




导读
阿里SIM基于搜索的兴趣模型,采用两阶段搜索机制,能处理超长用户行为序列,并将长期序列用户行为数据建模的最大长度推进到 54000。该模型已在阿里的展示广告系统中作为主模型部署,带来了 7.1% 的 CTR 提升和 4.4% 的 RPM 提升。
摘要
丰富的用户行为数据已被证明在点击率预测任务中具有巨大价值,特别是在推荐系统和在线广告等工业应用中。工业界和学术界都非常关注这一话题,并提出了不同的方法来建模长期序列用户行为数据。其中,阿里巴巴提出的基于记忆网络的模型 MIMN[8] 通过学习算法和服务系统的共同设计实现了 SOTA。MIMN 是第一个可以对长度扩展到 1000 的序列用户行为数据进行建模的工业解决方案。然而,当用户行为序列长度进一步增加(例如增加 10 倍或更多)时,MIMN 无法准确捕捉特定候选项目的用户兴趣。这一挑战在先前提出的方法中普遍存在。
在本文中,我们通过设计一种新的建模范式来解决这个问题,我们称之为基于搜索的兴趣模型(Search-based Interest Model,SIM)。SIM 通过两个级联的搜索单元提取用户兴趣:(i)通用搜索单元(General Search Unit,GSU)从原始且任意长的序列行为数据中进行一般搜索,根据候选项目的查询信息获取与候选项目相关的子用户行为序列(Sub user Behavior Sequence,SBS);(ii)精确搜索单元(Exact Search Unit,ESU)建模候选项目和 SBS 之间的精确关系。这种级联搜索范式使 SIM 在可扩展性和准确性方面具有更好的建模长期序列行为数据的能力。除了学习算法之外,我们还介绍了如何在大规模工业系统中实现 SIM 的实践经验。自 2019 年以来,SIM 已在阿里巴巴的展示广告系统中部署,带来了 7.1% 的点击率提升和 4.4% 的 RPM 提升,这对业务具有重要意义。现在在我们的真实系统中,SIM 建模的序列用户行为数据的最大长度达到 54000,将 SOTA 推进到 54 倍。
1 引言
点击率(Click-Through Rate,CTR)预测建模在推荐系统和在线广告等工业应用中起着至关重要的作用。由于用户历史行为数据的快速增长,用户兴趣建模(聚焦于学习用户兴趣的意图表示)已经广泛引入到 CTR 预测模型中[2, 8, 19, 20]。然而,大多数提出的方法只能对长度扩展到数百的序列用户行为数据进行建模,受限于真实在线系统中的计算和存储负担[19, 20]。丰富的用户行为数据被证明具有巨大价值[8]。例如,全球领先的电子商务网站之一淘宝网有 23% 的用户在过去 5 个月内点击了超过 1000 个产品[8, 10]。如何设计一种可行的解决方案来建模长期序列用户行为数据一直是一个开放且热门的话题,吸引了来自工业界和学术界的研究人员。
一部分研究借鉴了自然语言处理(NLP)领域的思想,提出使用记忆网络来建模长期序列用户行为数据,并取得了一些突破。阿里巴巴提出的 MIMN[8] 是一个典型的工作,通过学习算法和服务系统的共同设计实现了 SOTA。MIMN 是第一个可以对长度扩展到 1000 的序列用户行为数据进行建模的工业解决方案。具体来说,MIMN 将一个用户的多样兴趣逐步嵌入到一个固定大小的记忆矩阵中,并通过每个新行为进行更新。这样,用户建模的计算与 CTR 预测解耦。因此,对于在线服务,延迟将不再是问题,存储成本取决于记忆矩阵的大小,这远小于原始行为序列。在长期兴趣建模中也可以找到类似的思想[10]。然而,对于基于记忆网络的方法来说,建模任意长的序列数据仍然具有挑战性。实际上,我们发现当用户行为序列长度进一步增加(例如达到 10000 或更多)时,MIMN 无法准确捕捉特定候选项目的用户兴趣。这是因为将所有用户历史行为编码到一个固定大小的记忆矩阵中会导致记忆单元中包含大量噪声。
另一方面,正如 DIN[20] 先前工作中指出的那样,用户的兴趣是多样的,并且在面对不同的候选项目时会有所变化。DIN 的关键思想是从用户行为中搜索有效信息,以建模用户面对不同候选项目的特殊兴趣。通过这种方式,我们可以解决将所有用户兴趣编码到固定大小参数中的挑战。DIN 确实为使用用户行为数据进行 CTR 建模带来了很大改进。但如上所述,DIN 的搜索公式在面对长期序列用户行为数据时产生了不可接受的计算和存储成本。那么,我们能否应用类似的搜索技巧并设计一种更有效的方法,从长期序列用户行为数据中提取知识呢?
在本文中,我们通过设计一种新的建模范式来解决这个挑战,我们称之为基于搜索的兴趣模型(Search-based Interest Model,SIM)。SIM 采用 DIN[20] 的思想,并仅捕捉与特定候选项目相关的用户兴趣。在 SIM 中,用户兴趣通过两个级联的搜索单元提取:(i)通用搜索单元(General Search Unit,GSU)从原始且任意长的序列行为数据中进行一般搜索,根据候选项目的查询信息获取与候选项目相关的子用户行为序列(Sub user Behavior Sequence,SBS)。为了满足严格的延迟和计算资源限制,GSU 中采用了通用但有效的方法。根据我们的经验,SBS 的长度可以减少到数百,并且大多数原始长期序列行为数据中的噪声信息可以被过滤。(ii)精确搜索单元(Exact Search Unit,ESU)建模候选项目和 SBS 之间的精确关系。在这里,我们可以轻松应用 DIN[20] 或 DIEN[19] 提出的类似方法。
本文的主要贡献总结如下:
- 我们提出了一种新的范式 SIM,用于建模长期序列用户行为数据。级联的两阶段搜索机制的设计使 SIM 在可扩展性和准确性方面具有更好的建模长期序列行为数据的能力。
- 我们介绍了在大规模工业系统中实现 SIM 的实践经验。自 2019 年以来,SIM 已在阿里巴巴的展示广告系统中部署,带来了 7.1% 的 CTR 提升和 4.4% 的 RPM 提升。现在,SIM 正在服务主要流量。
- 我们将长期序列用户行为数据建模的最大长度推进到 54000,是 MIMN(该任务的已发布 SOTA 工业解决方案)的 54 倍。
2 相关工作
用户兴趣模型
基于深度学习的方法在点击率(CTR)预测任务中取得了巨大的成功[1, 11, 18]。在早期,大多数先锋工作[1, 4, 7, 9, 15]使用深度神经网络来捕捉来自不同领域的特征之间的交互,从而使工程师摆脱了繁琐的特征工程工作。最近,一系列我们称之为用户兴趣模型的工作,专注于使用不同的神经网络架构(如 CNN[14, 17]、RNN[5, 19]、Transformer[3, 13] 和 Capsule[6] 等)从历史行为中学习潜在用户兴趣的表示。DIN[20] 强调用户兴趣是多样的,并在 DIN 中引入了注意力机制,以捕捉用户对不同目标项目的多样兴趣。DIEN[19] 指出历史行为之间的时间关系对于建模用户的兴趣漂移至关重要。DIEN 设计了一个基于 GRU 的兴趣提取层,并辅以辅助损失。MIND[6] 认为使用单个向量来表示一个用户不足以捕捉用户兴趣的变化特性。MIND 引入了胶囊网络和动态路由方法,将用户兴趣表示为多个向量。此外,受序列到序列学习任务中自注意力架构成功的启发,[3] 引入了 Transformer 来建模用户的跨会话和会话内兴趣。
长期用户兴趣
[8] 表明在用户兴趣模型中考虑长期历史行为序列可以显著提高 CTR 模型的性能。尽管较长的用户行为序列为用户兴趣建模带来了更多有用的信息,但它极大地增加了在线服务系统的延迟和存储负担,同时为点对点的 CTR 预测带来了大量噪声。一系列工作专注于解决长期用户兴趣建模中的挑战,通常基于极长甚至终生的历史行为序列学习用户兴趣表示。[10] 提出了一个分层周期记忆网络,用于个性化地记忆每个用户的顺序模式,从而进行终生的序列建模。[16] 选择了一个基于注意力的框架来结合用户的长期和短期偏好,并采用了注意力非对称 SVD 范式来建模长期兴趣。[8] 提出了一种基于记忆的架构 MIMN,该架构将用户的长期兴趣嵌入到固定大小的记忆网络中,以解决用户行为数据的大存储问题。同时,设计了一个 UIC 模块来逐步记录新的用户行为,以应对延迟限制。但 MIMN 在记忆网络中放弃了目标项的信息,而目标项的信息已被证明对用户兴趣建模非常重要。
3 基于搜索的兴趣模型
通过对用户行为数据进行建模来预测点击率(CTR)已被证明是有效的。通常,基于注意力机制的 CTR 模型,如 DIN[20] 和 DIEN[19],设计了复杂的模型结构,并引入注意力机制,通过从用户行为序列中搜索有效信息来捕捉用户的多样兴趣,并处理来自不同候选项的输入。然而,在实际系统中,这些模型只能处理短期行为序列数据,其长度通常小于 150。另一方面,长期用户行为数据是有价值的,建模用户的长期兴趣可能会为用户带来更多样的推荐结果。我们似乎陷入了两难境地:在实际系统中,我们无法用有效但复杂的方法处理有价值的终生用户行为数据。
为了解决这一挑战,我们提出了一种新的建模范式,称为基于搜索的兴趣模型(SIM)。SIM 采用两阶段搜索策略,能够高效地处理长用户行为序列。在本节中,我们将首先介绍 SIM 的整体工作流程,然后详细介绍提出的两个搜索单元。
3.1 整体工作流程
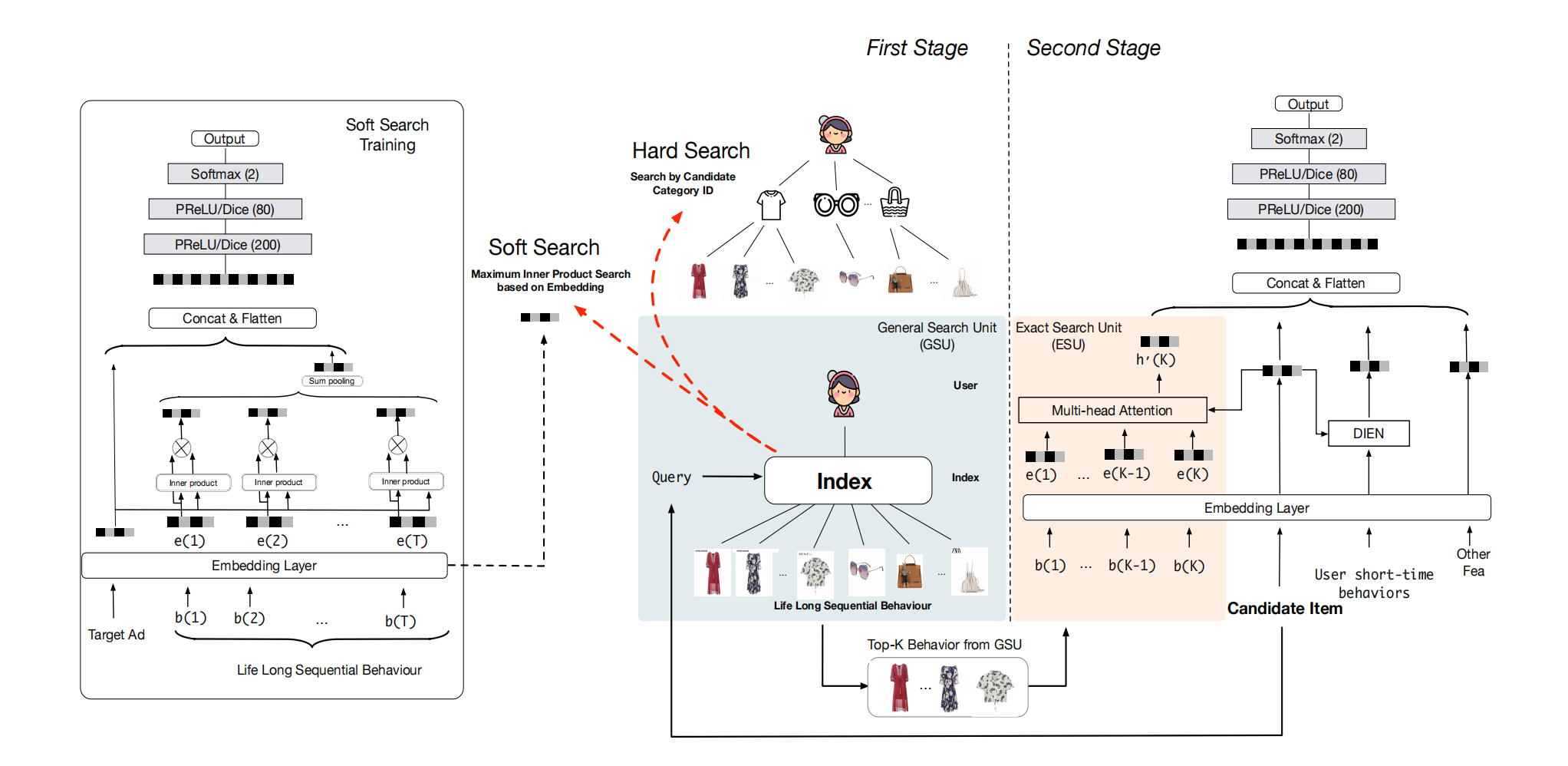
图 1:基于搜索的兴趣模型(SIM)。SIM 采用两阶段搜索策略,由两个单元组成:(i) 通用搜索单元(GSU)从超过一万条用户行为中寻找最相关的 K 个行为;(ii) 精确搜索单元(ESU)利用多头注意力机制捕捉多样的用户兴趣。然后,它遵循传统的嵌入和多层感知器(Embedding&MLP)范式,将精确的长期用户兴趣输出和其他特征作为输入。在本文中,我们介绍了 GSU 的硬搜索和软搜索。硬搜索指的是选择与候选项属于同一类别的行为数据。软搜索指的是基于嵌入向量对每个用户行为数据进行索引,并使用最大内积搜索来寻找 Top-K 行为。对于软搜索,GSU 和 ESU 共享相同的嵌入参数,这些参数在学习过程中同时训练,Top-K 行为序列基于最新的参数生成。
SIM 的整体工作流程如图 1 所示。SIM 采用级联的两阶段搜索策略,对应的两个单元是:通用搜索单元(GSU)和精确搜索单元(ESU)。在第一阶段,我们利用通用搜索单元(GSU)从原始的长期行为序列中以次线性时间复杂度(sub-linear time complexity)寻找前 K 个相关的子行为序列。这里的 K 通常远小于行为序列的原始长度。如果相关行为可以在时间和计算资源的限制下被搜索到,那么就可以进行高效的搜索方法。在第 3.2 节中,我们提供了 GSU 的两种简单实现:软搜索和硬搜索。GSU 采用了一种通用但有效的策略来截断原始序列行为的长度,以满足严格的时间和计算资源限制。同时,存在于长期用户行为序列中的大量噪声信息可能会破坏用户兴趣建模,可以在第一阶段通过搜索策略进行过滤。
在第二阶段,精确搜索单元(ESU)以过滤后的子序列用户行为为输入,进一步捕捉精确的用户兴趣。此处可以应用复杂架构的精细模型,如 DIN[20] 和 DIEN[19],因为长期行为的长度已减少到数百。
需要注意的是,尽管我们分别介绍了这两个阶段,但实际上它们是一起训练的。
3.2 通用搜索单元
给定一个候选项(即 CTR 模型将评分的目标项),只有一部分用户行为是有价值的。这部分用户行为与最终用户决策密切相关。挑选出这些相关的用户行为有助于用户兴趣建模。然而,直接使用整个用户行为序列来建模用户兴趣会带来巨大的资源使用和响应延迟,这在实际应用中通常是不可接受的。
为此,我们提出了一个通用搜索单元,以减少用户兴趣建模中用户行为的输入数量。这里我们介绍两种通用搜索单元:硬搜索和软搜索。
给定用户行为列表 B=[b1,b2,…,bT]B = [b_1, b_2, \ldots, b_T]B=[b1,b2,…,bT],其中 bib_ibi 是第 iii 个用户行为,TTT 是用户行为的长度。通用搜索单元计算每个行为 bib_ibi 相对于候选项的相关评分 rir_iri,然后选择评分 rir_iri 最高的前 KKK 个相关行为作为子行为序列 B∗B^*B∗。硬搜索和软搜索的区别在于相关评分 rir_iri 的公式:
ri={ Sign(Ci=Ca)硬搜索(Wbei)⊙(Waea)T软搜索 r_i = \begin{cases} \text{Sign}(C_i = C_a) & \text{硬搜索} \\ (W_b e_i) \odot (W_a e_a)^T & \text{软搜索} \end{cases} ri={ Sign(Ci=Ca)(Wbei)⊙(Waea)T硬搜索软搜索
硬搜索。硬搜索模型是非参数的。只有属于与候选项相同类别的行为才会被选中并聚合为子行为序列,发送到精确搜索单元。这里 CaC_aC
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1235
1235

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









