




文章首发于微信公众号《与有三学AI》
这是深度学习模型解读第7篇,本篇我们将介绍不规则形状的卷积。
作者&编辑 | 言有三
1 卷积中的不变性
图像任务,都需要识别出图像中的主体,用于分类,检测,分割,比如下面的验证码识别。
但是同样的目标,在不同的图片中,会存在位置的偏移,角度的旋转,尺度的大小。卷积神经网络要能够应对这些情况,比如分类任务,对于同样的目标在不同图像中的偏移,旋转,尺度,要输出同样的结果。

这便是我们常说的旋转,平移,尺度不变性了。
cnn有这个能力吗?有。
前面我们说过pooling,它有一定的平移不变性,而且网络越深,越强大。但是,它的这个能力仍然是有限的,受卷积核大小和感受野大小的约束。
尺度不变性和旋转不变性呢?很遗憾,几乎没有,不然Hinton也不会搞capsule。
我们通常做的随机裁剪,旋转,缩放等操作,就是利用了cnn强大的学习能力,制造出了各种版本的图片供其学习。为了模型的鲁棒性,需要生成大量的数据。
一句话,网络模型对于物体几何形变的适应能力几乎完全来自于数据本身所具有的多样性。
2 为什么呢?
前面我们说了问题,那为什么会这样呢?因为cnn就没有显式地学习这些信息,而卷积操作本身具有非常固定的几何结构,标准的卷积操作是一个非常规矩的采样,通常是正方形。
那,能不能不规矩呢?首先我们看什么是不规矩,下图来自于【1】。

a图大家很熟悉,标准的3*3卷积核,而b,c,d虽然也是9个采样点,但是每个采样点相对于中心点的偏移与a很不一样。b是一个通用的展示,即完全没有规律。c,d是b的特例。
我们将这样的卷积,称为(deformable convolutional networks)可变形卷积,笔者更喜欢称之为“不正经卷积”。
这种“不正经卷积”的特点,1是采样视野大于对应版本的标准卷积(带孔卷积不算),2是它的感受野是不规则的形状。
有什么好处呢?
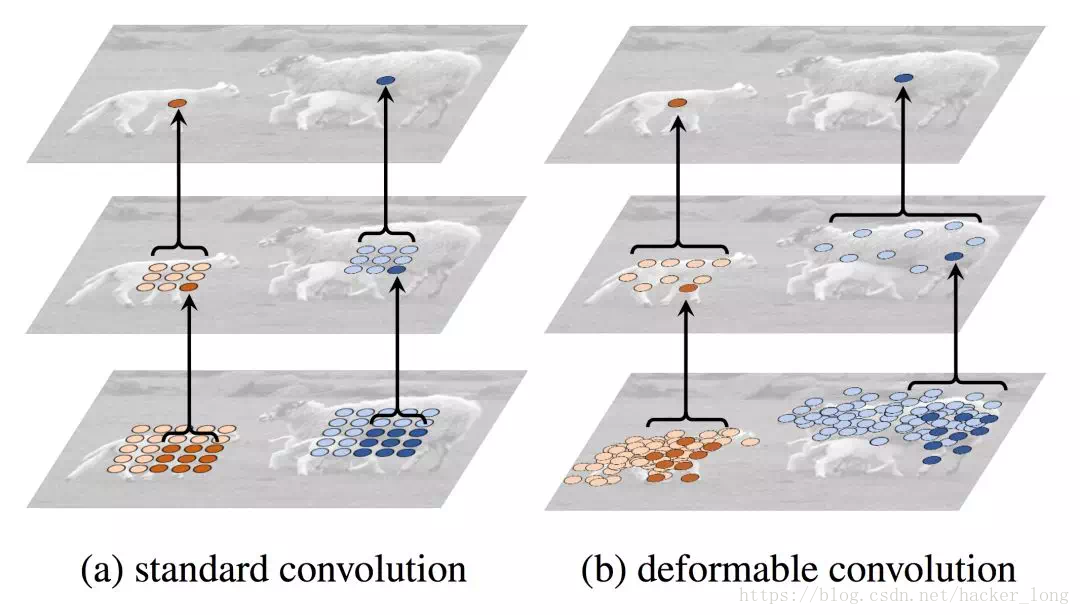
我们看上面的一张图,假如我们有一个分割任务,要分割出图中的尺度不同的动物。
我们先看左边的图,标准的卷积,感受野必然是一个方方正正的区域。顶图有一个中心像素,它的感受野是3*3,到了中间的图,周围四个角点又可以进一步扩展感受野,直到底部的图。
所以对于顶部目标的中心像素,经历了两次3*3卷积,它的感受野是固定的5*5,与动物本身的形状并不匹配。而同样的两个3*3的卷积,右边的“不正经卷积”,则由于灵活的感受野,所覆盖的区域更大,也更匹配了目标本身的形状。
这是一个非常通用的问题,标准卷积对目标的形状感受野不够灵活,卷积的效率自然也就下降。而可变形卷积则利用了不规则可变化的形状,改善了这两个问题。
3 怎么实现?
可变形卷积这么灵活,实现起来麻烦吗?答案是不麻烦,只需要增加一个偏移量即可,具体来说看下图。
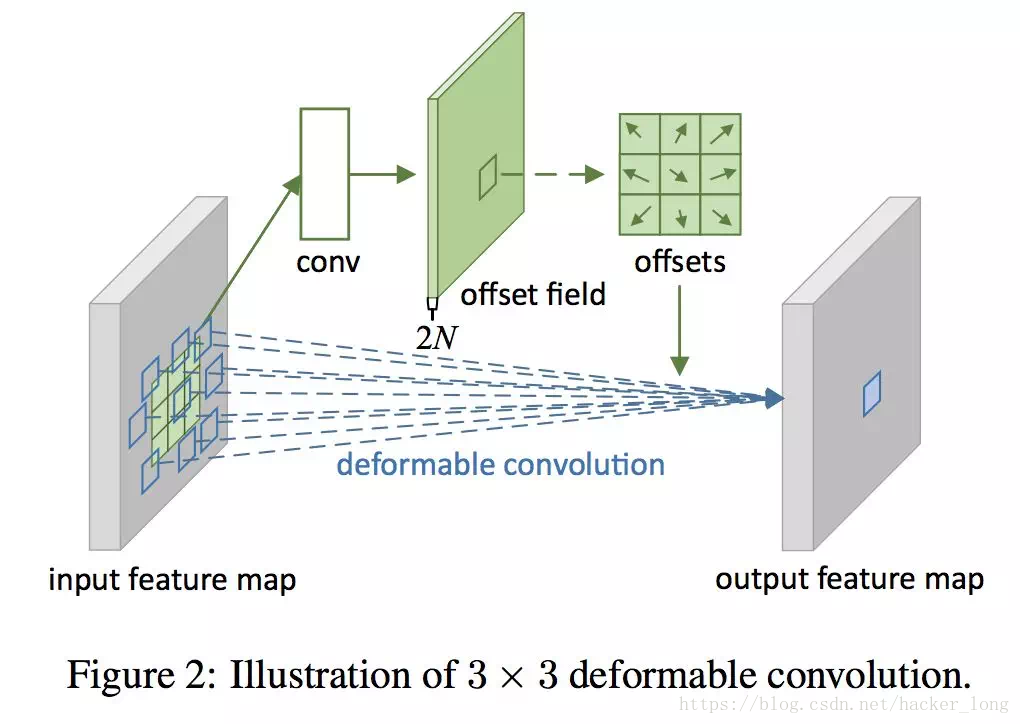
与标准卷积核相比,一个可变形卷积核,用于卷积的像素相对于中心像素各自的x,y方向上的偏移没有了规律,如果我们学习到了这个规律(实际就是用卷积核来记录它),就完成这件事情了。
实际实现就是多了一个offset层,通过offset输出通道数,我们可以控制要学习的变形的种类。当然,这个通道数一定是2N的,因为要同时记录x和y方向。
4 总结
做一个简单的总结,首先我们说说好处。(1)增加了网络的空间变形适应性,这也是网络要解决的本质问题。(2)不增加额外的标注信息和训练代价,仍然是原来的数据就可以训练,而且同时训练卷积系数和偏移量。(3)对于复杂的任务提升效果明显,具体的实验结果指标,可以至论文中看,也可以自己训着看。
坏处主要是增加了参数量与计算量,不过这个计算量其实不大,可以通过分组进行控制。
值得注意的是,可变形卷积并非是第一个研究这个问题的,在STN【2】中,已经通过Spatial TransformerLayer来实现了对旋转平移缩放等信息的学习。Active Convolution,Atrous convolution等都试图解决类似问题,在此就不一一讲解了,大家可以自己拓展学习。
参考文献
【1】Dai J, Qi H, Xiong Y, et al. Deformable convolutional networks[J]. CoRR, abs/1703.06211, 2017,1(2): 3.
【2】Jaderberg M, Simonyan K, Zisserman A. Spatial transformer networks[C]//Advances in neural information processing systems. 2015: 2017-2025.
同时,在我的知乎专栏也会开始同步更新这个模块,欢迎来交流
https://zhuanlan.zhihu.com/c_151876233
注:部分图片来自网络
—END—
转载请留言,侵权必究
本系列的完整目录:
【模型解读】从LeNet到VGG,看卷积+池化串联的网络结构
【模型解读】network in network中的1*1卷积,你懂了吗
【模型解读】GoogLeNet中的inception结构,你看懂了吗
感谢各位看官的耐心阅读,不足之处希望多多指教。后续内容将会不定期奉上,欢迎大家关注有三公众号 有三AI!




















 275
275

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











