



最近项目要频繁用到tensorflow,所以不得不认真研究下tensorflow而不是跟之前一样遇到了就搞一下了。
首先我觉得所有这些框架里面caffe是最清晰的,所以就算是学习tensorflow,我也会以caffe的思路去学习,这就是这个系列的用意。
今天是第1篇,咱们说io操作,也就是文件读取,载入内存。
01
Caffe的io操作
caffe的io,是通过在prototxt中定义数据输入,默认支持data,imagedata,hdf5data,window data等类型。Data layer,输入是LMDB数据格式,image data 支持的是image list的数据格式。
对于LMDB来说,我们在caffe layer中配置准备好的二进制数据即可。
对于image data,我们准备一个data list,官方的image data是一个分类任务的list,格式为每行image,label,当然随着任务的不同我们可以自定义。比如分割任务image,mask。检测任务,image num of object, object rect1,object rect2等。
典型的格式是这样:
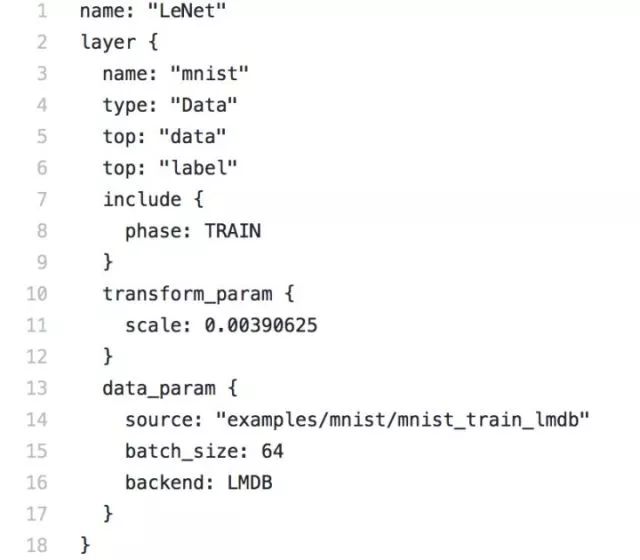
具体的载入,就是在相关层的DataLayerSetUp函数中设置好输入大小,load_batch函数中,读取原始数据,再利用data_transform塞入内存。
当然caffe也可以自定义python层使用,不过我还是更习惯c++,何况这里比较的也是官方自带的layer。
从上面我们可以看出,caffe的io都是从文件中载入,只是文件的组织方式不同。
Tensorflow的io输入则要复杂,全面很多,我们参考tensorflow1.5的API。
http://link.zhihu.com/?target=https%3A//
www.tensorflow.org/api_docs/python/tf/data
02
Tensorflow的io操作
Tensorflow不止是读取文件这一种方法,它可以包含以下几种方式。
预加载数据: 在TensorFlow图中定义常量或变量来保存所有数据(仅适用于数据量比较小的情况)
import tensorflow as tf
如上,x1,x2都是预加载好的数据。在设计Graph的时候,x1和x2就已经被定义成了两个有值的列表,在计算y的时候直接取x1和x2的值。这种方法的问题是将数据直接内嵌到Graph中,再把Graph传入Session中运行。当数据量比较大时,Graph的传输会遇到效率问题。
Feeding 它定义变量的时候用占位符替代数据,待运行的时候填充数据。
import tensorflow as tf
定义的时候,x1, x2只是占位符所以没有具体的值,运行的时候使用sess.run()中的feed_dict参数,将Python产生的数据喂给后端,并计算y。
Reading From File
前两种方法很方便,但是遇到大型数据的时候就会很吃力,即使是Feeding,中间环节的增加也是不小的开销,比如数据类型转换等等。而且,面对复杂类型的数据,也是处理不过来的。因此与caffe一样,tensorflow也是支持从文件中读取数据。
下面举一个利用队列读取硬盘中的数据到内存的例子:假如需要读取的数据存在一个list中。这篇博客举了一个很好的例子;
http://honggang.io/2016/08/19/tensorflow-data-reading/
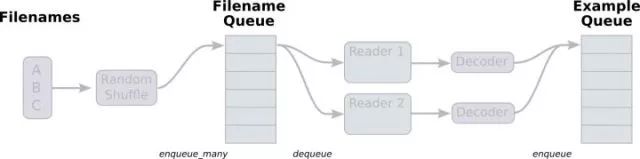
在上图中,首先由一个单线程把文件名堆入队列,两个Reader同时从队列中取文件名并读取数据,Decoder将读出的数据解码后堆入样本队列。
利用了string_input_producer + tf.TextLineReader() + train.start_queue_runners来读取数据,string_input_producer的定义在
https://github.com/tensorflow/tensorflow/blob/r1.5/tensorflow/python/training/input.py
string_input_producer(
从上面可见,可以指定num_epochs,是否shuffle等,这就是一个最简单的从文件中读取的例子了。
假设有文件A.csv如下:
Alpha1,A1
Alpha2,A2
Alpha3,A3
单个reader读取单个数据脚本如下;
import tensorflow as tf
讲了上面的基础例子之后,我们开始看更复杂的例子。
上面的例子包含两类,一种是从placeholder读内存中的数据,一种是使用queue读硬盘中的数据,而1.3以后的Dataset API同时支持从内存和硬盘的读取。
它们支持多种类型的输入,分别是FixedLengthRecordDataset, TextLineDataset, TFRecordDataset类型的。
TextLineDataset:这个函数的输入是一个文件的列表,输出是一个dataset。dataset中的每一个元素就对应了文件中的一行。可以使用这个函数来读入CSV文件,跟上面例子类似。
TFRecordDataset:这个函数是用来读TFRecord文件的,dataset中的每一个元素就是一个TFExample,这是很常用的。
FixedLengthRecordDataset:这个函数的输入是一个文件的列表和一个record_bytes,之后dataset的每一个元素就是文件中固定字节数record_bytes的内容。通常用来读取以二进制形式保存的文件,如CIFAR10数据集就是这种形式。
迭代器:提供了一种一次获取一个数据集元素的方法。
所有定义都在tensorflow/python/data/ops/readers.py中。
参考文章
https://zhuanlan.zhihu.com/p/30751039
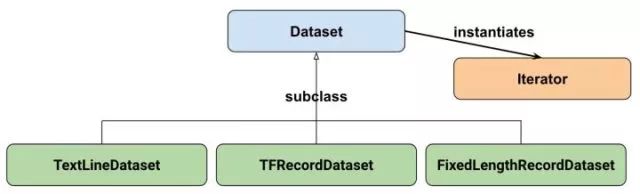
我们先理解一下dataset是什么?
Dataset可以看作是相同类型“元素”的有序列表,而单个“元素”可以是向量,也可以是字符串、图片,甚至是tuple或者dict。
先以最简单的,Dataset的每一个元素是一个数字为例:
import tensorflow as tf
这样,我们就创建了一个dataset,这个dataset中含有5个元素,分别是1.0, 2.0, 3.0, 4.0, 5.0。
如何将这个dataset中的元素取出呢?方法是从Dataset中示例化一个Iterator,然后对Iterator进行迭代。
iterator = dataset.make_one_shot_iterator()
对应的输出结果应该就是从1.0到5.0。语句iterator = dataset.make_one_shot_iterator()从dataset中实例化了一个Iterator,这个Iterator是一个“one shot iterator”,即只能从头到尾读取一次。one_element = iterator.get_next()表示从iterator里取出一个元素,调用sess.run(one_element)后,才能真正地取出一个值。
如果一个dataset中元素被读取完了,再尝试sess.run(one_element)的话,就会抛出tf.errors.OutOfRangeError异常,这个行为与使用队列方式读取数据的行为是一致的。在实际程序中,可以在外界捕捉这个异常以判断数据是否读取完,请参考下面的代码:
dataset = tf.data.Dataset.from_tensor_slices(np.array([1.0, 2.0, 3.0, 4.0, 5.0]))
dataset还可以有一些基本的数据变换操作,即transform操作,常见的有map,batch,shuffle,repeat
把数据+1dataset = dataset.map(lambda x: x + 1)
组合成batch,dataset = dataset.batch(32)
进行shuffle,dataset = dataset.shuffle(buffer_size=10000)
repeat 组成多个epoch,dataset = dataset.repeat(5)
03
来一个实例
理解了dataset之后,我们再看如何从文件中读取数据。由于tfrecord是非常常用的格式,下面我们就以这个为例。
假如我们有两个文件夹,一个是整理好的固定大小的图片,一个是对应label图片,这是一个分割任务,下面我们开始做。
处理成tfrecord格式
首先,我们要把数据处理成tfrecord格式。
我们先定义一下存储格式:
直接贴完整代码了
import tensorflow as tf
_convert_to_example这个函数,就是定义存储的格式;tf.gfile.FastGFile就是读取图片原始文件格式且不编解码,writer = tf.python_io.TFRecordWriter(sys.argv[3])是定义writer,写起来其实挺简单。
tf.train.Example是一个protocol buffer,定义在
https://github.com/tensorflow/tensorflow/blob/r1.5/tensorflow/core/example/example.proto
将数据填入到Example后就可以序列化为一个字符串。一个Example中包含Features,Features里包含Feature,每一个feature其实就是一个字典,如上面的一个字典包含4个字段。
读取tf.records
读取数据就可以使用tf.TFRecordReader的tf.parse_single_example解析器。它将Example protocol buffer解析为张量。
简单的利用队列读取,可以采用下面的方法
filename_queue = tf.train.string_input_producer([filename])
不过,我们这里利用新的API的dataset来读取,更加高效。直接贴上代码如下:
上面定义过_convert_to_example,我们这里先定义一个读取格式。
def _extract_features(example):
下面这个函数就是create迭代器了,在这里我们使用最简单的iterator,one-shot iterator来迭代,当然它只支持在一个dataset上迭代一次,不需要显式初始化。这里不需要怀疑epoch的问题,因为dataset.repeat(num_epoch)就会设置epoch数目,所以虽然只在dataset上迭代一次,但是已经遍历过数据epoch次。
def create_one_shot_iterator(filenames, batch_size, num_epoch):
就这样完毕!
打一个小广告,我的摄影中的图像基础技术公开课程《AI 程序员码说摄影图像基础》上线了,主要从一个图像处理工程师的角度来说说摄影中的基础技术和概念,欢迎大家订阅交流。

加入我们做点趣事







微信
Longlongtogo

公众号内容
1 图像基础|2 深度学习|3 行业信息


往期精彩
[caffe解读] caffe从数学公式到代码实现5-caffe中的卷积



















 8399
8399

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











