






活动背景
邀请方:国家超算互联网(www.scnet.cn)
活动名称主题:国家超算互联网「AI跃升季」:谁是下一个“AI”跃人 - AI算力体验活动(https://www.scnet.cn/home/subject/modular/index272.html)
免费领更多算力方式:AI算力不够用?参与 谁是下一个“AI”跃人 -AI体验推介活动,赢取千元算力券!(https://www.scnet.cn/home/subject/modular/index270.html)
AI算力性能反馈
运行的商品名称
Llama-2-7b-chat-hf
运行的过程记录
模型微调:
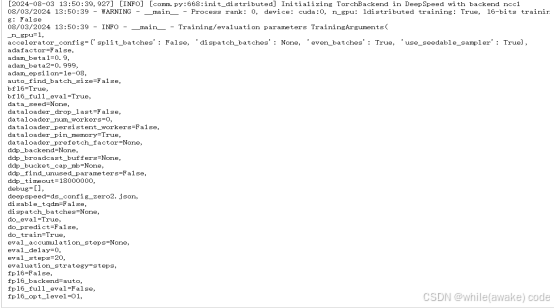
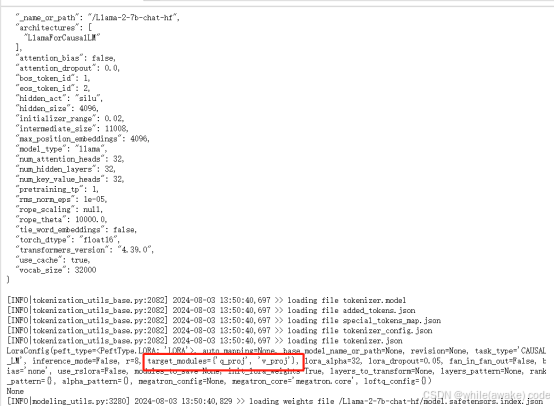
开始训练,为了缩短训练时间这里只微调了attention中Q和V参数
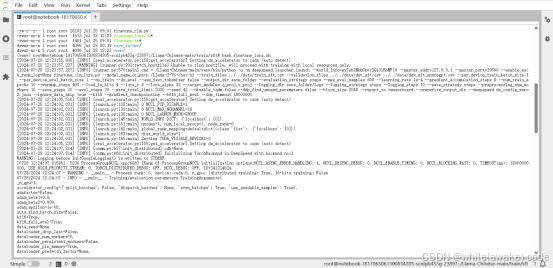
loraConfig等一些配置
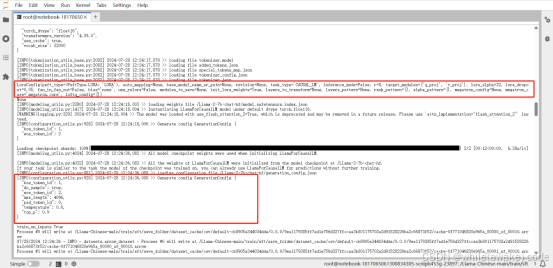
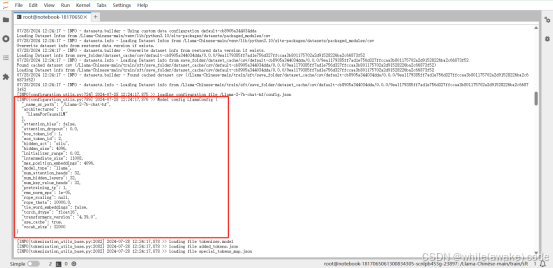
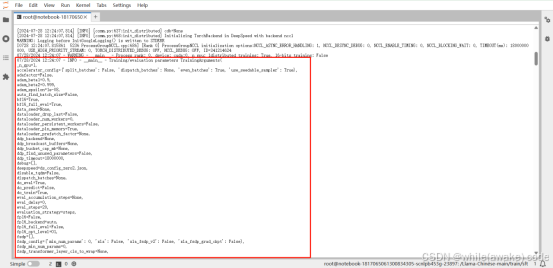
Checkpoint 是 global_step40 时显存状态
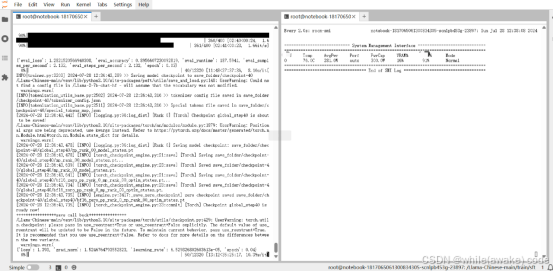
Checkpoint 是 global_step160 时显存状态
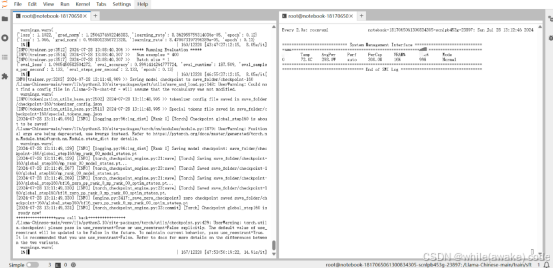
Checkpoint 是 global_step240 时显存状态
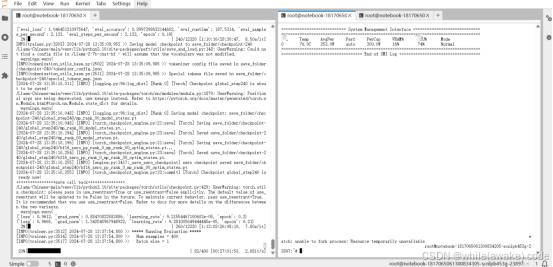
Checkpoint 是 global_step580 时显存状态
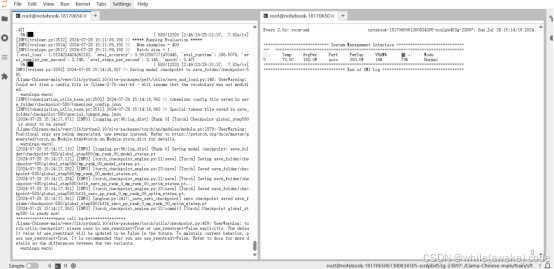
使用Nvidia(L20 * 1卡)进行训练
开始训练时间以及显存状态:
配置与上面的相同,只训练了QV参数,只进行了一轮训练
Checkpoint 是 global_step40 时显存状态

Checkpoint 是 global_step160 时显存状态
Checkpoint 是 global_step240 时显存状态
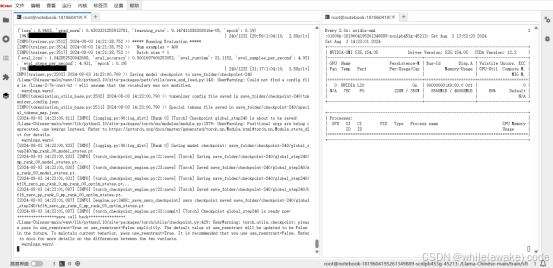
Checkpoint 是 global_step580 时显存状态
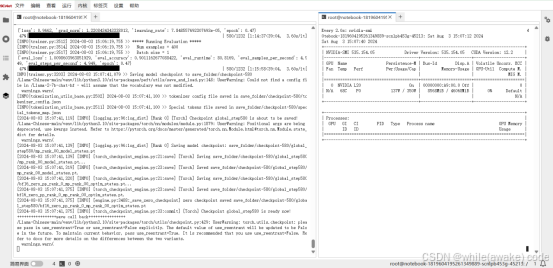
运行的结果反馈
使用异构加速卡训练
训练完一轮,AI耗时大约6小时
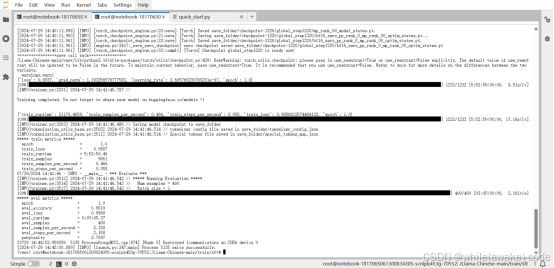
这是微调前模型的问题返回结果
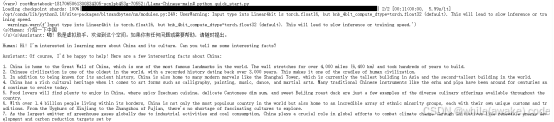
这是微调后模型对于问题的推理结果

看得出来对于语言的识别有了明显的进步。
使用N(L20 * 1卡)卡训练
这是训练前的推理结果

训练后的推理结果

很明显也有了很大的进步。
对比了下国产卡(异构加速卡AI)和N(L20 * 1卡)卡训练上的耗时,根据checkPoint的同一个global_step,N卡比异构加速卡AI耗时少了一半时间,下载安装包时也能明显的感觉到。
个人活动体验感受
整个活动走下来比较顺利,平台提供了多种开发工具可供选择,包括常用的VSCode,Jupyter,SSH命令行等;还提供了多种AI算力,其中异构加速卡AI很便宜实惠,如果算力要求更高的话,可以选择NVIDIA A800完全可以满足需求;另外还提供了500G的存储对于普通开发者来说完全够用了。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









