



 本文深入探讨SRCNN算法,一种用于图像超分辨率的深度卷积网络。文章详细介绍了算法的三层卷积结构,包括图像块提取、非线性映射及重构过程,并解析了双三次插值预处理步骤。此外,还提供了模型参数、数据处理流程和评价指标等关键信息。
本文深入探讨SRCNN算法,一种用于图像超分辨率的深度卷积网络。文章详细介绍了算法的三层卷积结构,包括图像块提取、非线性映射及重构过程,并解析了双三次插值预处理步骤。此外,还提供了模型参数、数据处理流程和评价指标等关键信息。
SRCNN(Learning a Deep Convolutional Network for Image Super-Resolution)阅读笔记
1、论文网址:https://arxiv.org/abs/1501.00092
2、GitHub上tensorflow代码:https://github.com/tegg89/SRCNN-Tensorflow
3、论文介绍
3.1、数据预处理:
预处理,该过程使用双三次插值,先将原来的图片使用双三次插值进行下采样变小,在将变小后的图片按使用相同的倍数恢复为原来的大小作为低分辨率图片(LR)。
3.2、SRCNN网络
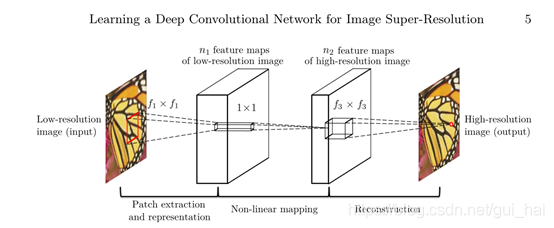
该网络包含有三个卷积层分别如下:
- patch extraction and representation(图像块的提取和表示)
传统的方法中先提取出来图像块,之后使用预训练的方式进行表示,作者认为该过程相当于使用一组卷积核与原来的图片进行卷积操作。
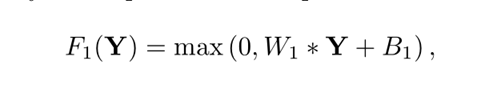
- Non-linear mapping(非线性映射)
对上一次卷积的输出再次进行卷积操作。
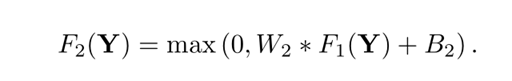
- Reconstruction(重构)
在传统的方法中高分辨率的图片总是要经过平均化处理才能生成最后的图片,这个平均化可以认为是一次卷积操作,在最后一层没有加入relu函数。
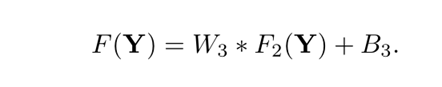
3.3、损失函数
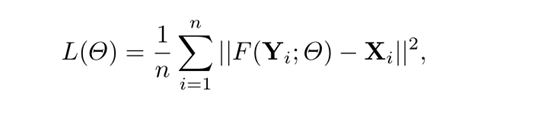
3.4、实验参数
W1 (卷积核)[9,9,1,64] b1(偏置)[64]
W2 (卷积核)[1,1,64,32] b2(偏置)[32]
W3 (卷积核)[5,5,32,1] b3(偏置)[1]
3.5、数据处理
将图片按照32✖32的大小,步长为14,进行切割成子图片;
只考虑了亮度这个影响因素(ycrcb);
在卷积的时候没有考虑padding因此开始输入32✖32的图片当卷积结束变为20✖20(32-8-4)。
3.6、评价指标
使用PSNR进行评价。
4、代码详解
未完待续。。。。。。


















 1338
1338

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









