







- 数据挖掘、机器学习和深度学习的区别是什么?这些概念都代表什么?
- 我们通过深度学习让机器具备人的能力,甚至某些技能的水平超过人类,比如图像识别、下棋对弈等。那么深度学习的大脑是如何工作的?
- 深度学习是基于神经网络构建的,都有哪些常用的网络模型?
- 深度学习有三个重要的应用领域,这三个应用领域分别是什么?
数据挖掘,机器学习,深度学习的区别是什么?
人工智能→机器学习→深度学习→神经网络
实际上数据挖掘和机器学习在很大程度上是重叠的。
数据挖掘通常是从现有的数据中提取规律模式(pattern)以及使用算法模型(model)。核心目的是找到这些数据变量之间的关系,因此也会通过数据可视化对变量之间的关系进行呈现。通常情况下,只能判断出来变量 A 和变量 B 是有关系的,但并不一定清楚这两者之间有什么具体关系。在谈论数据挖掘的时候,更强调的是从数据中挖掘价值。
深度学习与传统机器学习的区别:
- 传统机器学习往往需要专家(我们)来告诉机器采用什么样的模型算法
- 深度学习中不需要告诉机器具体的特征规律是什么,只需把训练数据和对应的结果告诉机器大脑即可,深度学习会自己找到数据的特征规律!
- 传统机器学习中关注的是算法原理,深度学习中关注的是网络结构,以及网络结构中每层神经元的传输机制。
深度学习的神经网络结构通常比较深,一般都是 5 层以上,甚至也有 101 层或更多的层数。这些深度的神经网络可以让机器更好地自动捕获数据的特征。
神经网络是如何工作的
神经网络结构:
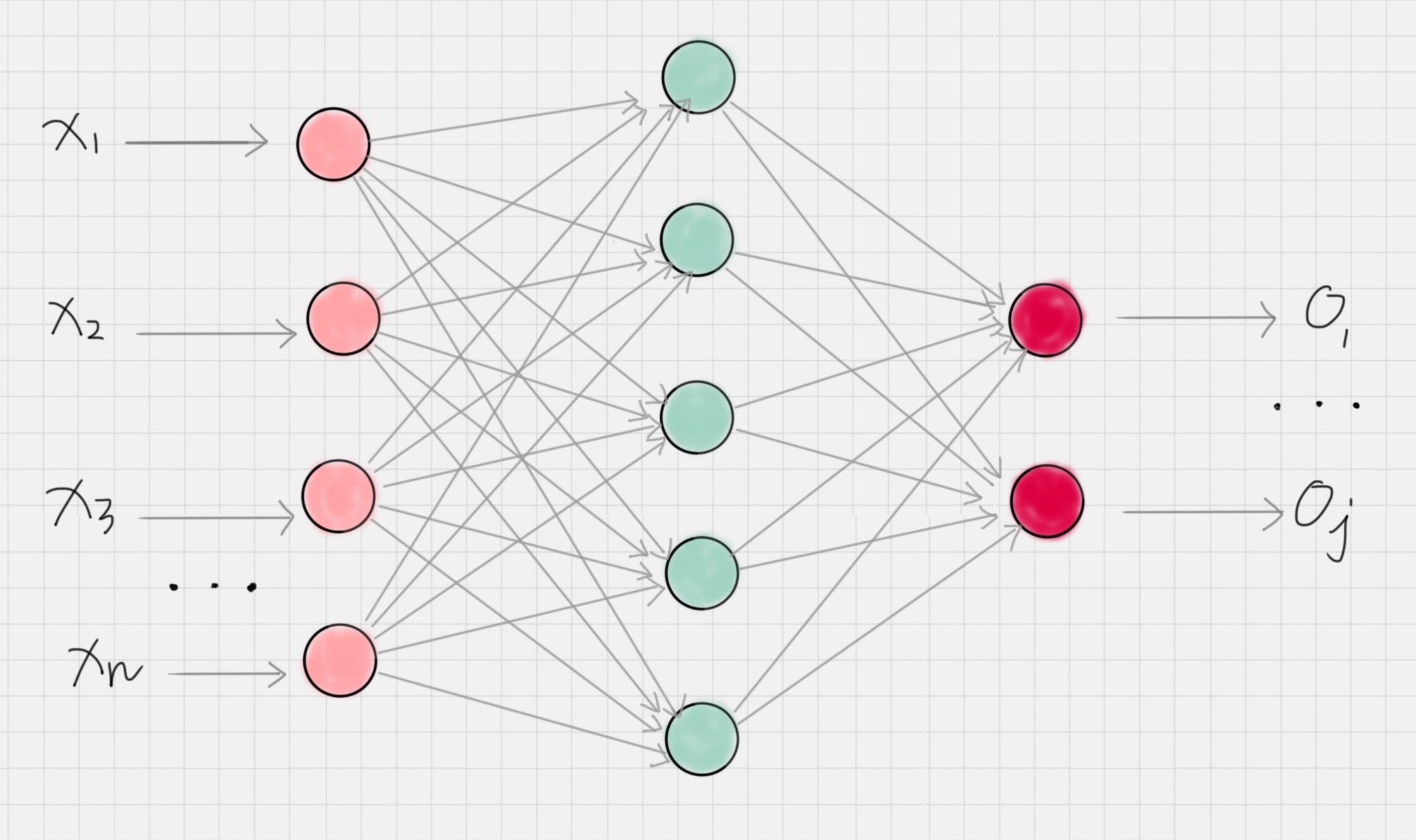
节点:神经网络是由神经元组成的,也称之为节点,它们分布在神经网络的各个层中,这些层包括输入层,输出层和隐藏层。
输入层:负责接收信号,并分发到隐藏层。一般将数据传给输入层。
输出层:负责输出计算结果,一般来说输出层节点数等于要分类的个数。
隐藏层:除了输入层和输出层外的神经网络都属于隐藏层,隐藏层可以是一层也可以是多层,每个隐藏层都会把前一层节点传输出来的数据进行计算(你可以理解是某种抽象表示),这相当于把数据抽象到另一个维度的空间中,可以更好地提取和计算数据的特征。
工作原理:神经网络就好比一个黑盒子,只需要告诉这个黑盒子输入数据和输出数据,神经网络就可以自我训练。一旦训练好之后,就可以像黑盒子一样使用,当传入一个新的数据时,它就会输出对应的结果。在训练过程中,神经网络主要是通过前向传播和反向传播机制运作的。
前向传播:数据从输入层传递到输出层的过程叫做前向传播。这个过程的计算结果通常是通过上一层的神经元的输出经过矩阵运算和激活函数得到的。这样就完成了每层之间的神经元数据的传输。
反向传播:当前向传播作用到输出层得到分类结果之后,需要与实际值进行比对,从而得到误差。反向传播也叫作误差反向传播,核心原理是通过代价函数对网络中的参数进行修正,这样更容易让网络参数得到收敛。
常用的神经网络
按照中间层功能的不同,神经网络可以分为三种网络结构,分别为 FNN、CNN 和 RNN。
FNN(Fully-connected Neural Network)指的是全连接神经网络,全连接的意思是每一层的神经元与上一层的所有神经元都是连接的。不过在实际使用中,全连接的参数会过多,导致计算量过大。因此在实际使用中全连接神经网络的层数一般比较少。
CNN 叫作卷积神经网络,在图像处理中有广泛的应用,CNN 网络中,包括了卷积层、池化层和全连接层。
- 卷积层相当于一个滤镜的作用,它可以把图像进行分块,对每一块的图像进行变换操作。
- 池化层相当于对神经元的数据进行降维处理,这样输出的维数就会减少很多,从而降低整体的计算量。
- 全连接层通常是输出层的上一层,它将上一层神经元输出的数据转变成一维的向量。
RNN 称为循环神经网络,它的特点是神经元的输出可以在下一个时刻作用到自身,这样 RNN 就可以看做是在时间上传递的神经网络。它可以应用在语音识别、自然语言处理等与上下文相关的场景。
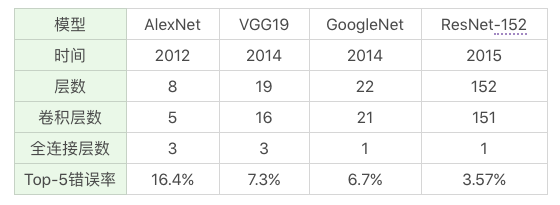
深度学习网络往往包括了这三种网络的变种形成,常用的深度神经网络包括 AlexNet、VGG19、GoogleNet、ResNet 等
深度学习的应用领域
图像识别、语音识别、自然语言处理
卷积
卷积本身是一种矩阵运算,作用是提取特征。
代码案例:
import numpy as np
from scipy import signal
# 设置原图像
img = np.array([[10, 10, 10, 10, 10],
[10, 5, 5, 5, 10],
[10, 5, 5, 5, 10],
[10, 5, 5, 5, 10],
[10, 10, 10, 10, 10]])
# 设置卷积核
fil = np.array([[ -1,-1, 0],
[ -1, 0, 1],
[ 0, 1, 1]])
# 对原图像进行卷积操作
res = signal.convolve2d(img, fil, mode='valid')
# 输出卷积后的结果
print(res)运行结果:
[[ 15 10 0]
[ 10 0 -10]
[ 0 -10 -15]]激活函数的作用
做完卷积操作之后,通常还需要使用激活函数对图像进一步处理。在逻辑回归中,提到过 Sigmoid 函数,它在深度学习中有广泛的应用,除了 Sigmoid 函数作为激活函数以外,tanh、ReLU 都是常用的激活函数。
这些激活函数通常都是非线性的函数,使用它们的目的是把线性数值映射到非线性空间中。卷积操作实际上是两个矩阵之间的乘法,得到的结果也是线性的。只有经过非线性的激活函数运算之后,才能映射到非线性空间中,这样也可以让神经网络的表达能力更强大。
池化层的作用
池化层通常在两个卷积层之间,它的作用相当于对神经元的数据做降维处理,这样就能降低整体计算量。
假设池化的窗大小是 2x2,就相当于用一个 2x2 的窗口对输出数据进行计算,将原图中 2x2 矩阵的 4 个点变成一个点。常用的池化操作是平均池化和最大池化。平均池化是对特征点求平均值,也就是用 4 个点的平均值来做代表。最大池化则是对特征点求最大值,也就是用 4 个点的最大值来做代表。
在神经网络中,可以叠加多个卷积层和池化层来提取更抽象的特征。经过几次卷积和池化之后,通常会有一个或多个全连接层。
全连接层的作用
全连接层将前面一层的输出结果与当前层的每个神经元都进行了连接。
这样就可以把前面计算出来的所有特征,通过全连接层将输出值输送给分类器,比如 Softmax 分类器。在深度学习中,Softmax 是个很有用的分类器,通过它可以把输入值映射到 0-1 之间,而且所有输出结果相加等于 1。其实你可以换种方式理解这个概念,假设我们想要识别一个数字,从 0 到 9 都有可能。那么通过 Softmax 层,对应输出 10 种分类结果,每个结果都有一个概率值,这些概率相加为 1,我们就可以知道这个数字是 0 的概率是多少,是 1 的概率是多少……是 9 的概率又是多少,从而也就帮我们完成了数字识别的任务。
LeNet 和 AlexNet 网络
CNN 网络结构中每一层的作用:它通过卷积层提取特征,通过激活函数让结果映射到非线性空间,增强了结果的表达能力,再通过池化层压缩特征图,降低了网络复杂度,最后通过全连接层归一化,然后连接 Softmax 分类器进行计算每个类别的概率。
LeNet 和 AlexNet 的参数特征:

LeNet 提出于 1986 年,是最早用于数字识别的 CNN 网络,输入尺寸是 32*32。它输入的是灰度的图像,整个的网络结构是:输入层→C1 卷积层→S2 池化层→C3 卷积层→S4 池化层→C5 卷积层→F6 全连接层→Output 全连接层,对应的 Output 输出类别数为 10。
AlexNet 在 LeNet 的基础上做了改进,提出了更深的 CNN 网络模型,输入尺寸是 227*227*3,可以输入 RGB 三通道的图像,整个网络的结构是:输入层→(C1 卷积层→池化层)→(C2 卷积层→池化层)→C3 卷积层→C4 卷积层→(C5 池化层→池化层)→全连接层→全连接层→Output 全连接层。
实际上后面提出来的深度模型,比如 VGG、GoogleNet 和 ResNet 都是基于下面的这种结构方式改进的:输出层→(卷积层 + -> 池化层?)+ → 全连接层 +→Output 全连接层。
其中“+”代表 1 个或多个,“?”代表 0 个或 1 个。
卷积层后面可以有一个池化层,也可以没有池化层,“卷积层 + → 池化层?”这样的结构算是一组卷积层,在多组卷积层之后,可以连接多个全连接层,最后再接 Output 全连接层。
常用的深度学习框架对比
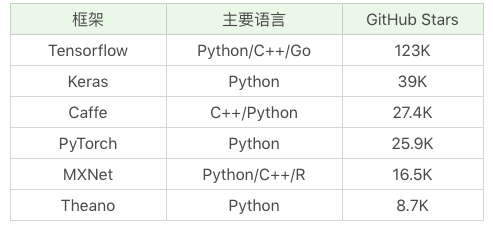
Tensorflow 是 Google 出品,也是深度学习最常用的库。
关于 Keras,可以理解成是把 Tensorflow 或 Theano 作为后端,基于它们提供的封装接口,这样更方便操作使用。
如果刚进入深度学习这个领域,更建议直接使用 Keras,因为它使用方便,更加友好,可以方便快速构建网络模型,不需要过多关注底层细节。
用 Keras 做 Mnist 手写数字识别
Keras 需要用 tensorflow 或者 theano 作为后端,因此需要引入相关的工具。同时还需要注意采用最新的 NumPy 版本才能正常运行 keras
pip install keras
pip install tensorflow创建一个 Sequential 序贯模型,它的作用是将多个网络层线性堆叠起来
from keras.models import Sequential
model = Sequential()创建二维卷积层
使用 Conv2D(filters, kernel_size, activation=None) 进行创建, 其中 filters 代表卷积核的数量,kernel_size 代表卷积核的宽度和长度,activation 代表激活函数。如果创建的二维卷积层是第一个卷积层,我们还需要提供 input_shape 参数,比如:input_shape=(28, 28, 1) 代表的就是 28*28 的灰度图像。
对 2D 信号做最大池化层
使用 MaxPooling2D(pool_size=(2, 2)) 进行创建,其中 pool_size 代表下采样因子,比如 pool_size=(2,2) 的时候相当于将原来 22 的矩阵变成一个点,即用 22 矩阵中的最大值代替,输出的图像在长度和宽度上均为原图的一半。
创建 Flatten 层
使用 Flatten() 创建,常用于将多维的输入扁平化,也就是展开为一维的向量。一般用在卷积层与全连接层之间,方便后面进行全连接层的操作。
创建全连接层
使用 Dense(units, activation=None) 进行创建,其中 units 代表的是输出的空间维度,activation 代表的激活函数。
# 使用LeNet模型对Mnist手写数字进行识别
import keras
from keras.datasets import mnist
from keras.layers import Conv2D, MaxPooling2D
from keras.layers import Dense, Flatten
from keras.models import Sequential
# 数据加载
(train_x, train_y), (test_x, test_y) = mnist.load_data()
# 输入数据为 mnist 数据集
train_x = train_x.reshape(train_x.shape[0], 28, 28, 1)
test_x = test_x.reshape(test_x.shape[0], 28, 28, 1)
train_x = train_x / 255
test_x = test_x / 255
train_y = keras.utils.to_categorical(train_y, 10)
test_y = keras.utils.to_categorical(test_y, 10)
# 创建序贯模型
model = Sequential()
# 第一层卷积层:6个卷积核,大小为5∗5, relu激活函数
model.add(Conv2D(6, kernel_size=(5, 5), activation='relu', input_shape=(28, 28, 1)))
# 第二层池化层:最大池化
model.add(MaxPooling2D(pool_size=(2, 2)))
# 第三层卷积层:16个卷积核,大小为5*5,relu激活函数
model.add(Conv2D(16, kernel_size=(5, 5), activation='relu'))
# 第二层池化层:最大池化
model.add(MaxPooling2D(pool_size=(2, 2)))
# 将参数进行扁平化,在LeNet5中称之为卷积层,实际上这一层是一维向量,和全连接层一样
model.add(Flatten())
model.add(Dense(120, activation='relu'))
# 全连接层,输出节点个数为84个
model.add(Dense(84, activation='relu'))
# 输出层 用softmax 激活函数计算分类概率
model.add(Dense(10, activation='softmax'))
# 设置损失函数和优化器配置
model.compile(loss=keras.metrics.categorical_crossentropy, optimizer=keras.optimizers.Adam(), metrics=['accuracy'])
# 传入训练数据进行训练
model.fit(train_x, train_y, batch_size=128, epochs=2, verbose=1, validation_data=(test_x, test_y))
# 对结果进行评估
score = model.evaluate(test_x, test_y)
print('误差:%0.4lf' %score[0])
print('准确率:', score[1])运行结果:
……(省略中间迭代的结算结果,即显示每次迭代的误差loss和准确率acc)
误差:0.0699
准确率: 0.9776

















 45万+
45万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









