










一、日志采集场景
一)集群核心组件日志
审计需要kube-apiserver日志,诊断调度需要kube-scheduler日志,接入层流量分析需要Ingress日志
二)主机内核日志
内核日志可以用于帮助开发及运维同学诊断影响节点稳定的异常,如:文件系统异常、网络栈异常、设备驱动异常等。
三)应用运行时日志
docker是最常见的容器运行时,可以利用docker和kubelet日志排查Pod创建和启动等问题
四)业务应用日志
通过分析业务的运行日志分析和观察业务状态,诊断异常。
二、容器日志收集与管理
一)日志采集目标
kubernetes对容器日志的期望处理方式为:集群级日志处理(cluster-level-logging)。即:与容器、pod、节点生命周期完全无关。
对于一个容器,当应用将日志输出到stdout和stderr后,docker默认将这些日志输出到宿主机上一个json文件中。
三、日志采集方式
一)方式一:使用节点级日志代理
1、架构如下
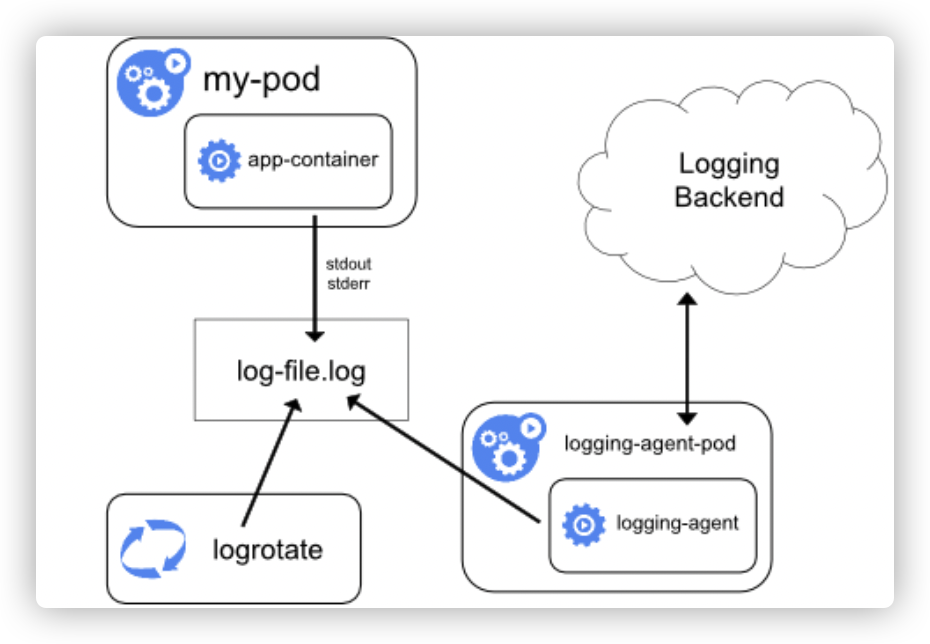
- 核心是logging-agent(fluentd、etc)
- logging-agent以DaemonSet方式运行在节点上
- 挂载宿主机上的容器日志目录
- 转发日志至后端存储(elasticsearch,etc)
2、优缺点
- 优点:对应用和Pod完全无侵入,一个节点仅需部署一个agent
- 缺点:要求应用日志直接输出到容器的stdout和stderr
3、部署
用k8s的daemonset可以方便的在每个node上安装fluent agent,fluent提供了示例仓库:fluentd-kubernetes-daemonset
apiVersion: v1
kind: ServiceAccount
metadata:
name: fluentd-es
namespace: logging
labels:
k8s-app: fluentd-es
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: fluentd-es
labels:
k8s-app: fluentd-es
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
rules:
- apiGroups:
- ""
resources:
- "namespaces"
- "pods"
verbs:
- "get"
- "watch"
- "list"
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: fluentd-es
labels:
k8s-app: fluentd-es
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
subjects:
- kind: ServiceAccount
name: fluentd-es
namespace: logging
apiGroup: ""
roleRef:
kind: ClusterRole
name: fluentd-es
apiGroup: ""
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd-es
namespace: logging
labels:
k8s-app: fluentd-es
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
spec:
selector:
matchLabels:
k8s-app: fluentd-es
template:
metadata:
labels:
k8s-app: fluentd-es
kubernetes.io/cluster-service: "true"
#! 此注释确保如果节点被驱逐,fluentd不会被驱逐,支持关键的基于 pod 注释的优先级方案。
annotations:
scheduler.alpha.kubernetes.io/critical-pod: ''
spec:
serviceAccountName: fluentd-es
containers:
- name: fluentd-es
image: #@ data.values.image
env:
- name: FLUENTD_ARGS
value: --no-supervisor -q
resources:
limits:
memory: 240Mi
requests:
cpu: 100m
memory: 100Mi
volumeMounts:
- name: varlog
mountPath: /var/log
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
- name: config-volume
mountPath: /fluentd/etc/
nodeSelector:
node-role.kubernetes.io/worker: "true"
tolerations:
- operator: Exists
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
- name: config-volume
configMap:
name: fluentd-config
配置configmap,作为配置文件挂载到fluentd:
kind: ConfigMap
apiVersion: v1
metadata:
name: fluentd-config
namespace: logging
data:
system.conf: |-
<system>
root_dir /tmp/fluentd-buffers/
</system>
kubernetes.conf: |-
fluent.conf: |-
<source>
@id fluentd-containers.log
@type tail # Fluentd 内置的输入方式,其原理是不停地从源文件中获取新的日志。
path /var/log/containers/*.log # 挂载的服务器Docker容器日志地址
pos_file /var/log/es-containers.log.pos
tag kubernetes.* # 设置日志标签
read_from_head true
<parse> # 多行格式化成JSON
@type multi_format # 使用 multi-format-parser 解析器插件
<pattern>
format json # JSON解析器
time_key time # 指定事件时间的时间字段
time_format %Y-%m-%dT%H:%M:%S.%NZ # 时间格式
</pattern>
</parse>
</source>
# 添加 Kubernetes metadata 数据
<filter kubernetes.**>
@id filter_kubernetes_metadata
@type kubernetes_metadata
</filter>
# 只保留具有logging=1标签的Pod日志
<filter kubernetes.**>
@id filter_log
@type grep
<regexp>
key $.kubernetes.labels.logging
pattern ^1$
</regexp>
</filter>
# 删除一些多余的属性
<filter kubernetes.**>
@type record_transformer
remove_keys $.docker.container_id,$.kubernetes.container_image_id,$.kubernetes.pod_id,$.kubernetes.namespace_id,$.kubernetes.master_url,$.kubernetes.labels.pod-template-hash
</filter>
<match kubernetes.**>
@id elasticsearch
@type elasticsearch
@log_level debug
include_tag_key true
hosts [hosts]
user [user]
password [password]
logstash_format true
logstash_prefix [prefix] # 设置 index 前缀为 k8s
type_name doc
request_timeout 30s
<buffer>
@type file
path /var/log/fluentd-buffers/kubernetes.system.buffer
flush_mode interval
retry_type exponential_backoff
flush_thread_count 2
flush_interval 5s
retry_forever
retry_max_interval 30
chunk_limit_size 2M
queue_limit_length 8
overflow_action block
</buffer>
</match>
后续当configmap更新时,会自动更新挂载到容器中的文件,参考mounted-configmaps-are-updated-automatically
创建自定义镜像,安装需要的插件:
FROM fluent/fluentd-kubernetes-daemonset:v1.10.4-debian-elasticsearch7-1.0 # 插件用于添加k8s的一些metadata信息到log中 RUN gem install fluent-plugin-kubernetes_metadata_filter
.dockerignore
Dockerfile .dockerignore README.md *.yaml *.sh *.VERSION* k8s/
创建部署脚本deploy.sh
#!/bin/bash
set -e
env="$1"
registryStage=""
registryProduction=""
versionFile=".VERSION"
if [ -z "$env" ]; then
env="stage"
registry=$registryStage
elif [ $env == 'production' ]; then
registry=$registryProduction
fi
# generate version
bash version.sh $versionFile
version=`cat $versionFile`
img=$registry/fluentd:$version
echo "deploy: $env, version: $version, img: $img"
docker build . -t $img
docker push $img
echo "deploy configmap"
kubectl apply -f k8s/fluentd-configmap-$env.yaml
echo "deploy daemon set"
ytt -f k8s/fluentd-daemonset.yaml -f k8s/values.yaml --data-value image=$img | kubectl apply -f-
版本控管脚本version.sh
#!/bin/bash
set -e
versionFile="$1"
# if versionFile not given, set default file name
if [ -z "$versionFile" ]; then
versionFile=".VERSION"
fi
# if file not exists, set default version
if [ ! -f "$versionFile" ]; then
echo "0.0.0" > "$versionFile"
fi
echo "bump version"
# using treeder/bump to bump version
docker run --rm -v "$PWD":/app treeder/bump --filename "$versionFile"
二)方式二:使用sidecar和日志代理
1、架构如下
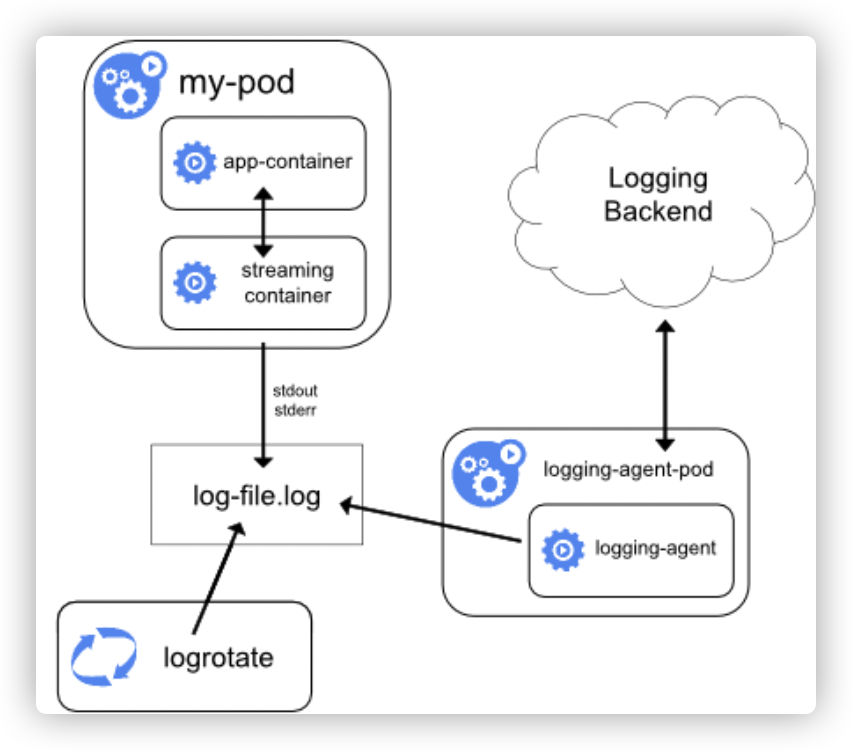
- 容器全部或部分日志输出到文件
- 一个或多个sidecar容器将应用程序日志输出到自己的stdout和stderr
2、优缺点
- 优点:能够继续使用日志手机方式1
- 缺点:成倍增加磁盘占用,造成浪费。(应用和sidecar容器写入两份相同日志文件)
三)方式三:使用日志代理功能的sidecar容器
1、架构如下
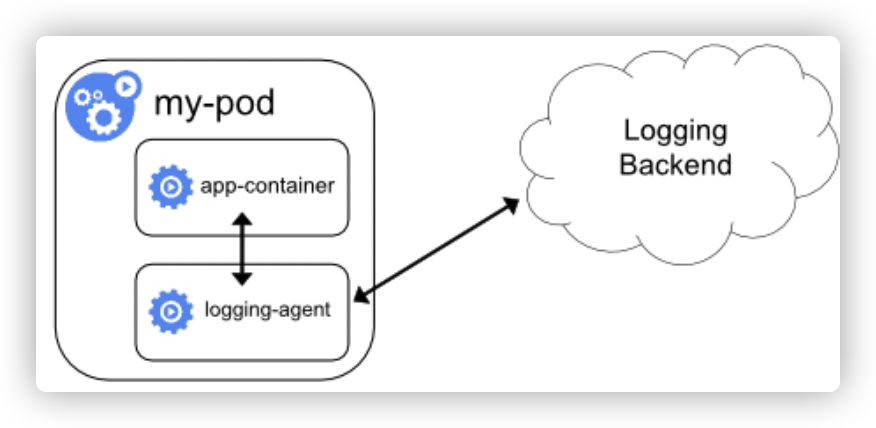
- 相当于将logging-agent直接集成进Pod
- 应用和输出日志至stdout & stderr 或文件
- logging-agent的输入源为应用日志文件
2、优缺点
- 优点:部署简单,对宿主机友好
- 缺点:
- sidecar容器可能消耗较多资源,甚至拖挂应用容器
- 无法使用kubectl logs命令查看容器日志
四)总结:实现集群级日志采集的三种方法
- 使用节点级日志代理
- 使用sidecar容器和日志代理
- 使用具有日志代理功能的sidecar容器
建议:使用方案1,将应用日志输出到stdout & stderr,通过在宿主机上直接部署logging-agent的方式集中处理日志
优点:
- 部署简单
- 可以使用kubectl logs目录查看日志
- 宿主机本身可能已有rsyslogd等成熟日志收集组件可使用


















 1057
1057

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









