






茴香豆是 InternLM开源的基于 LLM的群聊知识助手,其提供了一整套前后端 web、android、算法源码,支持工业级商用。其最低运行运行成本低至 1.5G 显存,无需训练适用各行业。
1. 技术报告
参照技术报告HuixiangDou: Overcoming Group Chat Scenarios with LLM-based Technical Assistance。
- 项目目的:为了帮助算法工程师深入了解开源算法项目问答,后又被拓展为即时通讯群聊的助手,如Lack和微信。
- 项目贡献:
- 打通群聊场景的算法链路;
- 验证了text2vec方法在任务拒绝上的有效性;
- 验证了LLM在技术类助手产品上的三个必要需求:1)评分能力;2)in-context learning;3)长文本
1.1 项目改进思路
报告提及本项目在开发过程中依次采用的三种改进思路:
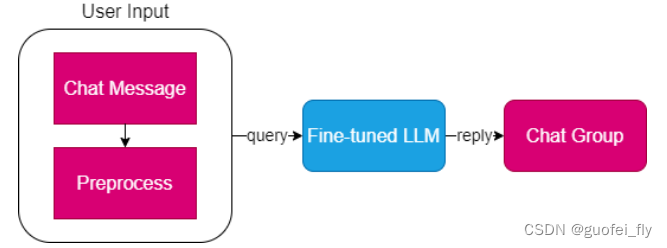
思路一:采用微调后的LLM
用户的输入根据用户id进行分组(因为LLM智能区分system、user和bot三个决策),连续提问进行拼接,同时舍弃了图片、表情和音频等元素。
思路二:改进幻觉
导致幻觉发生的主要原因有两个:1)用户表达的模糊;2)模型导致的幻觉(训练数据和领域知识没有对齐),为了缓解上述两个原因,本项目分别从用户侧和模型侧提出了改善方案:
用户侧:两阶段的拒绝设计(分别为Text2Vec相似度计算和LLM评分计算),来识别用户闲聊等场景;
模型侧:采用RAG+prompt的方式改善模型的输出;
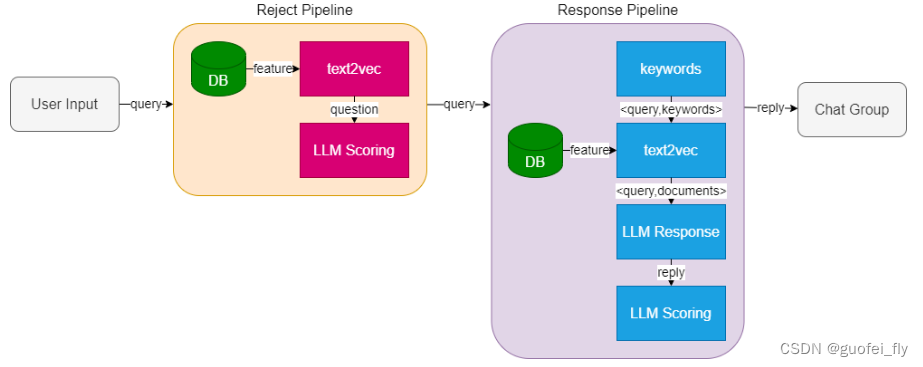
思路三:最终方案
最终方案中通过prompt工程和搜索增强的方式来提升回答的准确率,包括网络搜索、融合Repo知识和语料源打分等具体措施。
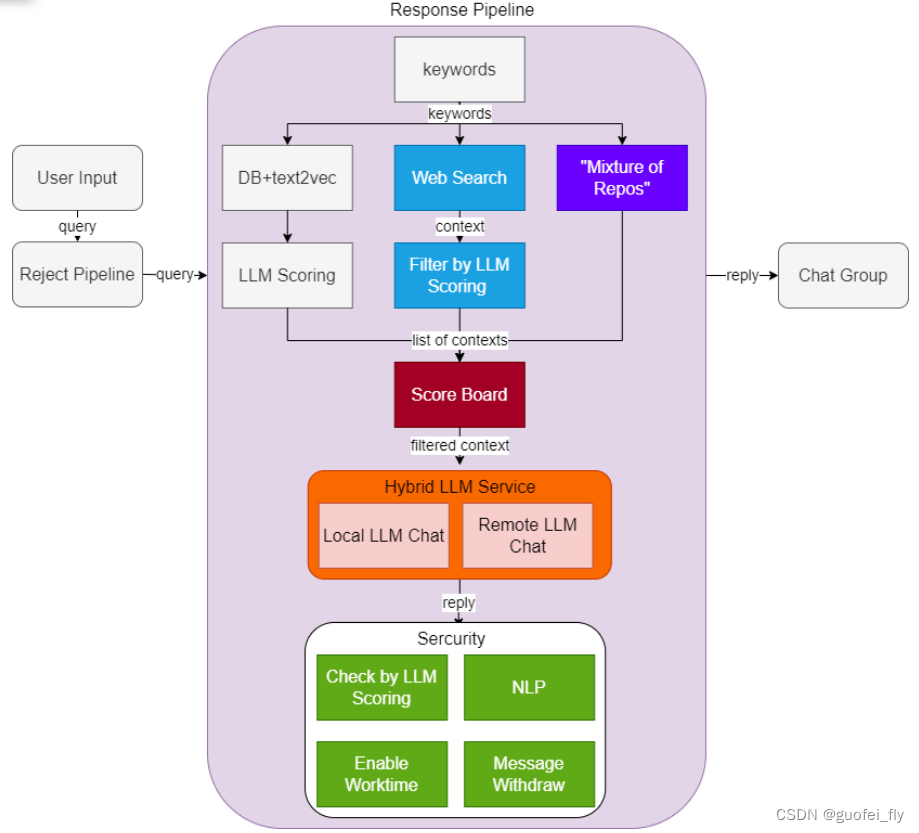
1.2 试验
1.2.1 LLM微调
基础模型的选择应满足如下三个标准:
1)理解领域术语,从而可以不用从头开始训练大模型;
2)具有长文本的拓展能力:支持RoPE编码;
3)支持in-context learning,并由稳定的评分能力
微调数据的来源有三处:
1)从聊天群里得到的对话数据,进行了脱敏处理和相关预处理;
2)对于只有Question的语料,利用更大的LLM进行蒸馏;
3)从Github爬取相关领域的问答对
1.2.2 训练和测试
基于XTuner框架,采用qLoRA策略,分别对应7B和13B的模型进行局部微调,微调后的模型表现出明显的幻觉,其主要问题还是语料的质量不高。
1.2.3 拒绝链路中的RAG
手动标注了几百条数据进行测试,发现text2vec-large-chinese的精准率和召回率分别可以达到0.99和0.92。同时,尝试langchain中不同的分词策略,发现影响不大。
1.2.4 LLM评分
LLM评分可用于query和背景知识的相关性评分,以及安全测试。
1.2.5 长文本支持
采用Triton和动态量化的技术,支持40k的上下文。
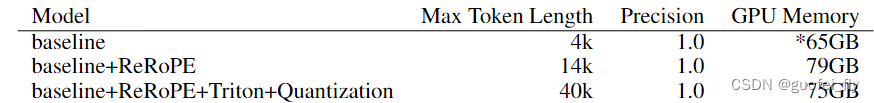
1.3 其他尝试
1.3.1 RAG中的NLP策略
采用词性分析等手段,对query进行改写。但实际工程上,由于专业领域部分词汇的特殊性,以及开源词性分析工具的多语种问题,导致在中文上并没有良好的准确度。
1.3.2 提示工程
考虑采用Rephrase and Respond 和REACT策略进行prompt的优化,但存在适用性和工程化的问题。
2. 服务器端部署demo
参照茴香豆部署服务器,进行服务器端的部署。
尝试询问问题:茴香豆怎么部署到微信群?,茴香豆的回答如下,可见整体还是精准的。
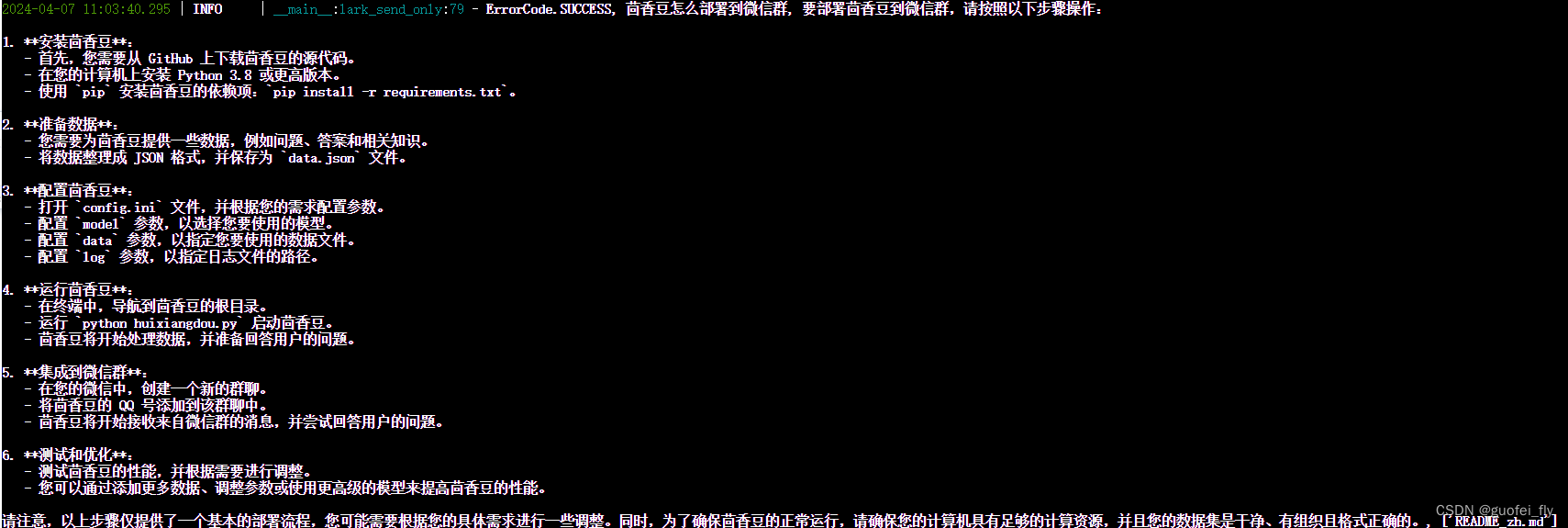
3. web端部署demo
3.1 直接利用官方平台进行部署
参照茴香豆部署群聊助手进行web端的部署。
直接在官方网站进行知识库的配置,尝试提问发现不理想:
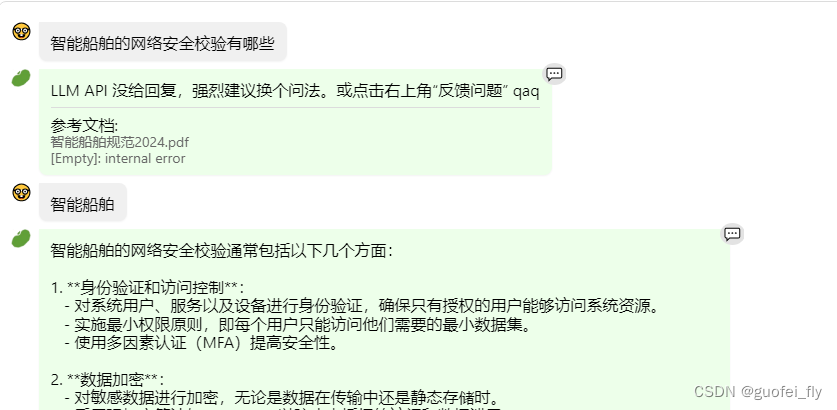
存在如下几个问题:
- 频繁出现
LLM API 没给回复,强烈建议换个问法。或点击右上角“反馈问题” qaq的问题,怀疑是线上计算资源问题不足, - 跳跃回答,如上图,下一个回答的是上一个问题,不知道是不是因为并发的问题?
- 回答质量,如上图,回答的与原文档差别较大,不知道是不是LLM+RAG普遍存在的问题。
3.2 服务器上进行web部署
基于gradio进行应用部署,测试结果如下:
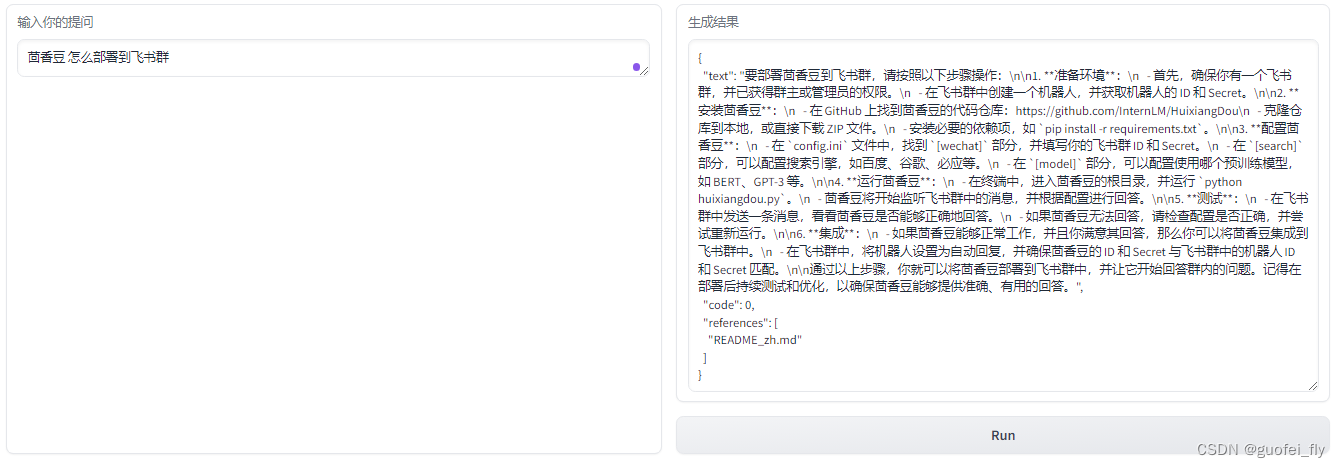
此外尝试了另一种前端部署方式,但最终提示缺少css和js文件,只能作罢。
4. 搭建垂直领域问答助手
创建一个基于transformers的问答知识库,同时开启远程模型(kimi)和网络搜索功能。
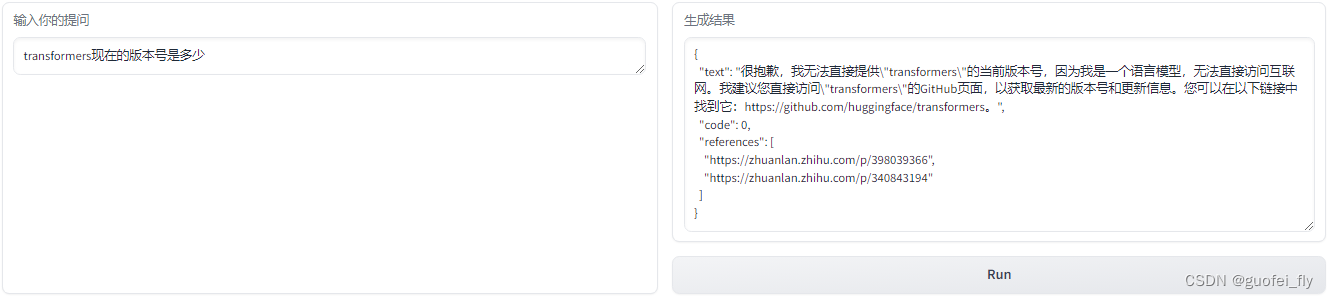
5. 源码学习&解析
5.1 文件结构和整体架构
5.1.1 文件结构
根目录的文件结构如下:
.
├── LICENSE
├── README.md
├── README_zh.md
├── android
├── app.py
├── config-2G.ini
├── config-advanced.ini
├── config-experience.ini
├── config.ini # 配置文件
├── docs # 教学文档
├── huixiangdou # 存放茴香豆主要代码,重点学习
├── huixiangdou-inside.md
├── logs
├── repodir # 默认存放个人数据库原始文件,用户建立
├── requirements-lark-group.txt
├── requirements.txt
├── resource
├── setup.py
├── tests # 单元测试
├── web # 存放茴香豆 Web 版代码
└── web.log
└── workdir # 默认存放茴香豆本地向量数据库,用户建立
核心代码huixiangdou的文件结构如下:
./huixiangdou
├── __init__.py
├── frontend # 存放茴香豆前端与用户端和通讯软件交互代码
│ ├── __init__.py
│ ├── lark.py
│ └── lark_group.py
├── main.py # 运行主贷
├── service # 存放茴香豆后端工作流代码
│ ├── __init__.py
│ ├── config.py #
│ ├── feature_store.py # 数据嵌入、特征提取代码
│ ├── file_operation.py
│ ├── helper.py
│ ├── llm_client.py
│ ├── llm_server_hybrid.py # 混合模型代码
│ ├── retriever.py # 检索模块代码
│ ├── sg_search.py # 增强搜索,图检索代码
│ ├── web_search.py # 网页搜索代码
│ └── worker.py # 主流程代码
└── version.py
5.1.2 整体框架

项目代码大致分为三个阶段:
1)构建向量检索
用于知识库的生成,以及query输入后的检索和召回,从而得到相关的背景语料信息。
2)回答生成
基于LLM(本地或远程api),利用prompt套用得到response。此阶段还可以接入web搜索,支持历史对话等功能。
3)前端应用
项目提供了基于gradio、html的部署方式,并可以接入wechat等第三方应用。
5.2 构建向量检索
1)文档加载
遍历目标repo,支持md、txt、pdf、excel、word、ppt和html文件的加载,其借助的开源工具分别为:
md、txt:直接加载,但对于md进行一定程度的清洗,如过滤图片和代码段
pdf:利用fitz+pandas,表格转为json
excel:利用pandas
word、ppt:利用textract
html:利用beautifulsoup
2)reponse向量索引
用于对query进行应答的相似度检索,其基于bce-embedding-base_v1进行Embedding,利用FAISS进行向量存储。
构建的语料是对上述的文档进行清洗+chunk。
3)reject向量索引
用于对query进行拒答的相似度检索,其同样基于bce-embedding-base_v1进行Embedding,利用FAISS进行向量存储。
构建的语料是基于未清洗的文档。对此,本人持怀疑态度,因为即使未清洗,也是与期待的query在字面上比较相近。相反,应该采用一些负样本进行索引。简单测了以下该向量索引对chit-chat类语料的相似情况,果然并不理想。

4)拒答相似度阈值动态更新
系统会加载good_questions.json和bad_questions.json 两份文件,分别作为正负样本来评测reject向量索引的pr值。根据绘制的pr曲线进行求和,得到最大和处的值作为拒答相似度阈值。神奇的是,在经过调整后,3)中错误的两个样本居然都被成功reject了。
5.3 回答生成
将上阶段召回的语料,结合一定的prompt模板,将query进行增强,然后通过调用本地模型或远程模型API进行回答。
6. 算法改进
本文提供一些改进思路,因目前缺少实践无法进行严格论证,仅供参考。
1)拒绝阶段的语料生成:可采用更泛化的负样本进行阈值选择,比如采用开源的chit-chat语料或其他语料;
2)第一阶段召回的trade-off:实测下面第一阶段的拒答率很高,可以用一些NLP技术(如关键词提取、词性分析)来加强召回;
7. TODO
鉴于时间,目前还没有对源码和逻辑进行透彻的理解,还需要对一些流程细节和trick进行进一步实践和学习。
8. 参考文献
- 书生·浦语 茴香豆 demo
- https://www.bilibili.com/video/BV1QA4m1F7t4/?spm_id_from=333.999.0.0

















 1464
1464

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









