










一、SRE是个全能手,DevOps的实践者
SRE全称:Site Reliability Engineering,翻译过来就是:站点可靠性工程师。
SRE的职责确保站点的可用,为了达到这个目的,他需要对站点涉及的系统、组件熟悉,需要关注生产运行时的状态,为此,他需要有很多工具和系统支撑其完成上述工作,比如自动化发布系统,监控系统,日志系统,服务器资源分配和编排等,这些工具需要他们自己完成开发和维护。
SRE是一个综合素质很高的全能手,需要懂服务器基础架构、操作系统、网络、中间件容器、常用编程语言、全局的架构意识、非常强的问题分析能力、极高的抗压能力(以便沉着高效地排障),他们还需要懂性能调优理论...
SRE的工作是Develop+Operate的结合,SRE是DevOps的实践者,他们的工作内容和职责和传统运维工程师差不多:发布、部署、监控、排障,目标一致。但是SRE的手段更加自动化,更高效,这种高效来源于自动化工具、监控工具的支撑,更因为其作为这些工具的开发者,不断优化和调整,使整个工具箱使起来更加得心应手,这也是DevOps的魅力所在。
SRE体系结构的五大根基
二、分布式环境运维大不同于传统运维
我的理解:在分布式环境下,系统的复杂度增大、维护目标增多,按照传统的手工或者半自动维护来做,是不行的。所以,需要转变思路:事务性的工作工具化。比如:版本发布、服务器监控;
让系统自反馈。完善的监控告警机制,完善的日志记录和分析体制,可视化系统的健康状态,使得系统变得可追踪和调校;
分布式策略应对巨量运维对象。负载均衡、流控、数据完整性、批处理的变得不一样,需要重新设计和实践。同时,更要重视连锁式故障。
三、分布式系统的核心——分布式共识
分布式共识问题是指“在不稳定的通信环境下一组进程之间对某项事情达成一致的问题”。
分布式共识系统可以用来解决:领头人选举、关键共享状态、分布式锁等问题。或者绝对点,所有的分布式问题都应当考虑到分布式共识的问题。
分布式共识的理论基础和实现都不是很好理解,抽时间搞清楚是大有裨益的,这里罗列一下几个关键词:
- 拜占庭问题
- 可复制状态机
- Paxos算法
- Zookeeper
- Chubby
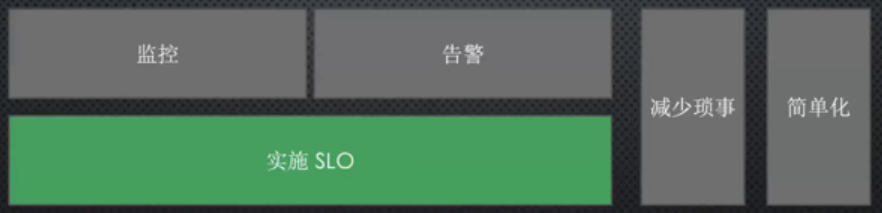
四、 监控很重要!很重要!很重要!
监控是SRE眼睛的延伸。
监控系统应当解决两个问题:现象(什么东西出故障了?),原因(为什么出故障?)
- 现象—— 用户可感知的现象,比如:登陆不了、支付订单变慢;
- 原因—— 造成现象的潜在因素,可能只是中间因素或者相关因素,并非根本原因,根本原因需要SRE介入分析并确定。比如:login 服务CPU超过警戒值,订单服务器CLOSE_WAIT状态的TCP链接数猛增等等。
四个黄金指标:时延、流量(PV)、错误、饱和度(服务器资源使用情况)。前三个是对服务进行监控,后一个是对服务器进行监控,当然也可以包含容器的状态监控,比如线程池、GC等。
几条箴言:
指标简化到不能再简化
关注长尾现象,要时延分布,而不是平均时延
慎重发出紧急警报,预防“狼来了”现象,紧急警报都是课操作的,且不能惯性得出结论的问题
警报不要重复,避免浪费SRE的注意力
五、排障
定位故障点。合理判定问题的严重程度,尝试尽快恢复服务或者缓解问题。
借助监控工具和日志工具检查系统或者服务状态。服务时延和错误率、系统资源使用状态情况、日志统计分析
逐层检查和分解问题,解析问题现象,不断假设/验证地进行诊断,找到根本原因
六、发布
自动化发布应当作为基础设施,第一优先级建设,他的重要性和自动化测试一样。之前参加的“软件工程的精益化管理”课程实验中,实践证明了自动化工具的威力很大,能够明显提升整个团队的生产力。
关于自动化发布的内容和分享网上非常多,而且国内各大互联公司分享出来的材料也是汗牛充栋,用到是可以学习。
七、反思 and 总结
这两个优点对于SRE很是重要,反思使得SRE从失败中学习教训,总结使SRE从时间中获得经验,个人和团队需要学习和践行这种精神,但是对事不对人。
Google的做法是:时事后总结机制。
避免指责,提供建设性意见,充满正能量
事后总结报告需要评审,避免低质量的事后总结带来负面影响
google的事后总结模板
八、追本溯源、怀疑一切
SRE是天生怀疑论者,怀疑一切,眼见为实,追本溯源是本性,感觉自己的性格还蛮适合的~
九、拥抱风险
传统运维是厌恶风险的,但是开发和产品却更关注变化速度,他们都希望迭代速度越快越好,但是这回给系统运行带来风险,所以这天生是矛盾。
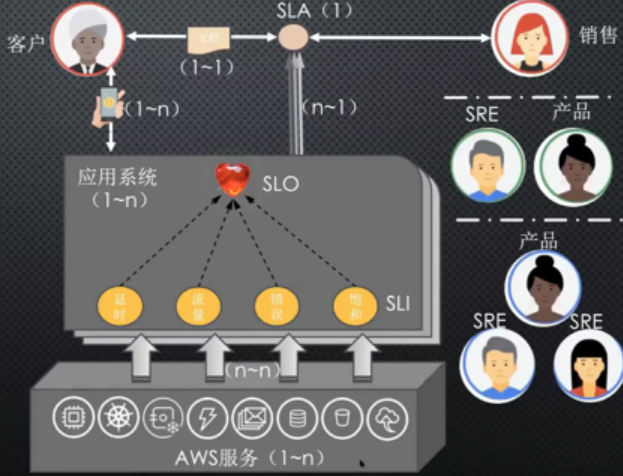
为了解决风险和变化的矛盾,google提出了SLI-->SLO-->SLA的机制。
- SLI——服务质量指标(Service Level Indicaior),如:延时、吞吐量、错误率、可用性等;比如,对于网站来说,一个常见的SLI是请求得到正常响应的百分比。
- SLO——服务质量目标(Service Level Objective),服务的某个SLI的目标值,或者目标范围。比如:SLI<=目标值
- SLA——服务质量协议(Service Level Agreement),服务(SRE)和用户(开发、产品)之间的一个明确的、或者不明确的协议,描述了在达到或者没有达到SLO之后的后果。或者可以转化为先行的KPI,比如系统可用性99.99%等。
一)SLI
1、SLI是什么
SLI 是您提供的服务水平的指标。
虽然许多数字都可以用作 SLI,但我们通常建议将 SLI 视为两个数字的比率:好事件数除以事件总数。例如:
- 成功的 HTTP 请求数 / 总 HTTP 请求数(成功率)
- 在 < 100 毫秒内成功完成的 gRPC 调用数/总 gRPC 请求数
- 使用整个语料库的搜索结果数 / 搜索结果总数,包括正常降级的结果
- 使用更新时间超过 10 分钟的库存数据的产品搜索的“库存检查计数”请求数 / 库存检查请求总数
- 根据该指标的某些扩展标准列表的“良好用户分钟数”/用户分钟总数
这种形式的 SLI 有几个特别有用的属性。SLI 的范围从 0% 到 100%,其中 0% 表示没有任何工作,100% 表示没有任何问题。
我们发现这个尺度很直观,而且这种风格很容易适用于错误预算的概念:SLO 是一个目标百分比,错误预算是 100% 减去 SLO。例如,如果您的 SLO 成功率为 99.9%,那么在 4 周内接收 300 万个请求的服务在此期间的预算为 3,000 (0.1%) 错误。如果一次中断导致 1,500 个错误,则该错误的成本占错误预算的 50%
此外,让您的所有 SLI 遵循一致的风格可以让您更好地利用工具:您可以编写警报逻辑、SLO 分析工具、错误预算计算和报告以期望相同的输入:分子、分母和阈值。简化在这里是一个好处
2、SLI
划分为SLI 规范和SLI 实现
SLI规格
- 认为对用户重要的服务结果评估,与衡量方式无关。
SLI 实现
- SLI 规范及其测量方法
一个 SLI 规范可能有多个 SLI 实现,每个在质量(它们捕获用户体验的准确程度)、覆盖范围(它们捕获所有用户体验的程度方面都有自己的优缺点)和成本。
二)SLO
1、为什么SRE需要SLO
SRE 的核心职责不仅仅是自动化“所有事情”和管理传呼机。他们的日常任务和项目由 SLO 驱动:确保 SLO 在短期内得到维护,并在中长期内得到维护。
SLO 是一种工具,可帮助确定优先处理哪些工程工作。例如,考虑两个可靠性项目的工程权衡:自动回滚和移动到复制的数据存储。通过计算对我们的错误预算的估计影响,我们可以确定哪个项目对我们的用户最有利。有关这方面的更多详细信息
2、100%的SLO正确吗
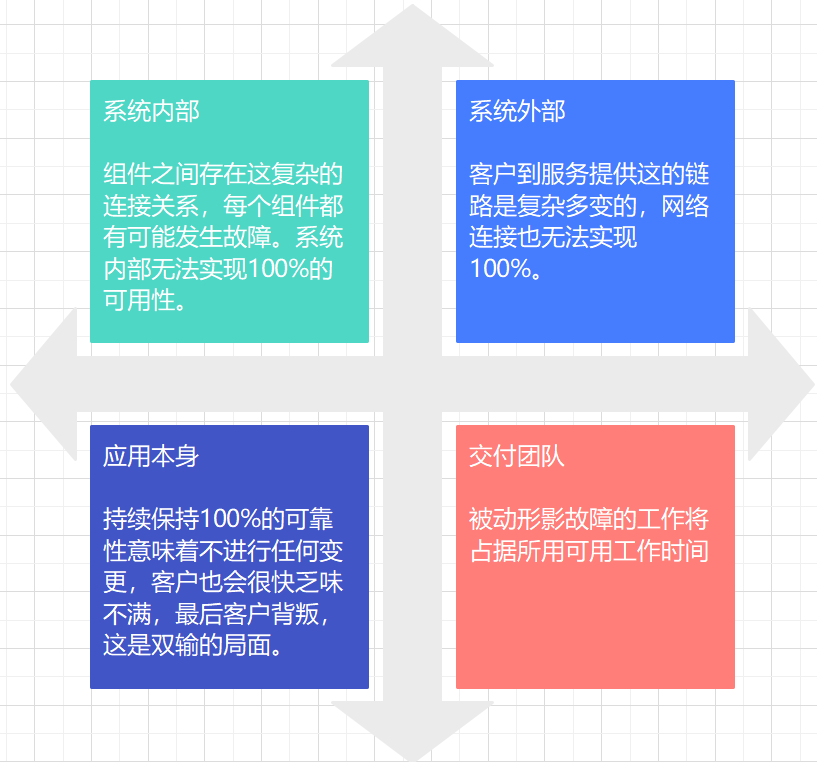
100% 的可靠性是错误的目标
- 如果您的 SLO 与客户满意度保持一致,则 100% 不是一个合理的目标。即使有冗余组件、自动运行状况检查和快速故障转移,一个或多个组件同时发生故障的概率也非零,导致可用性低于 100%。
- 即使您可以在系统中实现 100% 的可靠性,您的客户也不会体验到 100% 的可靠性。您和客户之间的系统链通常又长又复杂,其中任何一个组件都可能出现故障。3这也意味着当您的可靠性从 99% 提高到 99.9% 再到 99.99% 时,每多出 9 个都会增加成本,但对客户的边际效用却稳步趋近于零。
- 如果你确实设法为你的客户创造了 100% 可靠的体验,并且想要保持这种可靠性水平,你就永远无法更新或改进你的服务。中断的首要来源是变化:推出新功能、应用安全补丁、部署新硬件以及扩大规模以满足客户需求将影响 100% 的目标。迟早,你的服务会停滞不前,你的客户会去别处,这对任何人的底线都不利。
- 100% 的 SLO 意味着您只有反应的时间。除了对 < 100% 的可用性做出反应之外,您实际上无法做任何事情,这肯定会发生。100% 的可靠性不是工程文化 SLO,而是运营团队 SLO。
一旦您的 SLO 目标低于 100%,它就需要由组织中有权在功能速度和可靠性之间进行权衡的人负责。在小型组织中,这可能是 CTO;在较大的组织中,这通常是产品所有者(或产品经理)。
3、以SLO为支点的制衡机制

3、SLO在哪一级能够用
Service Level Object 服务水平目标,是围绕SLI构建的目标。通常是一个百分比,并与一个时间范围挂钩。比如,月度、季度、年度等。通常用一连串9来度量。如果脱离了时间的度量,SLO的意义就不大了。 90%(1个9的正常运行时间):这意味着10%的停机时间,也就是说在过去的30天里停机了3天。 99%(2个9的正常运行时间):意味着在过去30天中有1%,或者说7.2小时的停机时间。 99.9%(3个9的正常运行时间):意味着0.1%,或者说43.2分钟的停机时间。 99.95%(3.5个9的正常运行时间):意味着0.05%,或者说21.6分钟的停机时间。 99.99%(4个9的正常运行时间):意味着0.01%,或者说4.32分钟的停机时间。 99.999%(5个9的正常运行时间):意味着0.001%,或者说26秒的停机时间。
4、为系统设置一套合理的SLO
- 正向SLO
- UPTIME > 99.9%
- HTTP 200 > 99.99%
- HTTP 300MS 内响应 > 50%
- 订单 5MIN 内处理 > 99%
- 反向错误预算
- DOWNTIME < 43分钟
- 非200返回码 < 0.01%
- HTTP响应超300MS < 50%
- 订单处理超5MIN < 1%
SLO + 错误预算 = 100%
5、建立SLO相关文档和沟通流程
- 为应用系统建立正式的《SLO文档》
- 获得所有信息干系者的认可:产品经理、开发人员、运维人员、测试人员等
- 建立《出错预算策略》文档
- 面向后果的,得到管理层的授权,SRE有权叫停特性的交付,有权将系统的运维工作退回给开发团队
- 建立SLO的监控仪表板、报表和错误预算燃尽图
- 持续优化SLO目标的设置,持续优化监控方式
6、SLO 基本规则
在我们开始构建我们的 SLO 之前,如果您想运行您的 SLO 文化,应该遵循一些规则。
- 相信 100% SLO 是错误的目标。
- 负责确保服务满足其 SLO 的人员已经同意,它是 正常情况下可以达到这个SLO .
- 该组织已承诺 使用错误预算进行决策和优先排序 .这一承诺在错误预算政策中正式化。
- 有一个流程 细化 SLO
SLI 和 SLO 的第一次尝试不一定是正确的;最重要的目标是将某些事情落实到位并进行衡量,并建立反馈循环以便您进行改进
要创建您的第一组 SLO,您需要确定一些对您的服务很重要的关键 SLI 规范。可用性和延迟 SLO 很常见;新鲜度、持久性、正确性、质量和覆盖范围 SLO 也有它们的位置
如果您在弄清楚从哪种 SLI 开始时遇到困难,从简单开始会有所帮助:
- 选择一个您要为其定义 SLO 的应用程序。如果您的产品包含许多应用程序,您可以稍后添加这些应用程序。
- 清楚地确定在这种情况下谁是“用户”。这些是您正在优化其幸福感的人。
- 考虑用户与系统交互的常见方式——常见任务和关键活动。
- 绘制系统的高级架构图;显示关键组件、请求流、数据流和关键依赖项。
开发和运维针对某个系统协商好一个SLA后,大家有一个量化的指标,一旦出现冲突时,算一下,看看是否违反SLA,如果违反,那么就升级走流程。这样既灵活,也有章可循。如果开发团队牛逼,代码质量高或者运气好,你可以迭代快,反之你需要慢点来,间接地,大家都对线上系统负责了。
| 服务类型 | SLI 类型 | 描述 |
|---|---|---|
| 请求驱动 | 可用性 | 导致成功响应的请求比例。 |
| 请求驱动 | 潜伏 | 快于某个阈值的请求的比例。 |
| 请求驱动 | 质量 | 如果服务在过载或后端不可用时正常降级,则需要衡量在未降级状态下提供的响应的比例。例如,如果用户数据存储不可用,游戏仍然可以玩,但使用通用图像。 |
| 管道 | 新鲜 | 最近更新时间超过某个时间阈值的数据的比例。理想情况下,此指标计算用户访问数据的次数,以便最准确地反映用户体验。 |
| 管道 | 正确性 | 导致输出正确值的记录的比例。 |
| 管道 | 覆盖范围 | 对于批处理,处理超过某个目标数据量的作业的比例。对于流处理,在某个时间窗口内成功处理的传入记录的比例。 |
| 贮存 | 耐用性 | 可以成功读取的已写入记录的比例。请特别注意持久性 SLI:用户想要的数据可能只是所存储数据的一小部分。例如,如果你有前 10 年的 10 亿条记录,但用户只想要今天的记录(不可用),那么即使他们几乎所有的数据都是可读的,他们也会不高兴 |
SLI 可以使用以下一个或多个来源:
- 应用程序服务器日志
- 负载均衡器监控
- 黑盒监控
- 客户端检测
十、反直觉的真理
1、不要承诺你的系统100%可靠。
因为这样会要其他人过分依赖于你,一旦你出问题,那么将成为众矢之的,相反的,你应当对自己的系统了如指掌,比如能承受的压力,可用性目标,一些明显的坑,一些不支持的属性等,广而告之。
2、有意识地破坏你的系统
不同于演练,而是真实生产系统,在可控范围内,人为制造故障,然后在有人值守的情况下,找到系统的短板和问题。这样等到真正的故障来临时,可以有章可循,快速解决问题。
主动暴露自己的不足好于别人突然揭发你,当然更重要的是要及时纠正不足。


















 1536
1536

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









