







SSD目标检测
模型简介
SSD,全称Single Shot MultiBox Detector,是Wei Liu在ECCV 2016上提出的一种目标检测算法。使用Nvidia Titan X在VOC 2007测试集上,SSD对于输入尺寸300x300的网络,达到74.3%mAP(mean Average Precision)以及59FPS;对于512x512的网络,达到了76.9%mAP ,超越当时最强的Faster RCNN(73.2%mAP)。具体可参考论文[1]。
SSD目标检测主流算法分成可以两个类型:
-
two-stage方法:RCNN系列
通过算法产生候选框,然后再对这些候选框进行分类和回归。
-
one-stage方法:YOLO和SSD
直接通过主干网络给出类别位置信息,不需要区域生成。
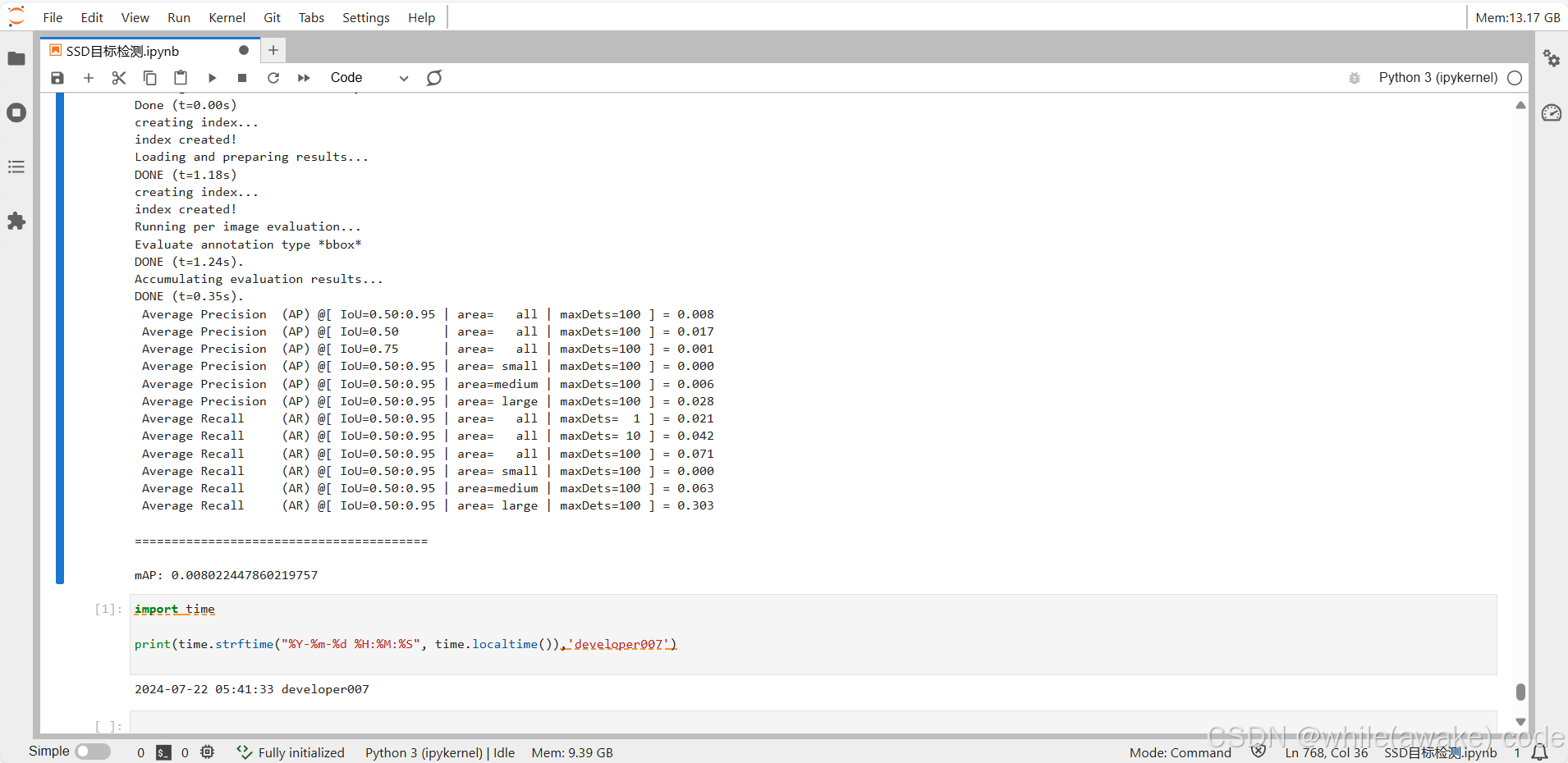
SSD是单阶段的目标检测算法,通过卷积神经网络进行特征提取,取不同的特征层进行检测输出,所以SSD是一种多尺度的检测方法。在需要检测的特征层,直接使用一个3 × \times × 3卷积,进行通道的变换。SSD采用了anchor的策略,预设不同长宽比例的anchor,每一个输出特征层基于anchor预测多个检测框(4或者6)。采用了多尺度检测方法,浅层用于检测小目标,深层用于检测大目标。SSD的框架如下图:
模型结构
SSD采用VGG16作为基础模型,然后在VGG16的基础上新增了卷积层来获得更多的特征图以用于检测。SSD的网络结构如图所示。上面是SSD模型,下面是YOLO模型,可以明显看到SSD利用了多尺度的特征图做检测。
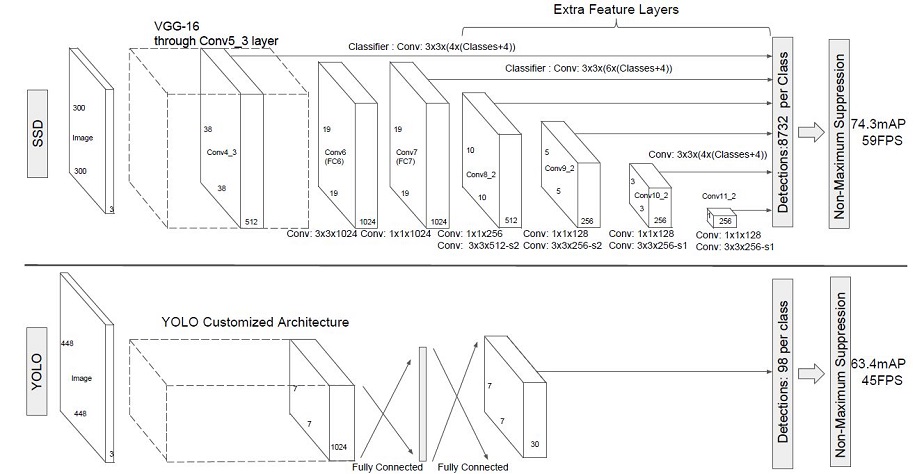
两种单阶段目标检测算法的比较:
SSD先通过卷积不断进行特征提取,在需要检测物体的网络,直接通过一个3 × \times × 3卷积得到输出,卷积的通道数由anchor数量和类别数量决定,具体为(anchor数量*(类别数量+4))。
SSD对比了YOLO系列目标检测方法,不同的是SSD通过卷积得到最后的边界框,而YOLO对最后的输出采用全连接的形式得到一维向量,对向量进行拆解得到最终的检测框。
模型特点
-
多尺度检测
在SSD的网络结构图中我们可以看到,SSD使用了多个特征层,特征层的尺寸分别是38 × \times × 38,19 × \times × 19,10 × \times × 10,5 × \times × 5,3 × \times × 3,1 × \times × 1,一共6种不同的特征图尺寸。大尺度特征图(较靠前的特征图)可以用来检测小物体,而小尺度特征图(较靠后的特征图)用来检测大物体。多尺度检测的方式,可以使得检测更加充分(SSD属于密集检测),更能检测出小目标。
-
采用卷积进行检测
与YOLO最后采用全连接层不同,SSD直接采用卷积对不同的特征图来进行提取检测结果。对于形状为m × \times × n × \times × p的特征图,只需要采用3 × \times × 3 × \times × p这样比较小的卷积核得到检测值。
-
预设anchor
在YOLOv1中,直接由网络预测目标的尺寸,这种方式使得预测框的长宽比和尺寸没有限制,难以训练。在SSD中,采用预设边界框,我们习惯称它为anchor(在SSD论文中叫default bounding boxes),预测框的尺寸在anchor的指导下进行微调。
环境准备
本案例基于MindSpore实现,开始实验前,请确保本地已经安装了mindspore、download、pycocotools、opencv-python。
%%capture captured_output
# 实验环境已经预装了mindspore==2.2.14,如需更换mindspore版本,可更改下面mindspore的版本号
!pip uninstall mindspore -y
!pip install -i https://pypi.mirrors.ustc.edu.cn/simple mindspore==2.2.14
# 查看当前 mindspore 版本
!pip show mindspore
!pip install -i https://pypi.mirrors.ustc.edu.cn/simple pycocotools==2.0.7
数据准备与处理
本案例所使用的数据集为COCO 2017。为了更加方便地保存和加载数据,本案例中在数据读取前首先将COCO数据集转换成MindRecord格式。使用MindSpore Record数据格式可以减少磁盘IO、网络IO开销,从而获得更好的使用体验和性能提升。
首先我们需要下载处理好的MindRecord格式的COCO数据集。
运行以下代码将数据集下载并解压到指定路径。
from download import download
dataset_url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/ssd_datasets.zip"
path = "./"
path = download(dataset_url, path, kind="zip", replace=True)
然后我们为数据处理定义一些输入:
coco_root = "./datasets/"
anno_json = "./datasets/annotations/instances_val2017.json"
train_cls = ['background', 'person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus',
'train', 'truck', 'boat', 'traffic light', 'fire hydrant',
'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog',
'horse', 'sheep', 'cow', 'elephant', 'bear', 'zebra',
'giraffe', 'backpack', 'umbrella', 'handbag', 'tie',
'suitcase', 'frisbee', 'skis', 'snowboard', 'sports ball',
'kite', 'baseball bat', 'baseball glove', 'skateboard',
'surfboard', 'tennis racket', 'bottle', 'wine glass', 'cup',
'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple',
'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza',
'donut', 'cake', 'chair', 'couch', 'potted plant', 'bed',
'dining table', 'toilet', 'tv', 'laptop', 'mouse', 'remote',
'keyboard', 'cell phone', 'microwave', 'oven', 'toaster', 'sink',
'refrigerator', 'book', 'clock', 'vase', 'scissors',
'teddy bear', 'hair drier', 'toothbrush']
train_cls_dict = {
}
for i, cls in enumerate(train_cls):
train_cls_dict[cls] = i
数据采样
为了使模型对于各种输入对象大小和形状更加鲁棒,SSD算法每个训练图像通过以下选项之一随机采样:
-
使用整个原始输入图像
-
采样一个区域,使采样区域和原始图片最小的交并比重叠为0.1,0.3,0.5,0.7或0.9
-
随机采样一个区域
每个采样区域的大小为原始图像大小的[0.3,1],长宽比在1/2和2之间。如果真实标签框中心在采样区域内,则保留两者重叠部分作为新图片的真实标注框。在上述采样步骤之后,将每个采样区域大小调整为固定大小,并以0.5的概率水平翻转。
import cv2
import numpy as np
def _rand(a=0., b=1.):
return np.random.rand() * (b - a) + a
def intersect(box_a, box_b):
"""Compute the intersect of two sets of boxes."""
max_yx = np.minimum(box_a[:, 2:4], box_b[2:4])
min_yx = np.maximum(box_a[:, :2], box_b[:2])
inter = np.clip((max_yx - min_yx), a_min=0, a_max=np.inf)
return inter[:, 0] * inter[:, 1]
def jaccard_numpy(box_a, box_b):
"""Compute the jaccard overlap of two sets of boxes."""
inter = intersect(box_a, box_b)
area_a = ((box_a[:, 2] - box_a[:, 0]) *
(box_a[:, 3] - box_a[:, 1]))
area_b = ((box_b[2] - box_b[0]) *
(box_b[3] - box_b[1]))
union = area_a + area_b - inter
return inter / union
def random_sample_crop(image, boxes):
"""Crop images and boxes randomly."""
height, width, _ = image.shape
min_iou = np.random.choice([None, 0.1, 0.3, 0.5, 0.7, 0.9])
if min_iou is None:
return image, boxes
for _ in range(50):
image_t = image
w = _rand(0.3, 1.0) * width
h = _rand(0.3, 1.0) * height
# aspect ratio constraint b/t .5 & 2
if h / w < 0.5 or h / w > 2:
continue
left = _rand() * (width - w)
top = _rand() * (height - h)
rect = np.array([int(top), int(left), int(top + h), int(left + w)])
overlap = jaccard_numpy(boxes, rect)
# dropout some boxes
drop_mask = overlap > 0
if not drop_mask.any():
continue
if overlap[drop_mask].min() < min_iou and overlap[drop_mask].max() > (min_iou + 0.2):
continue
image_t = image_t[rect[0]:rect[2], rect[1]:rect[3], :]
centers = (boxes[:, :2] + boxes[:, 2:4]) / 2.0
m1 = (rect[0] < centers[:, 0]) * (rect[1] < centers[:, 1])
m2 = (rect[2] > centers[:, 0]) * (rect[3] > centers[:, 1])
# mask in that both m1 and m2 are true
mask = m1 * m2 * drop_mask
# have any valid boxes? try again if not
if not mask.any():
continue
# take only matching gt boxes
boxes_t = boxes[mask, :].copy()
boxes_t[:, :2] = np.maximum(boxes_t[:, :2], rect[:2])
boxes_t[:, :2] -= rect[:2]
boxes_t[:, 2:4] = np.minimum(boxes_t[:, 2:4], rect[2:4])
boxes_t[:, 2:4] -= rect[:2]
return image_t, boxes_t
return image, boxes
def ssd_bboxes_encode(boxes):
"""Labels anchors with ground truth inputs."""
def jaccard_with_anchors(bbox):
"""Compute jaccard score a box and the anchors."""
# Intersection bbox and volume.
ymin = np.maximum(y1, bbox[0])
xmin = np.maximum(x1, bbox[1])
ymax = np.minimum(y2, bbox[2])
xmax = np.minimum(x2, bbox[3])
w = np.maximum(xmax - xmin, 0.)
h = np.maximum(ymax - ymin, 0.)
# Volumes.
inter_vol = h * w
union_vol = vol_anchors + (bbox[2] - bbox[0]) * (bbox[3] - bbox[1]) - inter_vol
jaccard = inter_vol / union_vol
return np.squeeze(jaccard)
pre_scores = np.zeros((8732), dtype=np.float32)
t_boxes = np.zeros((8732, 4), dtype=np.float32)
t_label = np.zeros((8732), dtype=np.int64)
for bbox in boxes:
label = int(bbox[4])
scores = jaccard_with_anchors(bbox)
idx = np.argmax(scores)
scores[idx] = 2.0
mask = (scores > matching_threshold)
mask = mask & (scores > pre_scores)
pre_scores = np.maximum(pre_scores, scores * mask)
t_label = mask * label + (1 - mask) * t_label
for i in range(4):
t_boxes[:, i] = mask * bbox[i] + (1 - mask) * t_boxes[:, i]
index = np.nonzero(t_label)
# Transform to tlbr.
bboxes = np.zeros((8732, 4), dtype=np.float32)
bboxes[:, [0, 1]] = (t_boxes[:, [0, 1]] + t_boxes[:, [2, 3]]) / 2
bboxes[:, [2, 3]] = t_boxes[:, [2, 3]] - t_boxes[:, [0, 1]]
# Encode features.
bboxes_t = bboxes[index]
default_boxes_t = default_boxes[index]
bboxes_t[: 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









