







 本文深入探讨Scala编程语言,从函数式编程的特点和优势出发,讲解闭包、柯里化、case class与普通类的区别,单例对象的实现与作用,以及伴生类和伴生对象的概念。此外,还涉及了Scala中的类型系统,如Unit、Nil、None等的区别,以及trait与抽象类的对比,函数和高阶函数的应用。文章还涵盖了尾递归、call-by-name和call-by-value策略,以及Scala中的字符串、类型系统中的协变和逆变。通过对这些核心概念的剖析,读者将对Scala有更全面的理解。
本文深入探讨Scala编程语言,从函数式编程的特点和优势出发,讲解闭包、柯里化、case class与普通类的区别,单例对象的实现与作用,以及伴生类和伴生对象的概念。此外,还涉及了Scala中的类型系统,如Unit、Nil、None等的区别,以及trait与抽象类的对比,函数和高阶函数的应用。文章还涵盖了尾递归、call-by-name和call-by-value策略,以及Scala中的字符串、类型系统中的协变和逆变。通过对这些核心概念的剖析,读者将对Scala有更全面的理解。
一、scala语言有什么特点?什么是函数式编程?有什么优点?
1、特点:scala语言集成面向对象和函数式编程
2、函数是编程解释:函数式编程是一种典范,将电脑的运算视作是函数的运算。
3、优点:与过程化编程相比,函数式编程里的函数计算可以随时调用。
4、函数式编程中,函数是一等公民。
二、scala中的闭包
闭包是一个函数,返回值依赖于声明在函数外部的一个或多个变量。
闭包的实质就是代码与用到的非局部变量的混合,即:闭包 = 代码 + 用到的非局部变量
例如:
def mulBy(factor:Double) = (x:Double) => factor * x
//开始调用
val tripe = mulBy(3)
val half = mulBy(0.5)
println(tripe(14) + " " + half(14))
这就是一个闭包
三、scala中的柯里化
柯里化技术是一个接受多个参数的函数转化为接受其中几个参数的函数。经常被用来处理高阶函数。
定义:
柯里化指的是将原来接受两个参数的函数变成新的接受一个参数的函数的过程。新的函数返回一个以原有的第二个参数作为参数的函数
例如:
def mul(x:Int,y:Int) = x * y //该函数接受两个参数
def mulOneAtTime(x:Int) = (y:Int) => x * y //该函数接受一个参数生成另外一个接受单个参数的函数
这样的话,如果需要计算两个数的乘积的话只需要调用:
mulOneAtTime(5)(4)
这就是函数的柯里化
优点:
scala柯里化风格的使用可以简化主函数的复杂度,提高主函数的自闭性,提高功能上的可扩张性、灵活性。可以编写出更加抽象,功能化和高效的函数式代码。
四、case class和class的区别
样例类(case class)的模式匹配
object CaseOps {
def main(args: Array[String]): Unit = {
caseOps7
}
/**
* 样例类(case class)的模式匹配
*/
def caseOps7: Unit = {
abstract class Expr
case class Var(name:String) extends Expr
case class UnOp(operator:String, arg:Expr) extends Expr
case class BinOp(operator:String, left:Expr, right:Expr) extends Expr
def test(expr:Expr) = expr match {
case Var(name) => println(s"Var($name)...")
case UnOp(operator, e) => println(s"$e ... $operator")
case BinOp(operator, left, right) => println(s"$left $operator $right")
case _ => println("default")
}
test(BinOp("+", Var("1"), Var("2")))
test(UnOp("-",Var("3")))
}
}
结果:
Var(1) + Var(2)
Var(3) ... -case class:
是一个样本类,样本类是一种不可变切可分解类的语法糖,也就是说在构建的时候会自动生成一些语法糖,具有以下几个特点:
1、自动添加与类名一致的构造函数(也就是半生对象,通过apply方法实现),也就是说在构造对象的时候不需要使用new关键字,如下:
scala> case class People(name:String,age:Int)
defined class People
scala> val p = People("mobin",22) //省略了new关键字
p: People = People(mobin,22)2、实现了unapply方法,可以通过模式匹配来获取类属性,是Scala中抽取器的实现和模式匹配的关键方法。
scala> p match { case People(x,y) => println(x,y) }
(mobin,22)3、实现了类构造函数的getter方法即样本类中的参数默认是val关键字,不可以修改,但是可以设置关键字为var,这时就就帮你实现了setter和getter方法:
关键字为默认val的情形:
scala> p.name
res0: String = mobin
scala> p.name = "mobin1" //报错,因为构造参数被声明为val所以并没有帮你实现setter方法
<console>:10: error: reassignment to val
p.name = "mobin1"关键字设置为var的情形:
scala> case class People(var name:String) //参数被声明为var
defined class People
scala> val p = People("mobin")
p: People = People(mobin)
scala> p.name = "mobin2"
p.name: String = mobin2
scala> p.name
res1: String = mobin2 //修改成功,并没有报错3、默认实现了toString,equals,hashcode,copy方法
4、样本类可以通过==来比较两个对象,不在构造方法内地二属性不会用在比较上
class:
class是一个类
1、class在构造对象的时候需要使用new关键字才可以。
区别:
普通类在编译后只会生成一个类名.class文件;而样例类会生成伴生类.class文件和伴生对象的.class文件。
默认是可以序列化的,也就是实现了Serializable
五、单例对象
单例对象是一种特殊的类,如何特殊?
1、它只有一个实例。
2、和lazy 变量一样,单例对象是延迟创建的,当它被第一次使用时创建。
单例对象如何被创建出来:
当对象定义于顶层时(即没有包含在其它类中),单例对象只有一个实例。
其它:
当单例对象被定义于类或方法中时,单例对象表现的和惰性变量一样。
如何去定义一个单例对象:
一个单例对象就是一个值,单例对象的定义方式很像类,只不过用关键字object:
object Box
给单例对添加一个方法:
package logging
object Logger {
def info(message: String): Unit = println(s"INFO: $message")
}如何通过import使用单例对象里的方法:
import logging.Logger.info
class Project(name: String, daysToComplete: Int)
class Test {
val project1 = new Project("TPS Reports", 1)
val project2 = new Project("Website redesign", 5)
info("Created projects") // Prints "INFO: Created projects"
}import语句要求被导入的标识具有一个“稳定路径”,一个单例对象由于全局唯一,所以具有稳定路径。
重点:
如果一个 object 没定义在顶层而是定义在另一个类或者单例对象中,那么这个单例对象和其他类普通成员一样是“路径相关的”。这意味着有两种行为,class Milk 和 class OrangeJuice,一个类成员 object NutritionInfo “依赖”于包装它的实例,要么是牛奶要么是橙汁。 milk.NutritionInfo 则完全不同于oj.NutritionInfo。
六、伴生类和伴生对象(及孤立对象)
参考:https://www.cnblogs.com/chorm590/p/scala_201904221054.html
简述:
在scala中,单例对象与类同名时,该对象被称为该类的伴生对象,该类被称为该对象的伴生类。
详细解释:
教材中关于伴生对象的解释是:实现类似 Java 中那种既有实例成员又有静态成员的类的功能。
为什么上面说它是一种 “功能” 呢?因为要想实现像 Java 中那样的类,光靠一个 Scala 类可不行。在 Scala 中,我们必须:
1. 定义一个 class 并在这里面实现所有的实例成员。
2. 添加一个 object ,这个 object 要与上面的 class 同名,然后在这里面实现所有的静态成员。
3. 定义的 class 与 object 必须在同一个文件内。
注意:
伴生对象和伴生类可以互相访问其私有成员
举例:
class CompanionDemo {
private var clzi = 0
def init(): Unit = {
println("variable in clz:" + clzi)
println("variable from object:" + CompanionDemo.obji)
CompanionDemo.access(this)
}
}
object CompanionDemo {
private var obji = 1
def access(clz: CompanionDemo): Unit = {
println("variable in object:" + obji)
println("variable from clz:" + clz.clzi)
}
}
并通过如下代码来访问伴生对象
object cpDemp {
def main(args: Array[String]){
val cd = new CompanionDemo()
cd.init()
}
}执行结果:
variable in clz:0
variable from object:1
variable in object:1
variable from clz:0
不与伴生类同名的对象称之为孤立对象
解释什么是孤立对象:
在《Scala编程》这本书中, 把孤立对象和伴生对象都叫做单例对象。孤立对象指的是只有一个使用object关键字定义的对象, 伴生对象是指有一个使用object关键字定义的对象, 除此之外还有一个使用class关键字定义的同名类, 这个同名的类叫做伴生类。在Scala中单例对象这个概念多少都会让人迷惑, 按《Scala编程》这本书中的说法, 使用object关键字修饰的对象就叫做单例对象。其实这里的单例和设计模式中的单例模式的概念并不尽相同。在Scala中没有静态的概念, 所有的东西都是面向对象的。其实object单例对象只是对静态的一种封装而已, 在class文件层面中,object单例对象就是用静态(static)来实现的。
伴生对象的意义:
Scala 中没有 static 关键字,而 Scala 又运行与 JVM 之上,与 Java 类库完全兼容的编程语言,同时类中拥有静态属性又是如此的有必要,因此推出这个伴生对象机制就显得很有必要了。所以第 1 个意义就是为了弥补类中不能定义 static 属性的缺陷。
那我们知道,在 Java 中静态属性是属于类的,在整个 JVM 中只开辟一块内存空间,这种设定使得静态属性可以很节省内存资源,不用担心像实例属性那样有内存溢出的风险。在 Scala 中伴生对象本质上也是生成静态属性,所以这第 2 个意义就是节省内存资源。
既然静态属性在整个 JVM 中仅开辟一块内存空间,那就说明我们可以在所有实例当中共享这块内存里面的信息,所以第 3 个意义就是资源共享。
object的作用:
1.存放工具方法和常量 2.高效共享单个不可变的实例 3.单例模式
七、scala和java的区别
1、变量声明;2、返回值;3、结束符;4、scala循环中可用if守卫;5、通配符;6、构造器;7、内部类;8、接口;9、赋值。
scala构造器的解释:
https://www.cnblogs.com/zsql/p/10952565.html
https://blog.youkuaiyun.com/u013007900/article/details/79168228
http://www.mamicode.com/info-detail-197046.html
scala内部类的解释(伴生对象、类型投影 可以扩大内部类的作用域):
https://docs.scala-lang.org/zh-cn/tour/inner-classes.html
https://www.jianshu.com/p/0a177e871611
https://www.cnblogs.com/linxizhifeng/p/9100669.html
java、scala接口的不同:
scala:scala中接口称为特质(trait),特质中是可以写抽象方法,也可以写具体的方法体以及状态。且类是可以实现多个特质的。
特质中未被实现的方法默认就是抽象的
子类的实现或继承统一使用的事extends关键字,如果需要实现或继承多个使用with关键字
特质中可以有构造器
特质可以继承普通的类,并且这个类称为所有继承trait的父类
java: java中的接口(interface),接口中的方法只能是抽象方法,不可以写具体包含方法体的方法
接口中不能有抽象的属性,且属性的修饰符都是public static final
类实现接口需要使用implements关键字,实现多个接口,需要用逗号隔开
接口中不可以有构造器
接口不可以继承普通的类
八、尾递归
参考链接:
https://www.jianshu.com/p/e456c27a4366
https://www.jianshu.com/p/d177c30f59de
概述:
递归算法需要保持调用堆栈,效率较低,如果调用次数较多,会耗尽内存或栈溢出。然而,尾递归可以克服这一缺点。
尾递归是指递归调用是函数的最后一个语句,而且其结果被直接返回,这是一类特殊的递归调用。由于递归结果总是直接返回,尾递归比较方便转换为循环,因此编译器容易对它进行优化。
具体实现方法:
递归求阶乘的经典例子:
#普通递归
def factorial(n: BigInt): BigInt = {
if (n <= 1)
1
else
n * factorial(n-1)
}上面的代码,由于每次递归调用n-1的阶乘时,都有一次额外的乘法计算,这使得堆栈中的数据都需要保留。在新的递归中要分配新的函数栈。
运行过程就像这样:
factorial(4)
--------------
4 * factorial(3)
4 * (3 * factorial(2))
4 * (3 * (2 * factorial(1)))
4 * (3 * (2 * 1))尾递归版本,在效率上,和循环是等价的:
import scala.annotation.tailrec
def factorialTailRecursive(n: BigInt): BigInt = {
@tailrec
def _loop(acc: BigInt, n: BigInt): BigInt =
if(n <= 1) acc else _loop(acc*n, n-1)
_loop(1, n)
}运行过程如下:
factorialTailRecursive(4)
--------------------------
_loop(1, 4)
_loop(4, 3)
_loop(12, 2)
_loop(24, 1)该函数中的_loop在最后一步,要么返回递归边界条件的值,要么调用递归函数本身。
改写成尾递归版本的关键:
尾递归版本最重要的就是找到合适的累加器,该累加器可以保留最后一次递归调用留在堆栈中的数据,积累之前调用的结果,这样堆栈数据就可以被丢弃,当前的函数栈可以被重复利用。
在这个例子中,变量acc就是累加器,每次递归调用都会更新该变量,直到递归边界条件满足时返回该值。
斐波那契的普通递归和尾递归(累加器可以不止一个):
#普通递归
def fibonacci(n: Int): Int =
if (n <= 2)
1
else
fibonacci(n-1) + fibonacci(n-2)
#尾递归
#尾递归版本用了两个累加器,一个保存较小的项acc1,另一个保存较大项acc2:
def fibonacciTailRecursive(n: Int): Int = {
@tailrec
def _loop(n: Int, acc1: Int, acc2: Int): Int =
if(n <= 2)
acc2
else
_loop(n-1, acc2, acc1+acc2)
_loop(n, 1, 1)
}scala对于尾递归的支持:
Scala语言特别增加了一个注释@tailrec,该注释可以确保程序员写出的程序是正确的尾递归程序,如果由于疏忽大意,写出的不是一个尾递归程序,则编译器会报告一个编译错误,提醒程序员修改自己的代码。
九、函数中unit是什么意思:
Scala中的Unit类型类似于java中的void,无返回值。主要的不同是在Scala中可以有一个Unit类型值,也就是(),然而java中是没有void类型的值的。除了这一点,Unit和void是等效的。一般来说每一个返回void的java方法对应一个返回Unit的Scala方法。
十、trait(特质)和abstract class(抽象类)的区别
https://blog.youkuaiyun.com/优快云_bird/article/details/100687097
- 首先先将trait作为接口使用,此时的trait就与Java中的接口 (interface)非常类似;
- 在trait中可以定义抽象方法,就像抽象类中的抽象方法一样,只要不给出方法的方法体即可;
- 类可以使用extends关键字继承trait,注意,这里不是 implement,而是extends ,在Scala中没有 implement 的概念,无论继承类还是trait,统一都是 extends;
- 类继承后,必须实现其中的抽象方法,实现时,不需要使用 override 关键字;
- Scala不支持对类进行多继承,但是支持多重继承 trait,使用 with 关键字即可。
- trait中未被实现的方法默认是抽象方法,因此不需要在方法前加abstract。
- 类继承多个trait后,可依次调用多个trait中的同一个方法,只要让多个trait中的同一个方法,在最后都依次执行 super 关键字即可,类中调用多个trait中都有的这个方法时,首先会从最右边的trait的方法开始执行,然后依次往左执行,形成一个调用链条;
- Scala支持部分实现,也就是说你可以在其中实现部分方法Scala抽象类不能被实例化,包含若干定义不完全的方法,具体的实现由子类去实现。
十一、apply方法和unapply方法的区别:
https://www.jianshu.com/p/748b09609858
-
apply方法
通常,在一个类的半生对象中定义apply方法,在生成这个类的对象时,就省去了new关键字。
-
unapply方法
可以认为unapply方法是apply方法的反向操作,apply方法接受构造参数变成对象,而unapply方法接受一个对象,从中提取值。
示例:
class Currency(val value: Double, val unit: String) {
}
object Currency{
def apply(value: Double, unit: String): Currency = new Currency(value, unit)
def unapply(currency: Currency): Option[(Double, String)] = {
if (currency == null){
None
}
else{
Some(currency.value, currency.unit)
}
}
}在构建对象的时候就可以直接使用val currency = Currency(30.2, "EUR")这种方式,不用使用new。
而unapply方法一般用于模式匹配
def main(args: Array[String]): Unit = {
val currency = Currency(30.2, "EUR")
currency match {
case Currency(amount, "USD") => println("$" + amount)
case _ => println("No match.")
}
}这段代码的输出为No match.如果将第二行改为val currency = Currency(30.2, "USD")那么输出为$30.2
十二、Scala类型系统中Nil, Null, None, Nothing,Unit,null六个类型的区别?
https://www.cnblogs.com/PerkinsZhu/p/7868012.html
- Null是一个trait(特质),是所有引用类型AnyRef的一个子类型,null是Null唯一的实例。
- Nothing也是一个trait(特质),是所有类型Any(包括值类型和引用类型)的子类型,它不在有子类型,它也没有实例,实际上为了一个方法抛出异常,通常会设置一个默认返回类型。
- Nil代表一个List空类型,等同List[Nothing]
- None是Option monad的空标识,None和Some(x)都是Option[A]的子类,Some是Class,None是Object,None是一个Option[Nothing]类型的对象,调用get()方法将会抛出NoSuchElementException("None.get")异常,其存在的目的是为了表面java中的NullPointerException()的发生。
- Unit是所有AnyVal 的子类(注意区别Nothing),只有一个唯一的Value,即括号()(注意这里是Value依旧是实例/对象)。如果方法的返回值类型为Unit,则类似于java中void。
- null 就很容易理解了和java中的null是同一个null。一般在scala中不直接使用null!
十三、惰性求值call-by-name和call-by-value求值策略的区别(val与def)?
https://blog.youkuaiyun.com/bluejoe2000/article/details/43966723
- (1)call-by-value是在调用函数之前计算;
- (2) call-by-name是在需要时计算
示例代码:
示例代码
//声明第一个函数
def func(): Int = {
println("computing stuff....")
42 // return something
}
//声明第二个函数,scala默认的求值就是call-by-value
def callByValue(x: Int) = {
println("1st x: " + x)
println("2nd x: " + x)
}
//声明第三个函数,用=>表示call-by-name求值
def callByName(x: => Int) = {
println("1st x: " + x)
println("2nd x: " + x)
}
//开始调用
//call-by-value求值
callByValue(func())
//输出结果
//computing stuff....
//1st x: 42
//2nd x: 42
//call-by-name求值
callByName(func())
//输出结果
//computing stuff....
//1st x: 42
//computing stuff....
//2nd x: 42十四、scala中的yield:
https://www.cnblogs.com/sunfie/p/4983841.html
yield 关键字的简短总结:
- 针对每一次 for 循环的迭代, yield 会产生一个值,被循环记录下来 (内部实现上,像是一个缓冲区).
- 当循环结束后, 会返回所有 yield 的值组成的集合.
- 返回集合的类型与被遍历的集合类型是一致的.
普通的不带yield的for循环:
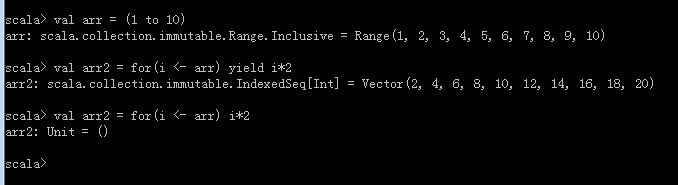
for循环中带有多个if守卫:
val filesHere = Map("java" -> 22, "scala" -> 6, "spark" -> 5)
val scalaFiles =for {
file <- filesHere
if file._1.startsWith("java")
if file._2 == 22
} yield file
println(scalaFiles)十五、comprehension推导式:
comprehension(推导式)是若干个操作组成的替代语法。如果不用yield关键字,comprehension(推导式)可以被forech操作替代,或者被map/flatMap,filter代替。
示例代码:
// 三层循环嵌套
for {
x <- c1
y <- c2
z <- c3 if z > 0
} yield {...}
//上面的可转换为
c1.flatMap(x => c2.flatMap(y => c3.withFilter(z => z > 0).map(z => {...})))十六、函数和高阶函数
https://blog.youkuaiyun.com/优快云_bird/article/details/100687097
什么是函数:
Scala混合了面向对象和函数式的特性,我们通常将可以作为参数传递到方法中的表达式叫做函数。
高阶函数包括哪些?
作为值的函数、匿名函数、闭包、柯里化等等。
https://blog.youkuaiyun.com/sinat_25306771/article/details/51474625
简单来说:
高阶函数指能接受或者返回其他函数的函数,scala中的filter map flatMap函数都能接受其他函数作为参数。
函数作为参数的例子:
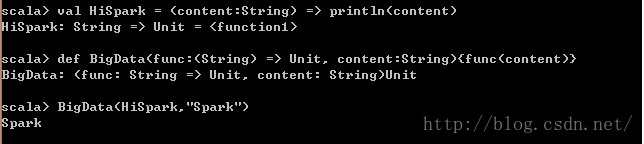
首先我们定义了一个函数BigData,这个函数有两个参数,第一个参数是一个函数,函数名是func,他有一个String类型的参数并且返回值是unit空的;第二个参数是String类型的变量名为content的变量,函数体是将第二个参数作为第一个参数也就是函数func的参数,来调用第一个函数,整个函数返回值为unit空。这里只要传入的函数的格式与定义的一致就行。
函数作为返回值的例子:

首先我们定义了一个返回值为函数的函数func_Returned,然后我们将其返回值也就是一个函数赋值了变量returned,这样就得到了一个名为returned的函数,然后我们调用returned函数得到了打印结果。我们输入func_Returned(“Spark”),生成了一个名为Spark的函数。
说明:
高阶函数有个非常有用的特性是类型推断。其可以自动推断出参数的类型,而且对于只有一个的参数的函数,可以省略掉小括号,并且在函数的参数作用的函数体内只是用一次函数的输入参数的值话,就可省略掉函数名,用下划线(_)代替。
十七、scala中的string
在 Scala 中,字符串的类型实际上是 Java String,它本身没有 String 类。
在 Scala 中,String 是一个不可变的对象,所以该对象不可被修改。这就意味着你如果修改字符串就会产生一个新的字符串对象。但其他对象,如数组就是可变的对象。
十八、scala中的协变、逆变
https://blog.youkuaiyun.com/weixin_34315485/article/details/90586707
主要解决的问题:
Scala中协变和逆变主要作用是用来解决参数化类型的泛化问题。由于参数化类型的参数(参数类型)是可变的,当两个参数化类型的参数是继承关系(可泛化),那被参数化的类型是否也可以泛化呢?在Java中这种情况下是不可泛化的,然而Scala提供了三个选择,即协变、逆变和非变,解决了参数化类型的泛化问题。
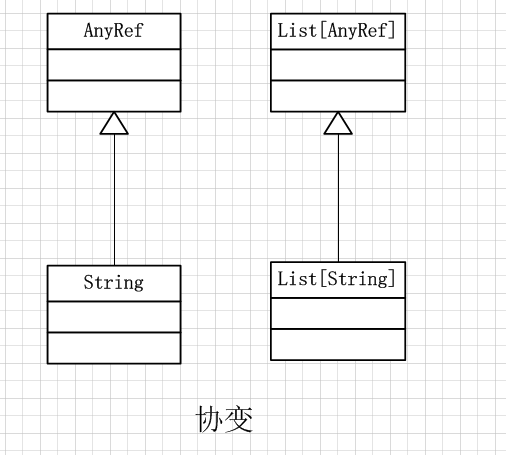
1、协变(covariance):
协变定义形式如:trait List[+T] {} 。当类型S是类型A的子类型时,则List[S]也可以认为是List[A}的子类型,即List[S]可以泛化为List[A]。也就是被参数化类型的泛化方向与参数类型的方向是一致的,所以称为协变(covariance)。
问题:为什么java语言中不存在协变及逆变?
举例:
java.util.List<String> s1=new LinkedList<String>();
java.util.List<Object> s2=new LinkedList<Object>();
//下面这条语句会报错
//Type mismatch: cannot convert from
// List<String> to List<Object>
s2=s1;
分析:
虽然在类层次结构上看,String是Object类的子类,但List<String>并不是的List<Object>子类,也就是说它不是协变的。java的灵活性就这么差吗?其实java不提供协变和逆变这种特性是有其道理的,这是因为协变和逆变会破坏类型安全。假设java中上面的代码是合法的,我们此时完全可以s2.add(new Person(“摇摆少年梦”)往集合中添加Person对象,但此时我们知道, s2已经指向了s1,而s1里面的元素类型是String类型,这时其类型安全就被破坏了,从这个角度来看,java不提供协变和逆变是有其合理性的。
scala中的非变[T]同java的情形一样:
//定义自己的List类
class List[T](val head: T, val tail: List[T])
object NonVariance {
def main(args: Array[String]): Unit = {
//编译报错
//type mismatch; found :
//cn.scala.xtwy.covariance.List[String] required:
//cn.scala.xtwy.covariance.List[Any]
//Note: String <: Any, but class List
//is invariant in type T.
//You may wish to define T as +T instead. (SLS 4.5)
val list:List[Any]= new List[String]("摇摆少年梦",null)
}
}
可以看到,当不指定类为协变的时候,而是一个普通的scala类,此时它跟java一样是具有类型安全的,称这种类是非变的(Nonvariance)。
如何使用协变[+T]
scala的灵活性在于它提供了协变与逆变语言特点供你选择。上述的代码要使其合法,可以定义List类是协变的,泛型参数前面用+符号表示,此时List就是协变的,即如果T是S的子类型,那List[T]也是List[S]的子类型。代码如下:
//用+标识泛型T,表示List类具有协变性
class List[+T](val head: T, val tail: List[T])
object NonVariance {
def main(args: Array[String]): Unit = {
val list:List[Any]= new List[String]("摇摆少年梦",null)
}
}
注意:如果自定义的类满足协变要求,其成员方法也应定义为泛型且其参数输入类型必须是T的超类:
如果不将成员方法的输入参数设置为T的超类会遇到问题:
class List[+T](val head: T, val tail: List[T]) {
//下面的方法编译会出错
//covariant type T occurs in contravariant position in type T of value newHead
//编译器提示协变类型T出现在逆变的位置
//即泛型T定义为协变之后,泛型便不能直接
//应用于成员方法当中
def prepend(newHead:T):List[T]=new List(newHead,this)
}
object Covariance {
def main(args: Array[String]): Unit = {
val list:List[Any]= new List[String]("摇摆少年梦",null)
}
} 将成员方法也定义为泛型,代码如下:
class List[+T](val head: T, val tail: List[T]) {
//将函数也用泛型表示
//因为是协变的,输入的类型必须是T的超类
def prepend[U>:T](newHead:U):List[U]=new List(newHead,this)
override def toString()=""+head
}
object Covariance {
def main(args: Array[String]): Unit = {
val list:List[Any]= new List[String]("摇摆少年梦",null)
println(list)
}
} 2、逆变(contravariance)
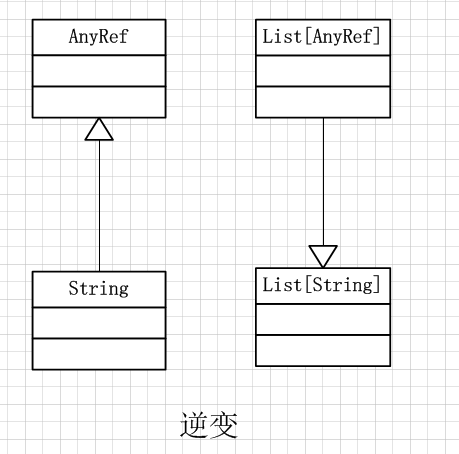
逆变定义形式如:trait List[-T] {}
当类型S是类型A的子类型,则Queue[A]反过来可以认为是Queue[S}的子类型。也就是被参数化类型的泛化方向与参数类型的方向是相反的,所以称为逆变(contravariance)。
3、协变和逆变在定义成员函数时的区别:
声明逆变:
//声明逆变
class Person2[-A]{ def test(x:A){} }错误的声明协变:
//声明协变,但会报错
//covariant type A occurs in contravariant position in type A of value x
class Person3[+A]{ def test(x:A){} }正确的声明协变:
class Person3[+A]{ def test[R>:A](x:R){} }逆变点:
https://segmentfault.com/a/1190000003509191
https://hongjiang.info/scala-pitfalls-10/
方法的参数的位置被称为逆变点。
协变点:
方法的返回值的位置被称为协变点。
里氏替换原则:
https://www.cnblogs.com/yanggb/p/10928309.html
https://www.jianshu.com/p/fae653a739e0
4、类型通配符:
类型通配符是指在使用时不具体指定它属于某个类,而是只知道其大致的类型范围,通过”_ <:” 达到类型通配的目的,如下面的代码
例子:
class Person(val name:String){
override def toString()=name
}
class Student(name:String) extends Person(name)
class Teacher(name:String) extends Person(name)
class Pair[T](val first:T,val second:T){
override def toString()="first:"+first+" second: "+second;
}
object TypeWildcard extends App {
//Pair的类型参数限定为[_<:Person],即输入的类为Person及其子类
//类型通配符和一般的泛型定义不一样,泛型在类定义时使用,而类型能配符号在使用类时使用
def makeFriends(p:Pair[_<:Person])={
println(p.first +" is making friend with "+ p.second)
}
makeFriends(new Pair(new Student("john"),new Teacher("摇摆少年梦")))
}
5、上界和下界
https://blog.youkuaiyun.com/luofazha2012/article/details/80342579
类型的上界和下界,它们的含义如下。
1) U >: T
这是类型下界的定义,也就是U必须是类型T的父类(或本身,自己也可以认为是自己的父类)。
2) S <: T
这是类型上界的定义,也就是S必须是类型T的子类(或本身,自己也可以认为是自己的子类)
十九、元组相关
1、元组的遍历
方式1:
for (elem <- tuple1.productIterator ) {
print(elem)
}
方式2:
tuple1.productIterator.foreach(i => println(i))
tuple1.produIterator.foreach(print(_))二十、隐式转换implicit
https://www.cnblogs.com/xia520pi/p/8745923.html
1、如何使用
隐式转换函数是以implicit关键字声明的带有单个参数的函数。这种函数将会自动应用,将值从一种类型转换为另一种类型。
implicit def a(d: Double) = d.toInt
// 当执行这句代码的时候,内部会自动调用我们自己编写好的隐式转换方法
val i1: Int = 3.5
println(i1)2、使用场景
在scala语言中,隐式转换一般用于类型的隐式调用,亦或者是某个方法内的局部变量,想要让另一个方法进行直接调用,那么需要导入implicit关键字,进行隐式的转换操作,同时,在Spark Sql中,这种隐式转换大量的应用到了我们的DSL风格语法中,并且在Spark2.0版本以后,DataSet里面如果进行转换RDD或者DF的时候,那么都需要导入必要的隐式转换操作。
3、在spark中的使用举例:
RDD这个类没有reduceByKey,groupByKey等函数啊,并且RDD的子类也没有这些函数,但是好像PairRDDFunctions这个类里面好像有这些函数 为什么我可以在RDD调用这些函数呢?
答案就是Scala的隐式转换; 如果需要在RDD上调用这些函数,有两个前置条件需要满足:
- 首先rdd必须是RDD[(K, V)], 即pairRDD类型
- 需要在使用这些函数的前面Import org.apache.spark.SparkContext._;否则就会报函数不存在的错误;
参考SparkContext Object, 我们发现其中有上10个xxToXx类型的函数:
implicit def intToIntWritable(i: Int) = new IntWritable(i)
implicit def longToLongWritable(l: Long) = new LongWritable(l)
implicit def floatToFloatWritable(f: Float) = new FloatWritable(f)
implicit def rddToPairRDDFunctions[K, V](rdd: RDD[(K, V)])
(implicit kt: ClassTag[K], vt: ClassTag[V], ord: Ordering[K] = null) = {
new PairRDDFunctions(rdd)
}这么一组函数就是隐式转换,其中rddToPairRDDFunctions,就是实现:隐式的将RDD[(K, V)]类型的rdd转换为PairRDDFunctions对象,从而可以在原始的rdd对象上 调用reduceByKey之类的函数;类型隐式转换是在需要的时候才会触发,如果我调用需要进行隐式转换的函数,隐式转换才会进行,否则还是传统的RDD类型的对象;
发生类型不匹配的函数调用时, scala会尝试进行类型隐式转换;首先优先进行函数参数的类型转换,如果可以转换, 那么就完成函数的执行; 否则尝试去对函数调用对象的类型进行转换; 如果两个尝试都失败了,就会报方法不存在或者类型不匹配的错误;4、scala隐式的3中使用方式:隐式值、隐式视图、隐式类
4.1、隐式值
def person(implicit name : String) = name
person // 出错:
error: could not find implicit value for parameter name: String
person
^
修改:
implicit val p = "mobin"
person // 正确。
如果又添加了个:
implicit val p1 = "mobin1"
person // 出错:
error: ambiguous implicit values:
both value p of type => String
and value p1 of type => String
match expected type String
person
^4.2、隐式视图
4.2.1、隐式转换为目标类型:把一种类型自动转换到另一种类型
def foo(msg : String) = println(msg)
foo(10) // 出错:
error: type mismatch;
found : Int(10)
required: String
foo(10)
^
修改:
implicit def intToString(x : Int) = x.toString
foo(10) // 正确
其中intToString就是 隐式视图
4.2.2、隐式转换调用类中本不存在的方法
使对象能调用类中本不存在的方法
class SwingType{
def wantLearned(sw : String) = println("兔子已经学会了"+sw)
}
object swimming{
implicit def learningType(s : AminalType) = new SwingType
}
class AminalType
object AminalType extends App{
import com.mobin.scala.Scalaimplicit.swimming._
val rabbit = new AminalType
rabbit.wantLearned("breaststroke") //蛙泳
}可以将隐式转换函数定义在伴生对象中,在使用时导入隐式视图到作用域中即可。
其通常用在于以两种场合中:
1.如果表达式不符合编译器要求的类型,编译器就会在作用域范围内查找能够使之符合要求的隐式视图。如例2,当要传一个整数类型给要求是字符串类型参数的方法时,在作用域里就必须存在Int => String的隐式视图
2.给定一个选择e.t,如果e的类型里并没有成员t,则编译器会查找能应用到e类型并且返回类型包含成员t的隐式视图。
4.3、隐式类
在scala2.10后提供了隐式类,可以使用implicit声明类,但是需要注意以下几点:
1.其所带的构造参数有且只能有一个
2.隐式类必须被定义在类,伴生对象和包对象里
3.隐式类不能是case class(case class在定义会自动生成伴生对象与2矛盾)
4.作用域内不能有与之相同名称的标示符
object Stringutils {
implicit class StringImprovement(val s : String){ //隐式类
def increment = s.map(x => (x +1).toChar)
}
}
object Main extends App{
import com.mobin.scala.implicitPackage.Stringutils._
println("mobin".increment)
}编译器在mobin对象调用increment时发现对象上并没有increment方法,此时编译器就会在作用域范围内搜索隐式实体,发现有符合的隐式类可以用来转换成带有increment方法的StringImprovement类,最终调用increment方法。
5、Scala 隐私注意事项
5.1 转换时机
1.当方法中的参数的类型与目标类型不一致时
2.当对象调用类中不存在的方法或成员时,编译器会自动将对象进行隐式转换
5.2 解析机制
即编译器是如何查找到缺失信息的,解析具有以下两种规则:
1.首先会在当前代码作用域下查找隐式实体(隐式方法 隐式类 隐式对象)
2.如果第一条规则查找隐式实体失败,会继续在隐式参数的类型的作用域里查找
类型的作用域是指与该类型相关联的全部伴生模块,一个隐式实体的类型T它的查找范围如下:
(1)如果T被定义为T with A with B with C,那么A,B,C都是T的部分,在T的隐式解析过程中,它们的伴生对象都会被搜索
(2)如果T是参数化类型,那么类型参数和与类型参数相关联的部分都算作T的部分,比如List[String]的隐式搜索会搜索List的
伴生对象和String的伴生对象
(3) 如果T是一个单例类型p.T,即T是属于某个p对象内,那么这个p对象也会被搜索
(4) 如果T是个类型注入S#T,那么S和T都会被搜索
5.3 转换前提
1.不存在二义性(如例1)
2.隐式操作不能嵌套使用,即一次编译只隐式转换一次(One-at-a-time Rule)
Scala不会把 x + y 转换成 convert1(convert2(x)) + y
3.代码能够在不使用隐式转换的前提下能编译通过,就不会进行隐式转换。
二十一、scala全排序过滤字段,求 1 to 4 的全排序, 2不能在第一位, 3,4不能在一起
import util.control.Breaks._
- 1 to 4 的全排序
- 2不能在第一位
- 3,4不能在一起
object LocalSpark extends App{
override def main(args: Array[String]): Unit = {
List(1,2,3,4).permutations.filter(list=>list(0) != 2).map(list=>{
var num =0
breakable{
for(x<- 0 to (list.size-1)){
if(list(x)==3 && x<3 && list(x+1)==4) break
if(list(x)==3 && x>0 && list(x-1)==4) break
num +=1
}
}
if(num <4){
List()
}else{
list
}
}).filter(list=>list.size>3).foreach(println(_))
}
}
结果
List(1, 3, 2, 4)
List(1, 4, 2, 3)
List(3, 1, 2, 4)
List(3, 1, 4, 2)
List(3, 2, 1, 4)
List(3, 2, 4, 1)
List(4, 1, 2, 3)
List(4, 1, 3, 2)
List(4, 2, 1, 3)
List(4, 2, 3, 1)二十二、scala模式匹配的技巧
https://www.cnblogs.com/linxizhifeng/p/9269756.html
值的匹配。
模式匹配中使用if守卫(在函数中使用模式匹配的情况下,有多个参数)
模式匹配中对下划线这种情况进行重命名,比如直接将 _ 写为 _score,之后就可以使用把_score当做变量使用了。
对类型进行匹配,比如匹配int:case e1:int,比如匹配string:case:string
对array元素进行匹配:可以依据array里元素的个数进行匹配,array里的元素的内容进行匹配,支持通配符
对list元素进行匹配:同array,只不过需要用::分隔不同的元素,尾部用Nil
对case class进行匹配:比如 case Stutent(name,classroom) => println(name,classroom)
对option进行匹配:case Some(x) => println(x) case None=> println(“空”)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









