






 本文详细介绍了基于PyTorch实现的YOLOv3目标检测模型,包括网络结构(Darknet53、FPN和YOLO层)、数据预处理方法(如Mosaic拼接)以及如何用YOLOv3训练自定义数据集。此外,还提到了模型转换为ONNX和Caffe的步骤。
本文详细介绍了基于PyTorch实现的YOLOv3目标检测模型,包括网络结构(Darknet53、FPN和YOLO层)、数据预处理方法(如Mosaic拼接)以及如何用YOLOv3训练自定义数据集。此外,还提到了模型转换为ONNX和Caffe的步骤。
最近使用YOLOv3进行目标检测,这里总结一下个人对与pytorch版本的YOLOv3的理解,顺便梳理一下思路。
- 网络结构
- 数据预处理方式
- onnx2caffe
代码:https://github.com/ultralytics/yolov3
1 网络结构
YOLOv3的网络结构主要包括三个部分,骨干网络, 类FPN, yolo层:YOLOv3的骨干网络使用的是Darkent53, 网络中大量使用跳层连接,并且为了降低池化层带来的梯度负面效果,直接已使用卷积层的stride=2来实现降采样.作者在实验中发现, darknet53 相较于resnet-152 和resnet-101 ,在分类精度上相差不大,但网络层数较少,且计算速度很快.在新的yolov4中指出, darknet53 在目标检测中,用作特征提取网络效果要强于resnet系列。
为了增强对小目标的检测,YOLOv3使用了类FPN层,使用上采样和融合的做法,在多个尺度的特征图上做检测。
yolo层是对提取的信息进行解码,从而输出检测到的目标信息,(x, y, w, h, score, classses). YOLOv3在每一个尺度, 使用三个预测框进行检测,输出的信息为 3×(5 + classes), 当检测目标的种类为80 时, 输出的维度为 3×(5 + 80) = 255.
2、数据预处理
目前有很多种数据预处理的方法,在训练神经网络时,为了进一步扩充数据,会使用随机裁剪、旋转或者遮挡等的方法。在该版本的YOLOv3中,数据预处理方式较之前有所不同, 主要是增加了一种叫做masiac 的图像拼接方法,随机选择四张图片,进行拼接,而后将拼接好的图像进行随机旋转、裁剪等操作,以扩充数据。
3 使用yolov3训练自己的数据集
首先,准备好自己的训练数据集,并生成yolov3训练所需要的数据格式,(*.data, *.names), 具体格式可以参考文件夹data中给出的示例,将自己的数据集写入其中,这里给出了json转txt的代码,可供参考。
修改yolov3.cfg, 将类别改为自己数据集的类别,并修改全卷积层的filter数目, 即yolo层的classes, 和convolutional 层的filters.
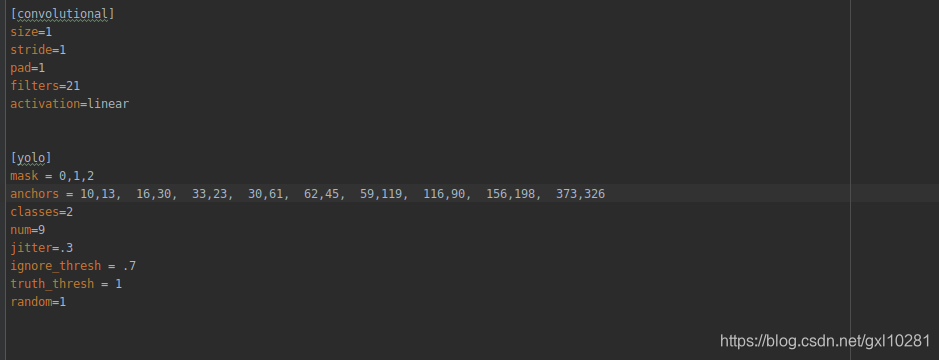
修改超参数,在使用yolov3进行训练时, 可根据自己的GPU大小和数据集特点,对超参数进行必要的调节,主要包括对epoch、batch_size, learning_rate等的调节。
4、onnx2caffe
yolov3训练完自己的数据集后,我们希望在开发板上移植当前模型,因此对模型进行了转换,使用的方法是首先将yolov3转换为onnx,然后利用onnx2caffe的转换工具,将模型转换为caffe所需要的model.转换时,需要注意的是,因为yolo层并不涉及到调参,因此可以将其直接放到caffe中实现。onnx 只转换到yolo层的上一层即可。

















 1302
1302

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









