




 本文详细介绍了LDA主题模型,从整体脉络到原理解析,包括确定最佳主题个数的方法,使用Gensim构建LDA模型的步骤,以及主题演化和动态主题模型的实践。探讨了如何通过困惑度和主题一致性来选择主题个数,并提供了相关代码资源和参考资料。
本文详细介绍了LDA主题模型,从整体脉络到原理解析,包括确定最佳主题个数的方法,使用Gensim构建LDA模型的步骤,以及主题演化和动态主题模型的实践。探讨了如何通过困惑度和主题一致性来选择主题个数,并提供了相关代码资源和参考资料。
近期做了一个关于主题分析的重新学习,感觉只看不实操真的就和白学了一样。也趁着这股劲把关于LDA主题模型的东西总结一下,这些是目前我能够考虑到的所有事情,以后看到再做补充(新手小白请指正我的错误,十分感谢!!)。总结学习使我进步!!
一、整体脉络
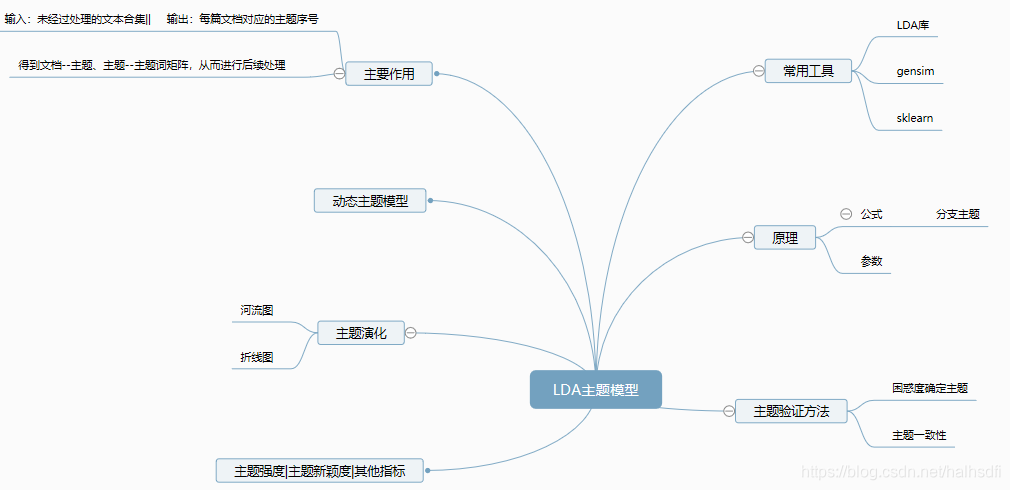
二、原理解析
LDA也称为隐狄利克雷分布,LDA的目的就是要识别主题,即把文档—词汇矩阵变成文档—主题矩阵(分布)和主题—词汇矩阵(分布)。
地址: https://www.cnblogs.com/pinard/p/6831308.html
三、确定最佳主题个数
对数据进行主题分类之前要先确定可以划分的最佳主题个数,其他的参数简单的做可以直接选择默认值。用困惑度来做的话,是困惑度的值最小或者是在拐点处的值最好;用主题一致性的话就是越靠近越好,还是要看应用效果好不好最后再做选择,有时候在一个值附近选取效果不会相差太多。(该部分的内容都是基于gensim包的)
代码地址:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









