







• Motivation of studying data structures
• Language to study data structures
• Abstraction
• Huffman coding & dynamic queues
• Information hiding
• Encapsulation
• Efficiency in space & time
• Static vs dynamic data structures
一、Motivation
1. 为什么写程序?
程序是为了解决实际问题或实现某种功能。程序的编写目标通常是实现业务需求、自动化处理等。
2. 为什么要编写高质量的软件?
高质量的软件能够保证系统的稳定性、安全性和可维护性,避免故障和不必要的成本。
3. 如何编写高质量的软件?
通过规范化的设计、良好的编码实践和充分的测试来确保软件质量。
4. 为什么数据结构与高质量的软件设计相关?
数据结构直接影响程序的效率、可扩展性和维护性。选择合适的数据结构可以提高程序的性能和可操作性。
二、Menu (课程大纲)
1. Data structures
• 数据结构:数据结构是组织和存储数据的方式,不同的数据结构适用于不同类型的操作和问题。
2. Motivation of studying data structures
• 学习数据结构的动机:掌握数据结构能够帮助我们更高效地解决问题,提升程序性能。
3. Language to study data structures
• 学习数据结构的语言:可以使用伪代码、Python、C、C++、Java等语言来实现和理解数据结构。
4. Abstraction
• 抽象:通过抽象,可以把复杂的实现细节隐藏,只暴露必要的接口或操作,使得数据结构的使用更加简洁和直观。
5. Huffman coding & priority queues
• 霍夫曼编码和优先队列:霍夫曼编码用于数据压缩,优先队列是一种数据结构,常用于任务调度和优化问题。
6. Information hiding
• 信息隐藏:通过封装和抽象,隐藏数据结构的实现细节,只向外部暴露必要的功能。
7. Encapsulation
• 封装:将数据和操作封装在一个单位内,从而控制对数据的访问,增强数据安全性。
8. Efficiency in space & time
9. Static vs dynamic data structures
• 静态与动态数据结构:静态数据结构的大小固定,而动态数据结构的大小可以随需求变化。
三、Data structures cover (数据结构内容)
1. 数据结构设计中的一般问题:设计数据结构时需要考虑如何高效地存储数据以及如何快速访问和操作数据。
2. 一维和多维数组:数组是最基本的数据结构,适用于存储线性和多维的数据。
3. Linked lists, doubly-linked lists and operations on these data structures
• 链表、双向链表及其操作:链表是一种基本的数据结构,支持动态插入和删除操作,双向链表允许在两个方向上进行遍历。
4. Stacks and operations on stacks
• 栈及栈上的操作:栈是一种先进后出(LIFO)数据结构,常用于函数调用和回溯算法。
5. Queues and operations on queues
队列是先进先出(FIFO)数据结构,常用于任务调度、消息传递等场景。
7. Maps and operations on maps
映射是通过键值对存储数据的数据结构,用于高效查找。
8. Trees & Graphs
树是一种层次结构的数据结构,图用于表示对象之间的关系,广泛应用于路径寻找、网络分析等领域。
四、Data structures (数据结构的定义)
1. A data structure is a systematic way of organising a collection of data for efficient access
数据结构是高效访问数据的有序数据集合的组织方式:数据结构的目的是提高对数据的访问效率,使得数据处理更加高效。
2. Every data structure needs a variety of algorithms for processing the data in it
每种数据结构都需要多种算法来处理其中的数据:不同的数据结构需要不同的操作,如插入、删除、查找等。
3. Algorithms for insertion, deletion, retrieval, etc.
• 插入、删除、检索等算法:这些操作是数据结构的基本功能,能够实现数据的增删改查。
4. So, it is natural to study data structures in terms of properties, organisation, operations
因此,研究数据结构时,应该关注其属性、组织结构和操作:通过研究这些方面,能够理解数据结构的优缺点及其适用场景。
5. This can be done in a programming language independent way (why?)
这可以通过编程语言无关的方式来进行(为什么?):数据结构的设计和分析是独立于特定编程语言的,理论上可以在任何编程语言中实现。
6. Has been done in Pseudo code, Python, C, C++, Java, etc.
数据结构的实现方法在多种编程语言中都可以找到。
五、Why data structures?
1. 像布尔值、整数、字符串以及简单数组这样的基本类型不够吗?
• 基本类型和简单数组虽然适合一些简单的应用,但无法有效处理复杂的数据和算法问题。
2. 是的,因为计算机的内存模型本质上是一个整数数组
• 计算机内存存储的是原始数据,但数据结构能够更有效地组织和管理这些数据。
3. But, this model…
• is conceptually inadequate & low level:这种模型概念上不够高效,无法表达复杂的数据。
• makes it difficult to describe complex algorithms:基础操作太简单,使得描述复杂算法变得困难。
六、Why not just in Java?
1. 为什么我们要以语言无关的方式学习数据结构?
数据结构是跨编程语言的,掌握数据结构的设计思路可以在不同编程语言中实现。
Java只是面向对象语言中的一种
学习数据结构时,不应局限于特定语言,数据结构的原理是跨语言的。
世界上最受欢迎的编程语言每五到十年就会变化一次
这表明学习数据结构和算法的概念比特定语言的实现更为重要。
然而,数据结构自高级编程语言发明以来就存在
数据结构的基本原理是长期不变的,随着编程语言的发展,数据结构仍然是核心内容。
• 我们必须能够在其他语言中实现数据结构
• 数据结构的实现应该能够在不同的编程语言中实现,掌握数据结构的核心概念有助于跨语言应用。
• 我们还需要抽象的背景来学习算法
• 数据结构是学习算法的基础,理解数据结构能够帮助我们更好地理解算法。
七、Data structures that we will consider
We will study various data structures such as
• Arrays
• Lists
• Stacks
• Queues
• Maps
• Trees
• Graphs
在每种情况下,我们将定义结构,给出示例,并展示如何在Java或伪代码中直接或通过其他先前定义的数据结构实现该结构。
八、Software Quality (软件质量)
1. 在开始设计和实现数据结构之前,需要明确软件开发的目的和目标。
2. 软件开发过程中追求高质量是至关重要的。
3. 提示开发高质量软件时,设计原则(design principles)的运用是成功的关键。
4. 最终软件的质量可以通过多种方式来衡量:
• correctness(正确性)
• efficiency(效率)
5. 数据结构的设计直接影响软件的质量,好的数据结构能够提高系统的效率和可维护性。
6. 有助于开发高质量软件的主要原则:抽象、信息隐藏、封装。
• 软件开发的三大基本原则:
abstraction, information hiding, encapsulation,它们对编写高质量软件至关重要。
7. 数据结构设计如何有助于提升最终系统的质量。
8. 与数据结构相关的另一个重要设计问题,这有助于编写高质量的软件:静态和动态结构的选择。
• 选择静态数据结构还是动态数据结构会对软件的性能和灵活性产生重要影响。
九、Abstraction (抽象)
1. 我们可以将抽象作为一个过程或实体来讨论。
(抽象有两种含义,可以是提取必要信息的过程,也可以是简化表示的实体。)
• 作为过程,抽象指的是提取某个项目或一组项目的基本细节,同时忽略不必要的细节。
• 作为实体(entity),抽象表示一个模型、视图(view)或某种实际项目(actual item)的表示,省略( leaves out)了项目的一些细节。
2. 抽象规定某些信息比其他信息更重要,但并未提供处理不重要信息的具体机制(mechanism)。
3. 抽象在软件开发中的不同应用方式。
(1) data abstraction: 数据抽象的目的是去除无关的实现细节,只关注数据如何存储和操作。
(2) procedural abstraction: 过程抽象是简化任务实现过程,保留关键操作,忽略不必要的细节。
1. Key of abstraction (抽象的关键)
• 提取组件的共性(commonality)并隐藏它们的细节
• 抽象通常关注对象/概念的外部视图(outside view)
2. Abstraction examples (抽象示例)
(1) 看地图时,我们画出道路和高速公路、森林,而不是每棵树
(2) 看各种银行账户时,我们能提取出哪些共性?
• 在多种对象(如银行账户)中提取共性,帮助我们设计统一的抽象模型。
• Using an O-O approach(使用面向对象的方法)
• 面向对象的抽象方法可以帮助我们提取不同账户的共性特征,如账户号、客户名和余额等。
• States: AccountNo, CustomerName, Amount
• Behaviour: Credit, Debit, and GetAmount 存款、取款和获取余额
十、 Use of abstraction in design (设计中抽象的使用)
1. 设计中的抽象:将事物分成不同的组,并分别处理每个组的细节
• 抽象帮助我们将复杂的问题分解成更容易管理的小部分,以便逐个解决。
2. 抽象导致了自顶向下的方法 (a top-down approach)
• 抽象方法通常从问题的整体开始,然后逐渐分解,逐步处理每个子部分。
大多数项目都可以通过抽象来改善:
• 从高层次思考。你想要达成什么目标?应该有一个目标
• 将这个目标细化为各个部分(组件)Refine this goal into parts
• 思考实现每个组件的多种方式
十一、 Communication based on Huffman coding (基于霍夫曼编码的通信)
• 霍夫曼编码是一种压缩算法,它基于消息中字符的频率进行编码,频率较高的字符使用较短的编码。
• 接收方使用霍夫曼解码器将接收到的编码消息还原为原始数据。
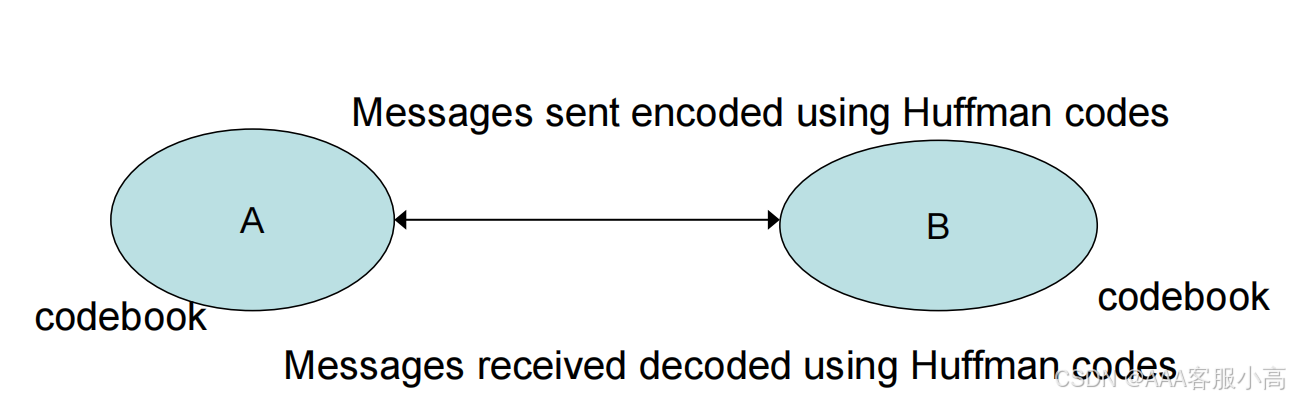
1. Huffman coding - Abstraction example
(1) 霍夫曼编码是一种有效的编码(和解码)文本(或非文本)数据的方法。
encoding (and decoding) textual (or non-textual) data
它已被广泛用于通信中,例如源编码source coding
• 霍夫曼编码的主要应用领域是数据压缩,在数据传输中可以减少带宽的使用。
(2) 一个大型信息系统可能需要一段软件来执行存储在磁盘上的数据或从某个数据源生成的数据的霍夫曼编码
• 这表明霍夫曼编码可以广泛应用于数据存储和传输系统。
(3) 霍夫曼编码软件使用优先队列来完成其任务The Huffman encoding software uses priority queue to accomplish its tasks
• 优先队列在霍夫曼编码中的作用是选择频率最高的字符进行编码。
(4) Important points:
• 通过抽象,开发者无需关注优先队列的实现细节,而专注于其功能和设计。
• 通过抽象程序员能够专注于使用给定的优先队列函数设计特定模块
十二、Huffman coding – Key ideas (霍夫曼编码 - 关键概念)
1. 霍夫曼编码根据数据出现的频率(图像中的像素、文本中的字母)来分配不同长度的编码,频率高的数据项使用更短的编码。
frequency of occurrence of a data item (pixel in images, alphabet in texts)
2. 其原理是使用较少的位数来编码(encode)更频繁出现的数据
• 通过这种方法,能够减少高频数据的存储和传输成本。
3. 每个数据项都会有一个对应的编码,可以通过代码本(Code Book)来查找和解码。
4. 为了能够正确解码,发送方需要同时传输(transmitted)代码本和编码后的数据。
十三、Huffman编码 的基本原理
1. Huffman编码—code book
• 这张图展示了Huffman编码的生成方式,解释了每个符号(如A, B, C等)在编码过程中分配的比特数,列出了符号及其出现的频率,并给出了每个符号对应的Huffman代码及其比特数。
• Huffman编码通过频率来为每个符号分配编码,频率高的符号使用较短的编码,从而实现数据压缩。

2. 构建Huffman编码树
en-/de-coding tree
• 这张图展示了Huffman编码树的构建过程。图中展示了如何从多个符号和其频率开始,逐步合并频率最低的符号,直到构建出完整的编码树。
• 这是Huffman算法的一个关键步骤,确保了编码的效率和压缩率。
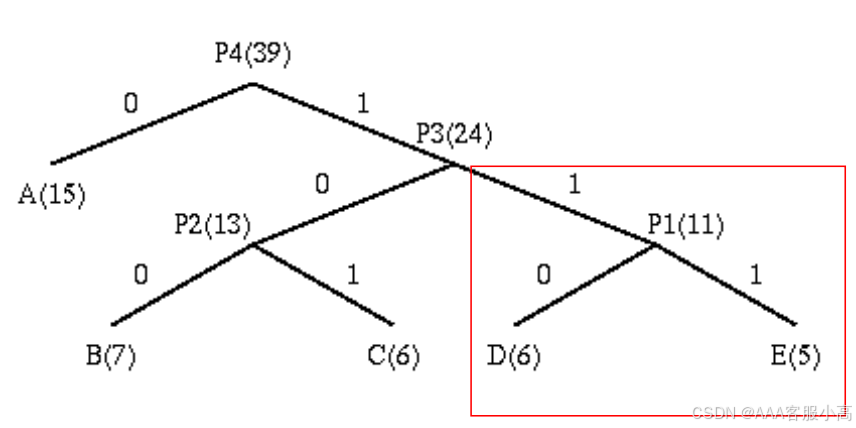
List: A(15),B(7),C(6),D(6),E(5) --> List: A(15),B(7),C(6),P1(11)
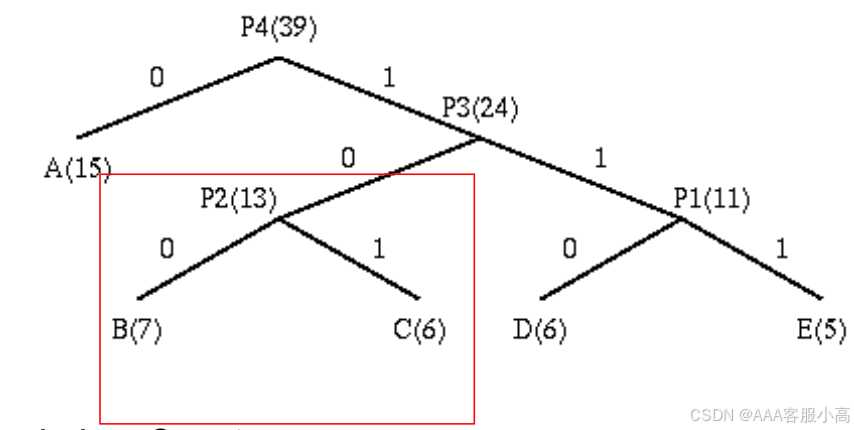
List: A(15),B(7),C(6),P1(11) --> List: A(15),P1(11),P2(13)
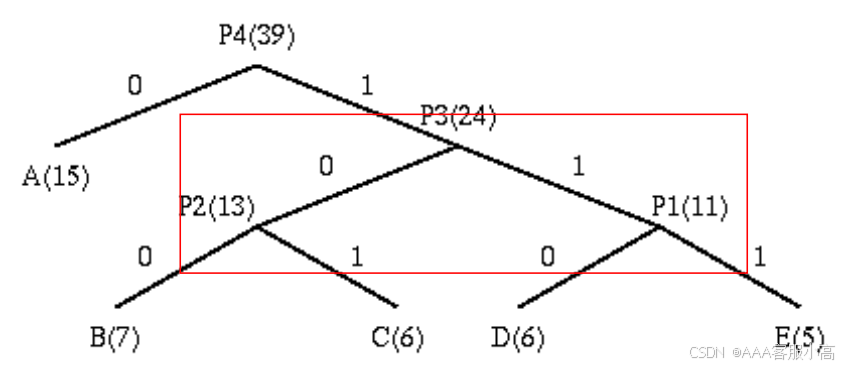
List: A(15),P1(11),P2(13) --> List: A(15),P3(24)
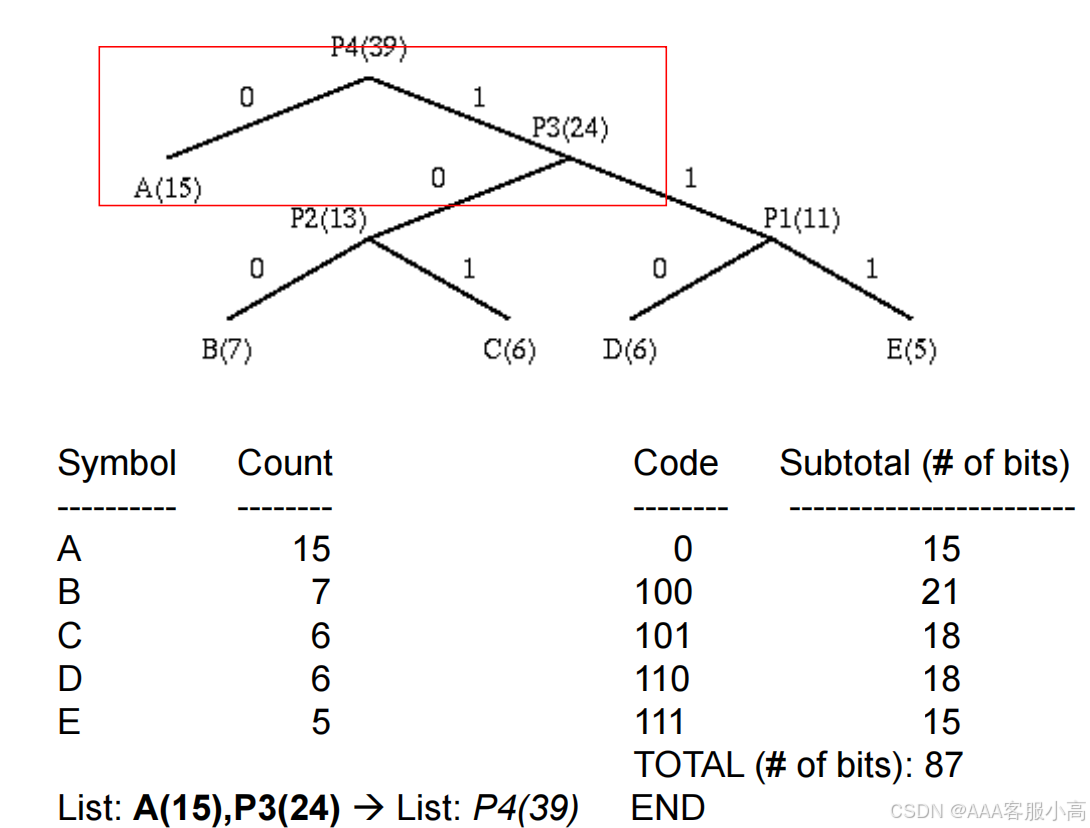
3. Huffman Decoding
• 中文: 这张图片展示了Huffman解码的过程。给定的编码表和二叉树可以帮助解码接收到的二进制字符串,以便还原原始符号。
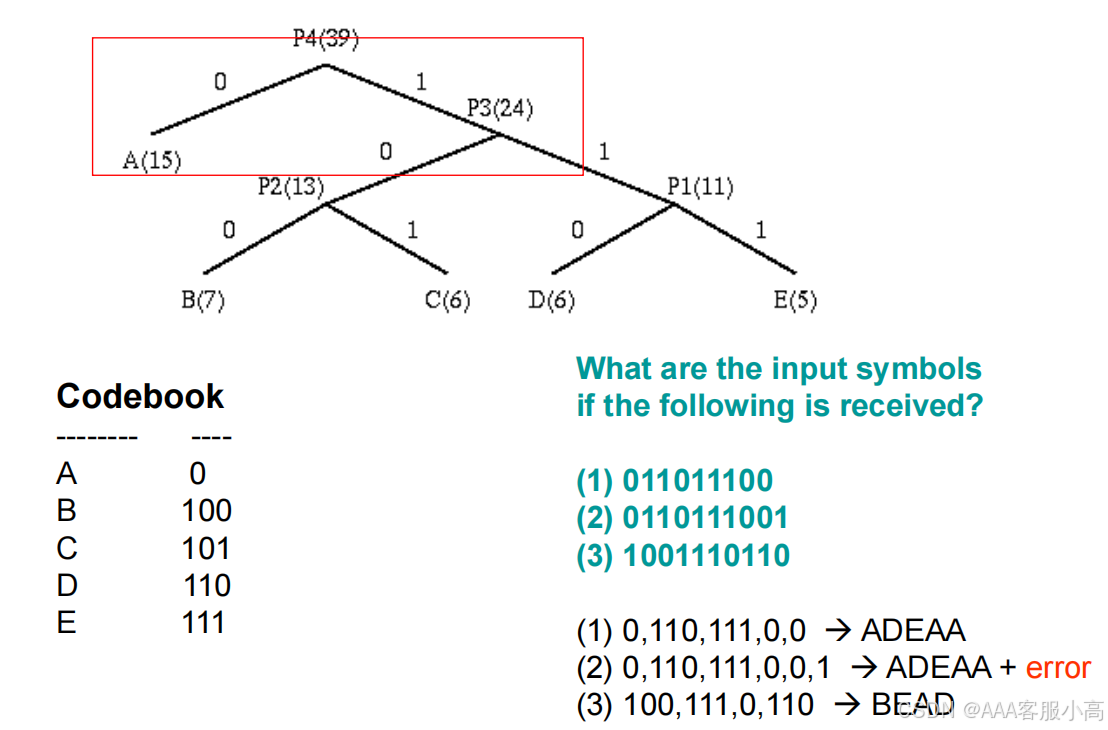

10011 解码为 BE
01101011 解码为 ADE
0010001 由于包含无法解码的部分,导致它是错误的
(1)Why is Huffman coding optimal?
它通常通过最小化编码长度来压缩信息
(2)Huffman编码设计中的抽象使用,涉及编码、解码和码本管理(Codebook management)的算法与数据结构
4.Huffman编码中的优先队列和树的使用
(1)优先队列的基本功能
• 优先队列是一种数据结构,它维护一组元素,并根据每个元素的优先级(通常是元素的值或权重)进行排序。优先队列支持以下基本操作:
• EXTRACT-MIN操作在每次合并过程中用于选出频率最低的两个节点进行合并,这保证了Huffman编码树在频率较低的符号上获得较长的编码,频率较高的符号获得较短的编码。
• INSERT操作在每次合并后用于将新的节点(合并后的树)重新插入队列,以便下一步继续选择最小频率的节点进行合并。

(2)具体步骤
• 初始化优先队列:首先,将每个符号及其频率放入一个优先队列中。优先队列会根据频率对这些符号进行排序,使得频率最小的符号在队列的前面。
• 提取最小元素:每次从优先队列中提取最小元素,即频率最低的两个节点(或树)。这些节点将合并成一个新的节点,新节点的频率是两个最小元素频率之和。
• 插入合并后的节点:将合并后的节点重新插入到优先队列中。该节点将继续与其他节点进行合并,直到队列中只剩下一个节点,即完成了Huffman树的构建。
• 构建最优树:通过不断的提取最小元素和合并,优先队列确保每次合并的是频率最小的节点,从而得到最优的Huffman编码树。
(3) Priority Queue
优先队列是一种存储带有优先级的元素的数据结构,其中每个元素都有一个与之关联的值(或“键”)。
A priority queue is a data structure for maintaining a set Q of elements each with an
associated value (and key).
该数据结构支持以下操作:
• INSERT(Q, x):将元素 x 插入队列 Q。
• MIN(Q):返回队列 Q 中具有最小键值的元素,但不移除它。
• EXTRACT-MIN(Q):移除并返回队列 Q 中具有最小键值的元素。
(4) 二叉树(Binary Tree)
二叉树 数据结构及其相关操作:二叉树用于维护一组节点,每个节点都有一个关联的值,并具有左右子节点。
A binary tree is a data structure for maintaining a set Q of nodes each with an associated value
and options of left and right child nodes
以下是二叉树的基本操作:
• ALLOCATE-NODE:创建一个新的节点,并返回对该节点的引用。
• right(z):返回节点 z 的右子节点。
• left(z):返回节点 z 的左子节点。
(5)Implementation of Huffman coding using priority queues & binary trees

Huffman编码算法 的伪代码:
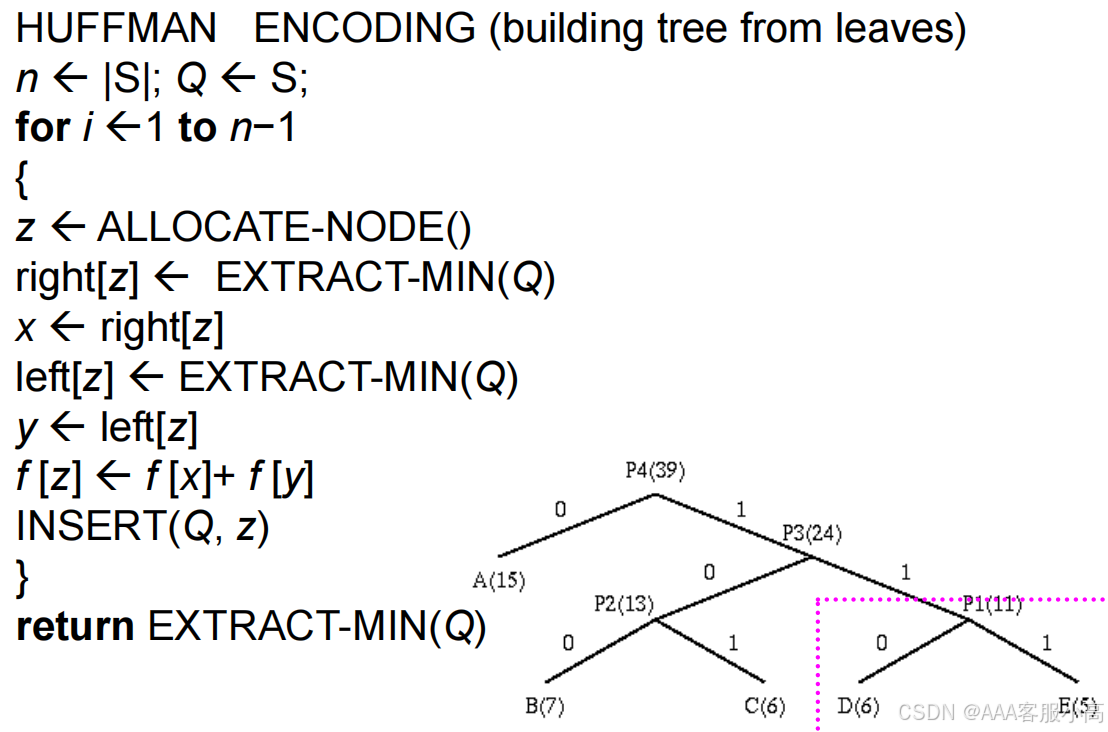
S 是包含每个字符及其对应频率的数据结构,Q 是优先队列。
1. 初始化:
n ← |S|; Q ← S;
• S 是一个包含每个字符和它在文本中出现频率的集合。
• n 是 S 中元素的数量,表示字符的种类数量。
• Q 是一个优先队列,用来存储字符频率(最初是从 S 中复制的字符和频率对)。
队列是按频率从小到大排序的
2. 循环迭代,构建编码树:
for i ← 1 to n-1
{
z ← ALLOCATE-NODE(); // 创建一个新节点
right[z] ← EXTRACT-MIN(Q); // 从队列中提取频率最小的元素,作为右子节点
x ← right[z]; // 获取右子节点
left[z] ← EXTRACT-MIN(Q); // 再次提取频率最小的元素,作为左子节点
y ← left[z]; // 获取左子节点
f[z] ← f[x] + f[y]; // 合并两个子节点的频率到新节点中
INSERT(Q, z); // 将新节点插入队列中
}
• 创建新节点:每次循环时,都会创建一个新的节点 z,用于存放合并后的结果。
每次迭代都会从队列中提取出两个最小的元素(即频率最小的字符),并将它们合并为一个新的节点。
3. 最终返回树的根节点:
return EXTRACT-MIN(Q);
叶子节点到根节点的路径长度即为该字符的编码
(6) implement the algorithm for Huffman decoding
• Input: a pointer to the decoding tree root z & received Huffman encoded binary string i
解码树的根节点 z 和接收到的 Huffman编码的二进制字符串 i
• Output: Huffman decoded string
解码后的Huffman字符串
通过在解码树上从根节点遍历二进制字符串,每遇到一个 0 或 1 就向左或向右遍历,直到遇到叶子节点,得到原始字符。
十四、Information hiding
信息隐藏 与 隐私 和 安全 的关系。信息隐藏通过隐藏内部数据或信息的细节,防止外部直接访问和操控,确保数据的隐私性和安全性。
• The important details of a module that a user needs to know form the specification of a module
• So, information hiding means that modules are used via their specifications, not their implementations.
1. Information hiding example
汽车与司机之间的交互(interface with drivers)提供了一个很好的例子来说明标准化界面的重要性。
汽车提供了一套标准的控制界面(a standard interface):
– pedals,
– wheel,
– shifter,
– signals,
– switches
踏板、方向盘、换挡杆、转向信号和各种开关等。人们通过训练和获得驾照(licensed)来学会如何使用这些标准界面。这意味着人们只需要学会开车,而不需要在每次驾驶新型号的汽车时学习全新的驾驶方式。
2. 信息隐藏的使用案例
(1)隐藏数据的物理存储布局。如果存储布局发生变化,只有程序中一小部分受到影响,而不需要修改整个程序。
物理存储布局(Physical Storage Layout):指的是数据在计算机存储器中的实际组织和存放方式。
(2)如果一个程序最初用三个浮点数变量来表示一个三维点(x, y, z),后来为了提高效率,改用一个包含三个元素的数组来表示同一个三维点。如果程序是按照信息隐藏的原则来设计的,那么这个改变只需要修改表示三维点的那部分代码,而不会影响到程序的其他部分
(3) 设计时考虑到信息隐藏的模块将保护程序的其余部分免受此类变化的影响。
3. 面向对象中的信息隐藏
在 面向对象编程 中,如何通过隐藏对象内部的实现细节来实现信息隐藏。对象通过公开(publicizes)它的服务(方法)来告诉用户它能做什么,但隐藏它是如何实现这些服务的,以及它内部维护的数据。
十五、Java method signature
1. 方法签名是方法名称和其参数的数量(及其类型和顺序)的组合。
setMapReference(int xCoordinate, int yCoordinate) 是一个方法签名
表示方法名称是 setMapReference,参数是两个 int 类型的 xCoordinate 和 yCoordinate。
十六、Encapsulation
封装可以看作一个过程或实体。
作为过程(process),封装指将数据或功能封闭在一个容器内。
作为实体(entity),封装指一个包含数据和功能的封闭包裹
• As a process, encapsulation means the act of enclosing one or more items (data/functions) within a (physical or logical) container.
• As an entity, encapsulation, refers to a package or an enclosure that holds (contains, encloses) one or more items (data/functions).
这个容器(enclosure)的内部与外部之间的分界线(separator)有时被称为“墙”或“屏障”(wall or barrier)
1. Encapsulation in an O-O world
在面向对象编程中,封装指将对象所需的所有资源(方法和数据)封闭在一个对象内。对象对外公开它的接口,其他对象可以通过这些接口与其交互,而无需知道对象的具体实现
encapsulation is the inclusion within an object of all the resources needed for the object to function – i.e., the methods and the data
The object interface consists of public methods and instantiated data.
2. Encapsulation in communication
在通信中,封装是将一个数据结构包含在另一个数据结构中,以使第一个数据结构对外部隐藏。例如,TCP/IP格式的包可以被封装在ATM帧内
a TCP/IP-formatted packet can be encapsulated within an ATM frame
在 ATM(异步传输模式) 网络框架的发送和接收过程中,封装的数据包 实际上是一个 比特流(bit stream),它描述了数据的传输过程
Within the context of sending and receiving the ATM frame, the encapsulated packet is simply a bit stream that describes the transfer.
3. Packet encapsulation
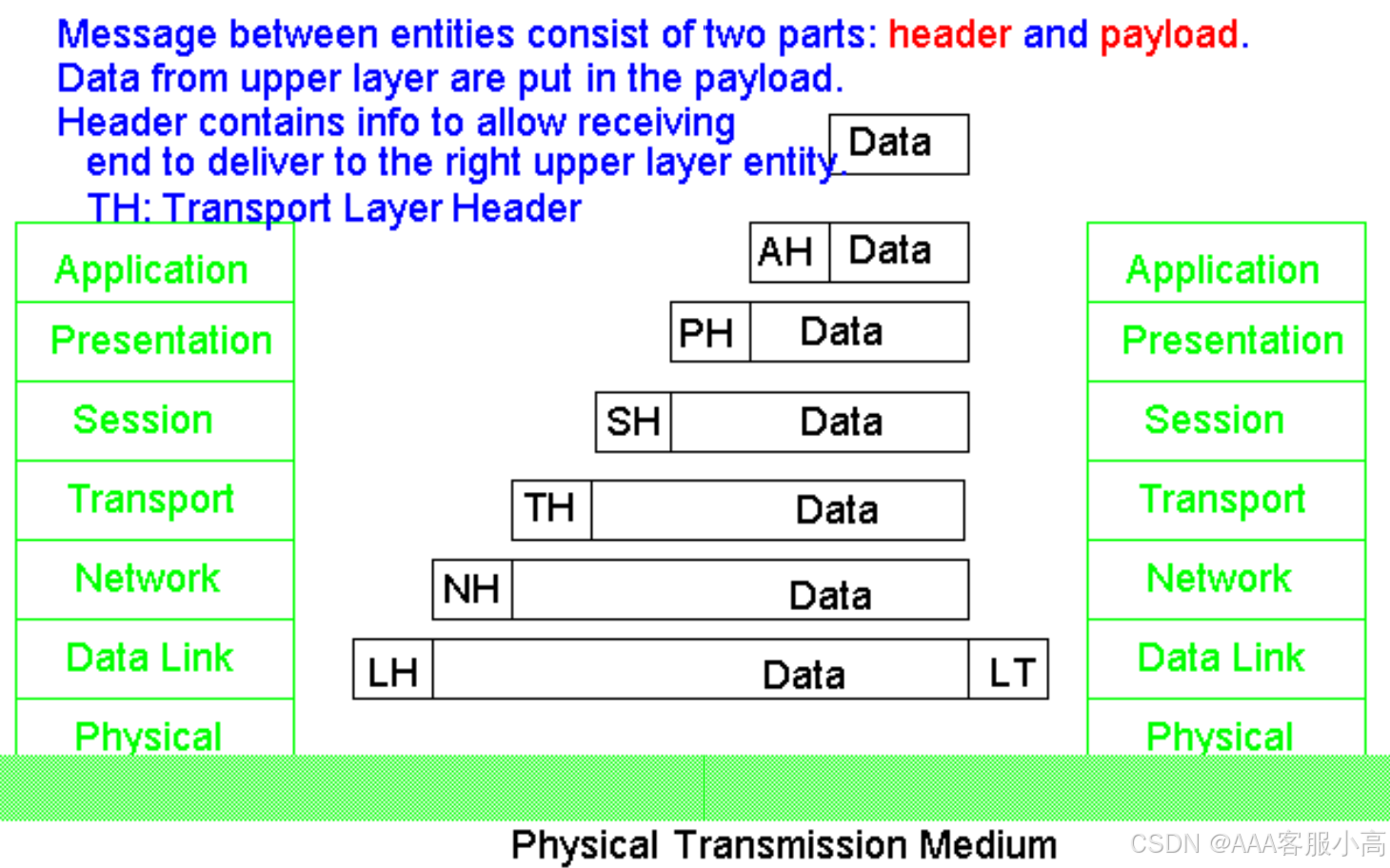
数据包封装 。它显示了消息在各个协议层之间的封装过程,包含头部信息和有效载荷,其中头部包含传输的信息,帮助接收方将数据正确地传递到上层应用。
从应用层开始,数据逐层被封装,每一层都会添加必要的头部信息,这些头部信息包含了控制数据传输、路由、错误检测等所需要的各种信息。每一层都为数据传输过程提供必要的支持。
• 头部信息:每一层添加的头部信息有助于确保数据能够正确地被路由、接收、处理和重组。比如,传输层头部包含端口号和顺序信息,网络层头部包含IP地址,数据链路层头部包含MAC地址等。
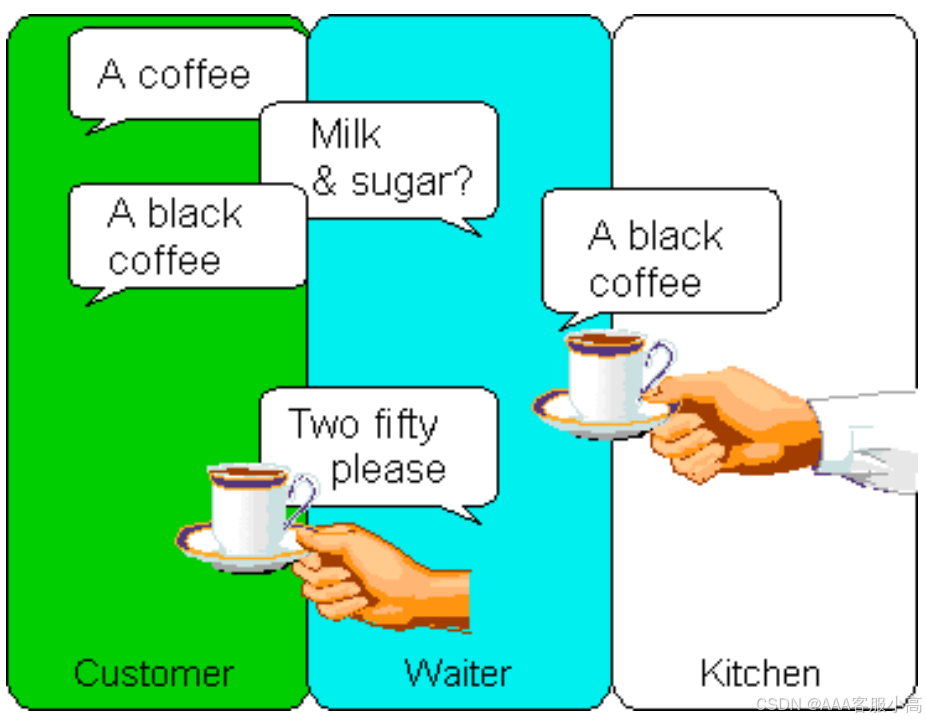
4. Encapsulation example – 'cup of coffee‘
顾客、服务员和厨房是三个封装的对象。顾客、服务员和厨房分别承担不同的角色,互相通过接口交互,而隐藏了各自的内部实现
十七、Comparisons
• 抽象 是一种技术,帮助我们确定哪些信息对模块的用户重要,哪些信息不重要。
• 信息隐藏 是一个原则,要求将所有不重要的信息隐藏,以防止用户接触。
• 封装 是一种技术,负责将应隐藏的信息包装起来,并使那些需要被看到的信息显现出来。
十八、Advantages
抽象和封装的优势
Using the processes of abstraction and encapsulation under the guidinglines of information hiding, we enjoy the following advantages:
• 使程序更加 模块化(modular programs),设计和理解起来更加简洁。
• 消除(eliminated)或最小化(minimised)数据直接操作引起的副作用。
• 错误局部化(Localisation of errors):只有定义在类上的方法才能操作类的数据,这使得测试变得更加集中。
• 程序模块更容易阅读、修改和维护。
十九、数据结构与抽象、信息隐藏和封装
1. 数据结构是程序中的一个重要组成部分,指定数据结构时需要使用 抽象、信息隐藏 和 封装
• 在模块化编程( modular programming)中使用 抽象、信息隐藏 和 封装 可以进一步发展数据结构的设计。
• 更好的数据结构设计有助于更高效的模块化编程。
Exercise
快递服务设计练习,要求使用 信息隐藏 和 封装 概念来设计一个快递服务包(courier service package),包含以下角色:
– Sender 发送者
– Courier receptionist 快递接待员
– Shipping agent (or delivery agent) 运输代理(或送货员)
– Receiver 接收者
• 识别每个角色的服务或功能。
• 通过 Java 方法签名的接口来阐明如何实现封装,突出服务边界。
• Sender类的接口:
public class Sender {
public void sendPackage(Package package); // 发送包裹
public void provideReceiverInfo(Receiver receiver); // 提供接收者信息
public void payFee(double amount); // 支付费用
}
• CourierReceptionist类的接口:
public class CourierReceptionist {
public void receivePackage(Package package); // 接收包裹
public void checkFee(Package package); // 检查包裹运费
public void generateShippingLabel(Package package); // 生成发货单
}
• ShippingAgent类的接口:
public class ShippingAgent {
public void arrangeShipping(Package package); // 安排运输
public void trackPackage(Package package); // 跟踪包裹
public void confirmDelivery(Package package); // 确认送达
}
• Receiver类的接口:
public class Receiver {
public void receivePackage(Package package); // 接收包裹
public void confirmPackage(Package package); // 确认包裹
}
二十、Efficiency: Space
空间效率选择合适的数据结构以最小化内存使用,避免分配不必要的空间。
• 例子:存储图像或地图时,通过向量或位图(bitmaps)表示,或者使用压缩位图(compressed bitmaps)。
• 比较空间效率和便利性之间的权衡(Tradeoffs)。
二十一、Efficiency: Time
1. 合适的数据结构要确保操作执行速度的高效性(based on some well-chosen algorithm)
2. 对于我们的目的来说,执行速度最重要的衡量标准是访问存储在数据结构中的数据项的次数。
数据项访问次数:这是衡量执行速度的一个重要指标,指的是在执行操作时,对数据结构中数据项进行读取或写入的次数。访问次数越少,通常意味着操作越快。
3. Example
在一个学生名单中搜索一个特定的名字。
• 如果名单未排序,最坏的情况是需要查看名单中的每一个名字,即需要进行 n 次访问。
• 如果名单已按字母排序(alphabetically),则可以使用 二分查找(binary search),最坏情况下需要进行 log₂(n) 次访问。

二十二、Static versus dynamic data structures
1. 在选择数据结构时,除了时间和空间效率外,另一个重要的考虑因素是数据项数量是否能根据需要动态调整,或者是否有固定限制。
whether the number of data items it is able to store can adjust to our needs or is bounded
dynamic data structures vs. static data structures
• 动态数据结构 会根据当前需求在运行时增长或收缩(grow or shrink during run-time),比如用于模拟交通流(modelling traffic flow)的结构。
• 静态数据结构 在创建时大小固定,比如存储邮政编码或信用卡号(其格式固定)。
2. 静态是指结构本身在创建时固定,而不是数据本身。
• 静态数据结构 中,数据可以随时间变化,但结构本身的大小是固定的。
• 数据存储在静态和动态数据结构中可能保持不变,但静态数据结构的大小在创建时已经确定,不允许扩展。
the definition of a static data structure we have placed no constraints on when it is created, only that once it is created it will be fixed
1. 静态数据结构的示例
数组的大小在创建时就已经固定。
• 例如,int[] a = new int[50]; 分配了存储 50 个整数的内存空间。
• 即使数组在后续使用中存储不同数量的元素,它的大小仍然固定。
该语言提供了‘new’构造,以指示编译器/解释器需要为哪种数据类型分配多少空间
• 在Java中,即使我们写:
int[ ]a = { 10 , 20 , 30 , 40 } ; 数组也总是动态分配的。
2. 静态数据结构的优点
• 易于指定(ease of specification):编程语言通常提供了一种简单的方法来创建静态数据结构,大小几乎可以是任意的。
• 没有内存分配开销(no memory allocation overhead):由于静态数据结构的大小固定,所以不需要动态内存分配,因此没有额外的内存分配开销。(which takes time)
3. 静态数据结构的缺点
• 必须确保足够的容量(enough capacity):由于静态数据结构的大小是固定的,我们需要确保在创建时分配足够的空间,否则会导致错误。
• 更多的元素?(错误)少的元素?(浪费):如果数据结构中的元素超过固定容量,就会导致错误(如 ArrayIndexOutOfBoundsException);如果存储的元素较少,则会浪费内存空间,虽然内存已经分配但不能用于存储其他数据。
4. 动态数据结构的优点
• 无需预知数据项数量:由于动态数据结构可以根据需要增长或缩小,因此不需要事先知道需要存储多少数据项。
• 高效的内存使用:动态数据结构会在需要时扩展,当数据项减少时也会收缩,始终保持最合适的大小,避免浪费内存空间。
5. 动态数据结构的缺点
• 内存分配/释放开销:每当动态数据结构增长或缩小时,都需要对内存进行分配或释放,这个过程需要消耗时间。
Q&A
1. 时间效率 和 空间效率 是评估算法(和数据结构)性能的指标。对吗?T
时间效率和空间效率是衡量算法或数据结构性能的两个重要指标。时间效率通常指算法执行所需的时间,而空间效率则指算法所需的内存空间。
2. 动态数据结构 在空间效率上一般更好。对吗?T
动态数据结构在空间使用上更为灵活,因为它们可以根据实际需要在运行时增长或缩小,因此避免了固定大小带来的空间浪费。
3. 静态数据结构 在时间效率上通常更好。对吗?T
由于静态数据结构的大小在创建时就已固定,因此它们通常具有较低的操作开销,访问速度较快,不需要动态分配内存,因此在时间效率上通常优于动态数据结构。
4. 信息隐藏 是指软件组件的用户只需要知道初始化和访问组件的基本信息,而不需要了解实现细节。对吗?T
信息隐藏的核心理念是让用户只关心模块的接口,而隐藏模块的内部实现细节,这样可以提高系统的可维护性和可扩展性。
二十三、Application of ‘abstraction’
• 数据挖掘(Data Mining) 是从数据中提取模式的过程,已在多个领域应用以获得良好的经济效益。
• 大数据分析(Big Data Analytics) 是数据挖掘的一个重要领域。
• 数据库中的知识发现(Knowledge Discovery in Databases)(KDD)是数据挖掘下的一个新兴领域,KDD 创建了输入数据的 抽象。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









