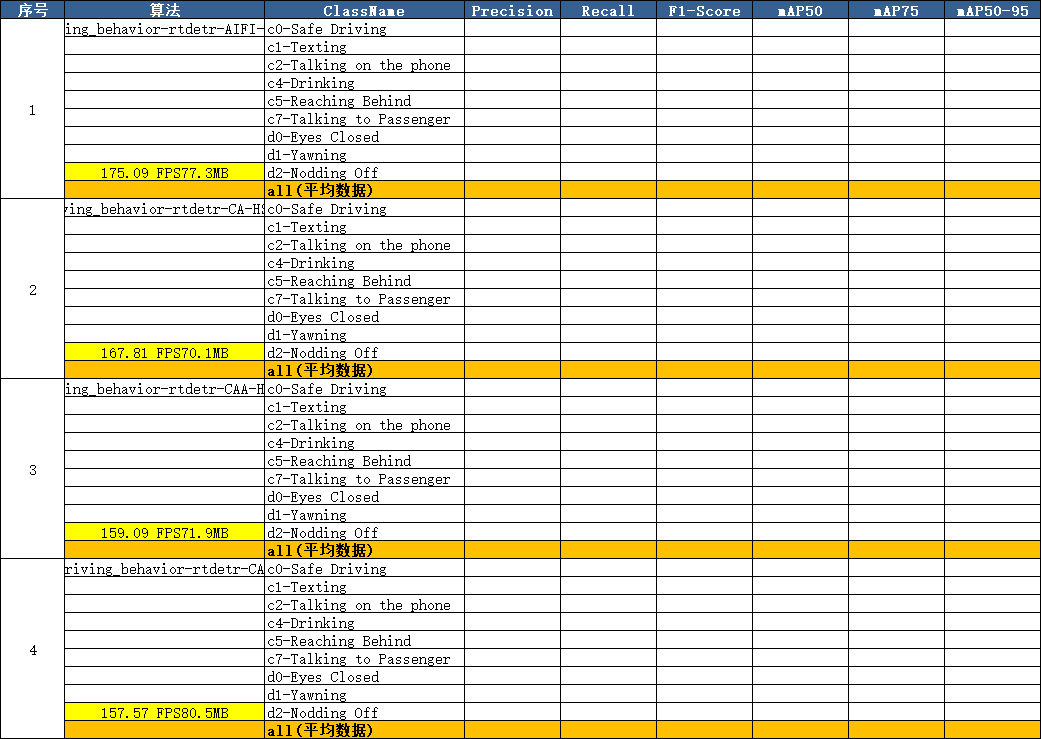
最香的是,它会把所有结果整理成一份高颜值 Excel 报告,包含两个核心表格(详细结果表和汇总排名表):
详细结果表:按模型分组,指标一目了然
- 每个模型的每个类别指标单独列出,方便看 “哪个类别拖后腿”
- 平均值行用橙色高亮,一眼定位整体性能
- 黄色单元格标注 FPS 和模型大小,兼顾 “精度” 和 “速度”
汇总排名表:按关键指标排序,最优模型直接 “C 位出道”
自动按 mAP50-95(最权威的综合指标)降序排列,附带精度、召回率、FPS 等,帮你快速决策

三、如何上手?3 步搞定
1、搭环境:
# 安装依赖
pip install ultralytics openpyxl pandas numpy
2、改路径:
# 打开代码,改两个关键路径:
# 你的训练文件夹(里面有多个模型子文件夹)
train_folder_path = r'E:\你的路径\Driving_behavior\runs\train-0'
# 你的数据集配置文件(告诉模型测试集在哪)
data_yaml_path = r'E:\你的路径\Driving_behavior\data.yaml'
3、跑起来:
直接执行脚本,然后坐等结果。程序会在训练文件夹下生成带时间戳的 Excel,比如validation_results_20250806_153020.xlsx。
四、总代码
import warnings, os
os.environ["CUDA_VISIBLE_DEVICES"] = "1"
warnings.filterwarnings('ignore')
import glob
from datetime import datetime
import numpy as np
import pandas as pd
from openpyxl import Workbook
from openpyxl.styles import Alignment, Font, PatternFill, Border, Side
from openpyxl.utils.dataframe import dataframe_to_rows
from ultralytics import RTDETR
from ultralytics.utils.torch_utils import model_info
def get_weight_size(path):
"""获取模型文件大小(MB)"""
stats = os.stat(path)
return f'{stats.st_size / 1024 / 1024:.1f}'
def find_all_models_in_train_folder(train_folder_path):
"""查找特定 train 文件夹中的所有模型"""
models_info = []
if not os.path.exists(train_folder_path):
print(f"错误:路径不存在 - {train_folder_path}")
return models_info
for model_name in os.listdir(train_folder_path):
model_path = os.path.join(train_folder_path, model_name)
if os.path.isdir(model_path):
weight_path = os.path.join(model_path, 'weights', 'best.pt')
if os.path.exists(weight_path):
train_folder = os.path.basename(train_folder_path)
models_info.append({
'path': weight_path,
'train_folder': train_folder,
'model_name': model_name,
'full_name': f"{train_folder}/{model_name}"
})
print(f" ✓ 找到模型: {model_name}")
else:
print(f" ✗ 跳过 {model_name} (未找到 weights/best.pt)")
return models_info
def validate_single_model(model_dict, data_yaml_path):
"""验证单个模型并返回详细结果"""
print(f"\n{'=' * 60}")
print(f"正在验证模型: {model_dict['full_name']}")
print(f"模型路径: {model_dict['path']}")
print(f"{'=' * 60}\n")
try:
model = RTDETR(model_dict['path'])
result = model.val(
data=data_yaml_path,
split='test',
imgsz=640,
batch=4,
project='runs/val',
name=f"exp_{model_dict['train_folder']}_{model_dict['model_name']}",
)
if model.task == 'detect':
length = result.box.p.size
model_names = list(result.names.values())
preprocess_time_per_image = result.speed['preprocess']
inference_time_per_image = result.speed['inference']
postprocess_time_per_image = result.speed['postprocess']
n_l, n_p, n_g, flops = model_info(model.model)
fps_inference = 1000 / inference_time_per_image
model_size_mb = get_weight_size(model_dict["path"])
# 收集每个类别的详细指标
class_metrics = []
for idx in range(length):
# 确保获取正确的值
precision = float(result.box.p[idx])
recall = float(result.box.r[idx])
f1_score = float(result.box.f1[idx])
ap50 = float(result.box.ap50[idx])
ap75 = float(result.box.all_ap[idx, 5])
ap50_95 = float(result.box.ap[idx])
class_metrics.append({
'name': model_names[idx],
'precision': precision,
'recall': recall,
'f1': f1_score,
'ap50': ap50,
'ap75': ap75,
'ap50_95': ap50_95
})
# 打印调试信息
print(f" {model_names[idx]}: P={precision:.4f}, R={recall:.4f}, F1={f1_score:.4f}")
# 添加平均值
avg_precision = float(result.results_dict['metrics/precision(B)'])
avg_recall = float(result.results_dict['metrics/recall(B)'])
avg_f1 = float(np.mean(result.box.f1[:length]))
avg_ap50 = float(result.results_dict['metrics/mAP50(B)'])
avg_ap75 = float(np.mean(result.box.all_ap[:length, 5]))
avg_ap50_95 = float(result.results_dict['metrics/mAP50-95(B)'])
class_metrics.append({
'name': 'all(平均数据)',
'precision': avg_precision,
'recall': avg_recall,
'f1': avg_f1,
'ap50': avg_ap50,
'ap75': avg_ap75,
'ap50_95': avg_ap50_95
})
print(f" 平均值: P={avg_precision:.4f}, R={avg_recall:.4f}, F1={avg_f1:.4f}")
print(f"\n✓ 模型 {model_dict['full_name']} 验证完成")
return True, {
'model_name': model_dict['model_name'],
'fps': fps_inference,
'model_size': model_size_mb,
'class_metrics': class_metrics,
'parameters': n_p
}
except Exception as e:
error_msg = f"✗ 模型 {model_dict['full_name']} 验证失败: {str(e)}"
print(error_msg)
return False, None
def create_excel_report(all_results, output_file):
"""创建Excel格式的报告"""
wb = Workbook()
# 创建详细结果表
ws_detail = wb.active
ws_detail.title = "详细验证结果"
# 设置表头
headers = ["序号", "算法", "ClassName", "Precision", "Recall", "F1-Score", "mAP50", "mAP75", "mAP50-95"]
ws_detail.append(headers)
# 设置表头样式
header_fill = PatternFill(start_color="366092", end_color="366092", fill_type="solid")
header_font = Font(color="FFFFFF", bold=True)
thin_border = Border(
left=Side(style='thin'),
right=Side(style='thin'),
top=Side(style='thin'),
bottom=Side(style='thin')
)
for cell in ws_detail[1]:
cell.fill = header_fill
cell.font = header_font
cell.alignment = Alignment(horizontal='center', vertical='center')
cell.border = thin_border
# 添加数据
current_row = 2
for idx, result in enumerate(all_results, 1):
if result['success']:
data = result['data']
model_name = f"Driving_behavior-\nrtdetr-{data['model_name'].replace('rtdetr-', '')}"
# 记录起始行
start_row = current_row
# 添加每个类别的数据
for i, class_metric in enumerate(data['class_metrics']):
row_data = []
if i == 0: # 第一行显示序号和模型名
row_data = [
idx,
model_name,
class_metric['name'],
f"{class_metric['precision']:.4f}",
f"{class_metric['recall']:.4f}",
f"{class_metric['f1']:.4f}",
f"{class_metric['ap50']:.4f}",
f"{class_metric['ap75']:.4f}",
f"{class_metric['ap50_95']:.4f}"
]
else:
row_data = [
"",
"",
class_metric['name'],
f"{class_metric['precision']:.4f}",
f"{class_metric['recall']:.4f}",
f"{class_metric['f1']:.4f}",
f"{class_metric['ap50']:.4f}",
f"{class_metric['ap75']:.4f}",
f"{class_metric['ap50_95']:.4f}"
]
ws_detail.append(row_data)
# 为倒数第二行添加FPS和模型大小信息
if i == len(data['class_metrics']) - 2:
ws_detail.cell(row=current_row, column=2).value = f"{data['fps']:.2f} FPS\n{data['model_size']}MB"
ws_detail.cell(row=current_row, column=2).alignment = Alignment(wrap_text=True, horizontal='center',
vertical='center')
ws_detail.cell(row=current_row, column=2).fill = PatternFill(start_color="FFFF00",
end_color="FFFF00", fill_type="solid")
current_row += 1
# 合并序号单元格
if current_row - start_row > 1:
ws_detail.merge_cells(f'A{start_row}:A{current_row - 1}')
ws_detail.cell(row=start_row, column=1).alignment = Alignment(horizontal='center', vertical='center')
# 高亮显示平均数据行
for col in range(1, 10):
cell = ws_detail.cell(row=current_row - 1, column=col)
cell.fill = PatternFill(start_color="FFC000", end_color="FFC000", fill_type="solid")
cell.font = Font(bold=True)
# 设置所有单元格边框和对齐
for row in ws_detail.iter_rows(min_row=2, max_row=ws_detail.max_row):
for cell in row:
cell.border = thin_border
if cell.column >= 4: # 数值列右对齐
cell.alignment = Alignment(horizontal='right', vertical='center')
elif cell.column == 3: # ClassName列左对齐
cell.alignment = Alignment(horizontal='left', vertical='center')
else: # 序号和算法列居中
cell.alignment = Alignment(horizontal='center', vertical='center')
# 调整列宽
ws_detail.column_dimensions['A'].width = 8
ws_detail.column_dimensions['B'].width = 25
ws_detail.column_dimensions['C'].width = 25
for col in ['D', 'E', 'F', 'G', 'H', 'I']:
ws_detail.column_dimensions[col].width = 12
# 创建汇总表
ws_summary = wb.create_sheet("模型性能汇总")
# 汇总表头 - 添加了 Precision、Recall、F1-Score
summary_headers = ["排名", "模型名称", "Precision", "Recall", "F1-Score", "mAP50", "mAP50-95", "FPS", "参数量",
"模型大小(MB)"]
ws_summary.append(summary_headers)
# 设置汇总表头样式
for cell in ws_summary[1]:
cell.fill = header_fill
cell.font = header_font
cell.alignment = Alignment(horizontal='center', vertical='center')
cell.border = thin_border
# 收集成功的结果并排序
success_results = []
for result in all_results:
if result['success']:
data = result['data']
avg_metrics = data['class_metrics'][-1] # 最后一个是平均值
success_results.append({
'name': data['model_name'],
'precision': avg_metrics['precision'],
'recall': avg_metrics['recall'],
'f1': avg_metrics['f1'],
'mAP50': avg_metrics['ap50'],
'mAP50_95': avg_metrics['ap50_95'],
'fps': data['fps'],
'params': data['parameters'],
'size': float(data['model_size'])
})
# 按 mAP50-95 排序
success_results.sort(key=lambda x: x['mAP50_95'], reverse=True)
# 添加到汇总表
for rank, r in enumerate(success_results, 1):
ws_summary.append([
rank,
r['name'],
round(r['precision'], 4),
round(r['recall'], 4),
round(r['f1'], 4),
round(r['mAP50'], 4),
round(r['mAP50_95'], 4),
round(r['fps'], 2),
f"{r['params']:,}",
r['size']
])
# 设置汇总表样式
for row in ws_summary.iter_rows(min_row=2, max_row=ws_summary.max_row):
for cell in row:
cell.border = thin_border
if cell.column == 1: # 排名居中
cell.alignment = Alignment(horizontal='center', vertical='center')
elif cell.column >= 3: # 数值右对齐
cell.alignment = Alignment(horizontal='right', vertical='center')
else: # 模型名称左对齐
cell.alignment = Alignment(horizontal='left', vertical='center')
# 调整汇总表列宽
ws_summary.column_dimensions['A'].width = 8
ws_summary.column_dimensions['B'].width = 30
for col in ['C', 'D', 'E', 'F', 'G', 'H', 'I', 'J']:
ws_summary.column_dimensions[col].width = 15
# 保存Excel文件
wb.save(output_file)
print(f"\nExcel报告已保存至: {output_file}")
if __name__ == '__main__':
# 设置要验证的特定 train 文件夹路径
train_folder_path = r'E:\A\A\A\A\Driving_behavior\runs\train-0'
data_yaml_path = r'E:\A\A\A\A\Driving_behavior\data.yaml'
# 输出文件保存在 train 文件夹下
timestamp = datetime.now().strftime('%Y%m%d_%H%M%S')
output_file = os.path.join(train_folder_path, f'validation_results_{timestamp}.xlsx')
# 查找所有模型
print(f"开始在以下路径查找模型: {train_folder_path}")
models_info = find_all_models_in_train_folder(train_folder_path)
if not models_info:
print("\n未找到任何模型文件!")
print("请确认每个模型文件夹下都有 weights/best.pt 文件")
exit(1)
print(f"\n总共找到 {len(models_info)} 个模型")
# 存储所有结果
all_results = []
success_count = 0
# 逐个验证模型
for i, model_dict in enumerate(models_info, 1):
print(f"\n进度: {i}/{len(models_info)}")
success, data = validate_single_model(model_dict, data_yaml_path)
all_results.append({
'success': success,
'data': data
})
if success:
success_count += 1
# 创建Excel报告
if all_results:
create_excel_report(all_results, output_file)
# 最终统计
print(f"\n{'=' * 60}")
print(f"验证完成!")
print(f"成功: {success_count}/{len(models_info)}")
print(f"结果已保存至: {output_file}")
print(f"{'=' * 60}")


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









