







问题
1. 等级泄露(Rank Leak):如果一个网页没有出链,就像是一个黑洞一样,吸收了其他网页的影响力而不释放,最终会导致其他网页的 PR 值为 0。
2. 等级沉没(Rank Sink):如果一个网页只有出链,没有入链,计算的过程迭代下来,会导致这个网页的 PR 值为 0(也就是不存在公式中的 V)。
对策
PageRank 的随机浏览模型,假设用户并不都是按照跳转链接的方式来上网,还有可能直接输入网址访问其他页面。
定义一个阻尼因子 d,这个因子代表了用户按照跳转链接来上网的概率,通常可以取一个固定值 0.85,而 1-d=0.15 则代表了用户不是通过跳转链接的方式来访问网页的,比如直接输入网址。
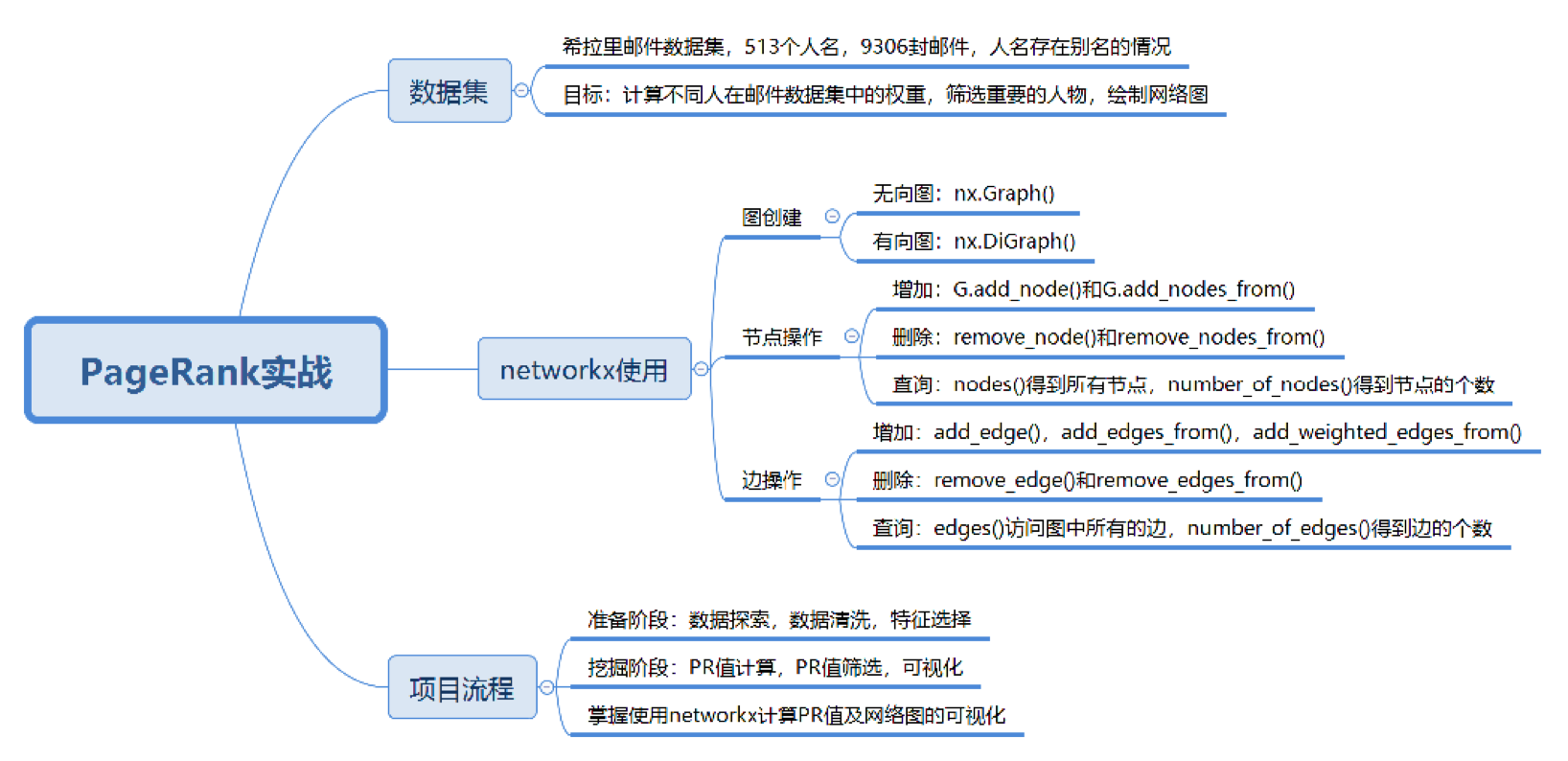
实例:用 PageRank 揭秘希拉里邮件中的人物关系
import os
import numpy as np
import pandas as pd
import networkx as nx
from collections import defaultdict
import matplotlib.pyplot as plt
class PageRank():
def __init__(self, root_path):
self.root_path = root_path
# print(self.root_path)
self.aliases = {}
self.persons = {}
def unify_name(self, name):
name = str(name).lower()
name = name.replace(',', '').split('@')[0]
if name in self.aliases.keys():
return self.persons[self.aliases[name]]
return name
def load_file(self):
file = pd.read_csv(os.path.join(self.root_path, 'input/Aliases.csv'))
for index, row in file.iterrows():
# print(index, row)
self.aliases[row['Alias']] = row['PersonId']
file = pd.read_csv(os.path.join(self.root_path, 'input/Persons.csv'))
for index, row in file.iterrows():
self.persons[row['Id']] = row['Name']
# 将寄件人和收件人的姓名进行规范化
emails = pd.read_csv(os.path.join(self.root_path, 'input/Emails.csv'))
emails.MetadataFrom = emails.MetadataFrom.apply(self.unify_name)
emails.MetadataTo = emails.MetadataTo.apply(self.unify_name)
# 设置边的权重等于发邮件的次数
edges_weights_temp = defaultdict(list)
for row in zip(emails.MetadataFrom, emails.MetadataTo, emails.RawText):
temp = (row[0], row[1])
if temp not in edges_weights_temp:
edges_weights_temp[temp] = 1
else:
edges_weights_temp[temp] = edges_weights_temp[temp] + 1
edges_weights = [(key[0], key[1], val) for key, val in edges_weights_temp.items()]
self.draw_graph(edges_weights)
def draw_graph(self, edges_weights):
# 创建有向图
graph = nx.DiGraph()
# 设置有向图中的路径及权重 (from, to, weight)
graph.add_weighted_edges_from(edges_weights)
# 计算每个节点(人)的 PR 值,并作为节点的 pagerank 属性
pagerank = nx.pagerank(graph)
# 将 pagerank 数值作为节点的属性
nx.set_node_attributes(graph, name='pagerank', values=pagerank)
self.show_graph(graph)
# 将完整的图谱进行精简
# 设置 PR 值的阈值,筛选大于阈值的重要核心节点
pagerank_threshold = 0.005
small_graph = graph.copy()
for n, p_rank in graph.nodes(data=True):
if p_rank['pagerank'] < pagerank_threshold:
small_graph.remove_node(n)
self.show_graph(small_graph, 'circular_layout')
def show_graph(self, graph, layout='spring_layout'):
if layout == 'circular_layout':
positions = nx.circular_layout(graph)
else:
positions = nx.spring_layout(graph)
# 设置网络图中的节点大小,大小与 pagerank 值相关,因为 pagerank 值很小所以需要 *20000
nodesize = [x['pagerank'] * 20000 for v, x in graph.nodes(data=True)]
# 设置网络图中的边长度
edgesize = [np.sqrt(e[2]['weight']) for e in graph.edges(data=True)]
# 绘制节点
nx.draw_networkx_nodes(graph, positions, node_size=nodesize, alpha=0.4)
# 绘制边
nx.draw_networkx_edges(graph, positions, edge_size=edgesize, alpha=0.2)
# 绘制节点的 label
nx.draw_networkx_labels(graph, positions, font_size=10)
plt.show()
if __name__ == '__main__':
root = r'C:\My_data\Study\数据分析实战\PageRank-master'
run_pagerank = PageRank(root)
run_pagerank.load_file()

















 567
567

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









