






 随着深度学习的兴起,人工智能已广泛应用于多个领域并创造出显著的商业价值。本文介绍了一种融合机器学习与深度学习的方法,通过互补的技术路径解决单一技术无法克服的问题。以中国银联为例,展示了如何结合GBDT、GRU和RF技术来提高金融反欺诈模型的准确率。
随着深度学习的兴起,人工智能已广泛应用于多个领域并创造出显著的商业价值。本文介绍了一种融合机器学习与深度学习的方法,通过互补的技术路径解决单一技术无法克服的问题。以中国银联为例,展示了如何结合GBDT、GRU和RF技术来提高金融反欺诈模型的准确率。
在AlphaGo成功挑战围棋世界冠军后,“深度学习”家喻户晓,已成为人工智能(AI)的代名词。深度学习带动了人工智能的再次复兴,这次复兴的最大亮点,就是AI开始在语音识别、机器视觉、数据挖掘等多个领域落地,真正释放出了商业上的价值。各个行业的企业决策者也都有机会着眼自身战略,利用落地的AI技术和应用聚焦业务流程优化、效率提升以及对全新机遇的发掘。

图一、AI带来的应用和业务创新机会将推动全行业的转型升级
虽然AI正因其创造的商业潜力而备受睹目,但严格来说,它的发展仍然处于早期阶段,就像婴幼儿需要依次及综合使用口、手和眼等感官来感知这个世界,刺激大脑发育一样,AI用来感知信息、实现智能进化的路径,也是多种多样的。目前火爆的深度学习,以及一般的机器学习和基于规则的学习,都是目前AI领域的主流技术路径。
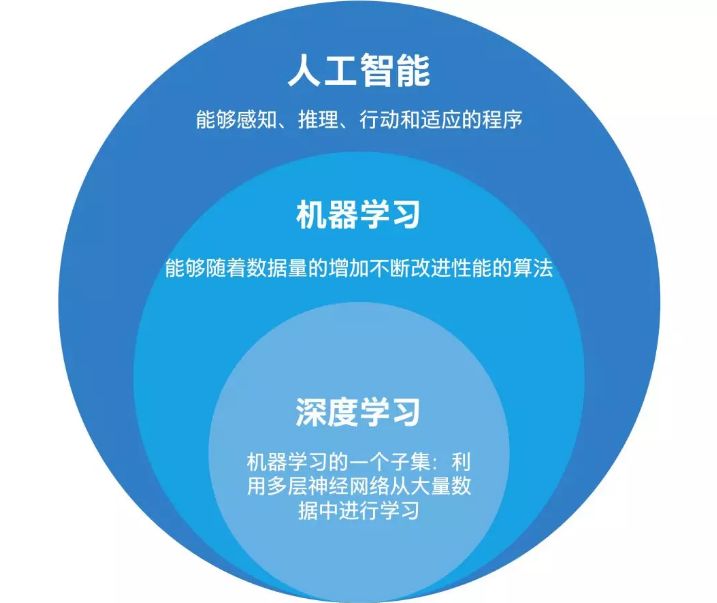
图二、人工智能、机器学习及深度学习的关系示意图
这些技术路径之间的关系,与其说是彼此竞争或替代,更不如说是互补的——基于它们不同特性和适用场景来实现互补。

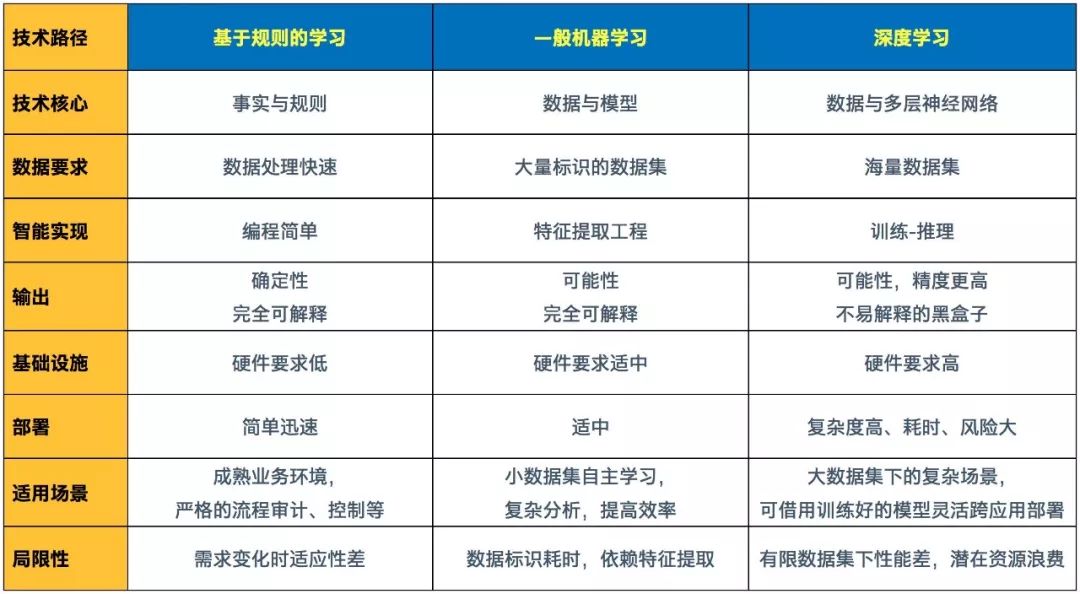
图三、现阶段主流AI技术路径的优势、适用场景和局限性总结
这种多条技术路径互补,或者说融合应用的妙处,在中国银联电子商务与电子支付国家工程实验室推进银行卡反欺诈技术的研究中体现得淋漓尽致。该实验室在最初研究中发现,如果只使用机器学习,将面临对序列化交易特征学习能力不足的问题,而只用深度学习,又会遇到单笔交易内特征学习能力有限的问题,而将两者融合才是更好的解决方案。为此它与众安科技及英特尔公司共同提出了GBDT→GRU→RF三明治结构欺诈侦测模型架构,该模型已经历了伪卡欺诈侦侧、骗保检测等多种银行、保险业务常见场景下基于真实数据的仿真验证,无论是在召回率还是准确率上,都明显优于传统的分类器方法或单一的RNN方法。
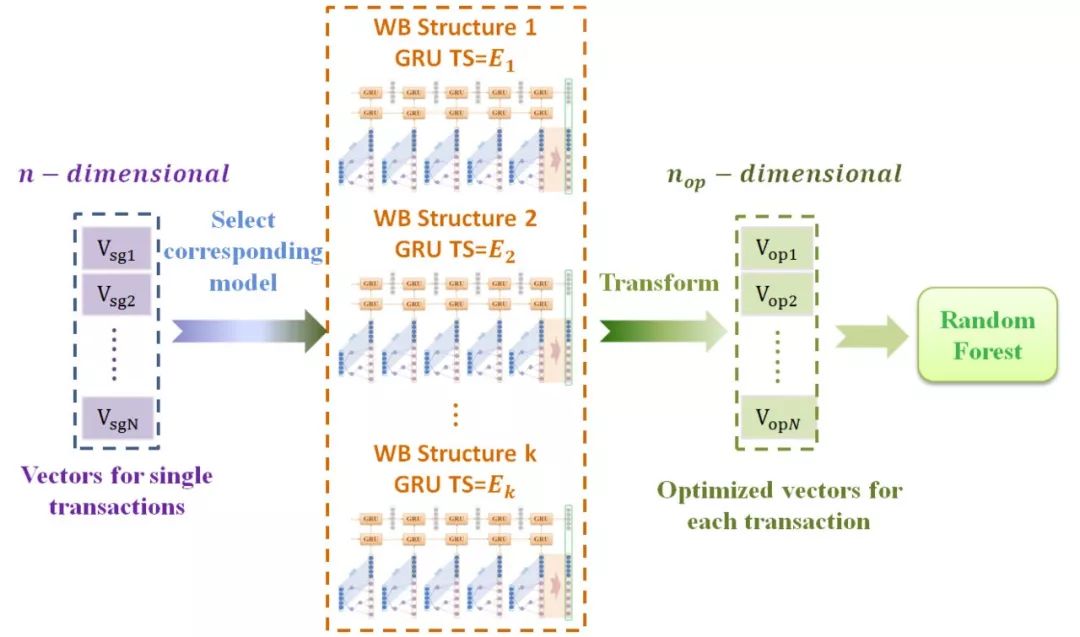
图四、融合了机器学习和深度学习的三明治结构欺诈侦测模型架构
值得一提的是,银联这个融合式的创新模型,是选择了基于英特尔至强处理器的CPU平台,而非专用平台来作为其算力的支柱。这是因为CPU架构对目前几乎所有的AI主流技术、乃至新涌现的技术都有出色的兼容性,而且在英特尔为至强平台提供了更为广泛和深入,涉及了硬件加速能力、软件工具及框架等层面的优化后,这个CPU平台不论是支持基于单种AI技术的应用,还是在运行融合了多种AI技术的应用时,性能表现都更为突出。在上述欺诈侦测模型的开发中,英特尔就提供了多种优化手段和工具的支持,帮助它实现了更高的工作效率。
可见,在AI之旅的起点上,企业面对的技术路径不只一条,选择也不限于一个。无论是传统推理、机器学习、深度学习,亦或是它们的融合,都是可选项。而从企业既有的IT基础设施,即从CPU架构,从英特尔至强平台起步,无疑是兼容多种技术路径,并兼顾性能和可扩展性的理想之选,它能帮助企业更好地应对复杂多变的现实应用需求,并以更快的速度、更低的成本构建起符合自身需求的AI应用。
点击阅读原文 ,查看完整《基于三明治结构深度学习框架的金融反欺诈模型研究与应用》。



















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









