




 本文深入探讨了Cache-主存层次中的关键概念,包括Cache存在的意义、地址存储映像的三种方式(全相联、直接映像、组相联映像)以及命中率和访存效率的计算。通过实例解析了解题步骤,强调了组相联映像的细节。此外,还介绍了存储体系、Cache地址编址、访存加速比及其计算方法,并讨论了LRU和FIFO替换算法。
本文深入探讨了Cache-主存层次中的关键概念,包括Cache存在的意义、地址存储映像的三种方式(全相联、直接映像、组相联映像)以及命中率和访存效率的计算。通过实例解析了解题步骤,强调了组相联映像的细节。此外,还介绍了存储体系、Cache地址编址、访存加速比及其计算方法,并讨论了LRU和FIFO替换算法。
cache-主存存储知识
基本的知识点,记录一下,加深印象。
如题:2021年10月

分析
对于组组相联映像还是有些模糊。另外就是cache一共是4块,分两组是什么意思?详见基本知识 - 组相联
解题步骤
做这样的题,一看是LRU,并且是Cache内的替换,所以不要被题的主存所干扰。
-
cache有4块,那么表格的行就有4行,加上访存地址+1还有命中率+1,所以画6行
-
分别填上表头名称及地址流,最后一行表头填命中率
列的话,根据访存地址流+1画就行了。
也就是cache两个为一组,一共两组。主存的地址流地址编号要对应到cache相应的分组号里。答案为:主存与cache内存映射,详见以下
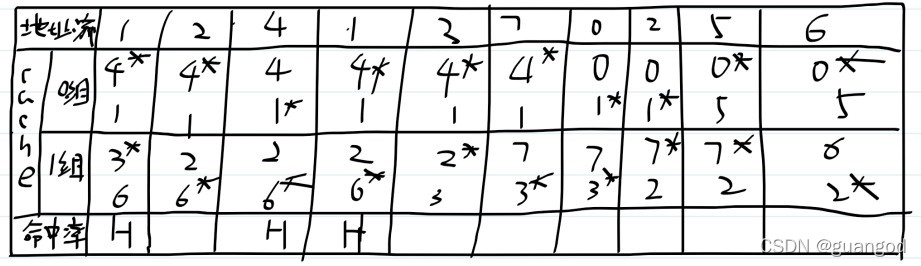
命中率=命中的次数/总的输入块数=3/10=30%.
基本知识
cache存在的意义??
主要是为了弥补主存速度的不足,cpu是可以直接访问的,所以速度要比虚拟存储器快。容量比较小只有几十个字节。
也是属于辅助存储器的一种。
从cpu角度来看,速度接近于cache,容量接近于主存。
什么是cache的地址存储映像
就是将每个主存块装入物理cache中的哪些块位置的规则。衡量规则好坏的标准是,看块冲突概率是否比较低(所谓的块冲突就是当查找的块,cadhe里没有时,就需要调入物理cache,这时就需要把原来cache块调出,这时就会产生冲突,选择哪块来调出),cache空间利用率是否比较高。
有三种地址映像。
全相联映像
让主存中任何一个块均可以映像装入到cache中任何一个块的位置。这就要求cache容量得大,可以理解成内存块都装入了cache中或来一个装一个,冲突率最低。通常不采用。
直接映像
指主存中的每一个块只能被放置到cache中惟一的一个指定位置。
由于位置确定所以冲突概率是最高的,物理cache空间利用率是最低的。
组相联映像
将主存空间按cache大小等分成区后,再将cache空间和主存空间中每一区都等分成大小相同的组。组内采取全相联映像,组间采取直接映像。
命中率 课本P113
cpu产生的逻辑地址能在M1中访问到的概率。
若逻辑地址流的信息能在M1中访问到的次数为R1,当时在M2中还未调入到M1的次数为R2,则命中率为H=R1/(R1+R2).
访存效率
如题:2020年10月

分析
主要是了解下公式。
解题
(1)该存储系统每MB的平均价格?
题目告诉了主存及cache每MB的价格,但问的是存储系统的平均价格,所以肯定不是直接相加的。
在《自学辅导》P73,给出的存储层次每位的价格公式,这里只要将位换成M即可。
题目中给出了主存及cache容量,S_m=100M,S_c=4M.
每M的价格为G_m=1,G_c=50
根据公式:每位存储价格为:
C
=
S
m
G
m
+
S
c
G
c
S
m
+
S
c
=
100
X
1
+
4
X
50
104
约等于
2.88
C=\frac{S_m G_m + S_c G_c}{S_m+S_c}=\frac{100X1 + 4X50}{104}约等于2.88
C=Sm+ScSmGm+ScGc=104100X1+4X50约等于2.88
(2)求cache命中率
根据前文命中率的描述,命中率等于,访问到的次数/总的访问次数,题目告诉了访问cache次数为1980,访问主存次数为20.题目没有告诉,访问cache到底有没有命中?访问主存到底有没有命中,但显然这样考虑这个题就没有答案了,所以按最简单思路来。
假定访问cache及主存次数就是都命中的次数。
所以命中率
H
=
H
c
H
c
+
H
m
=
1980
2000
=
99
%
H=\frac{H_c}{H_c+H_m}=\frac{1980}{2000}=99\%
H=Hc+HmHc=20001980=99%
(3)计算存储系统的平均访问时间
在《自学辅导》P73,也给出了存储体系等效的访问时间公式。命中概率的访问时间+失效概率的访问时间,由题目可知,cache的访问时间为10ns,主存的访问时间为200ns,
T
a
=
H
T
c
+
(
1
−
H
)
T
m
=
0.99
X
10
+
0.01
X
200
=
11.9
n
s
Ta=H T_c+(1-H) T_m=0.99X10+0.01X200=11.9ns
Ta=HTc+(1−H)Tm=0.99X10+0.01X200=11.9ns
(4)存储系统的访问效率?
还是在《自学辅导》P73。不过书中给的公式难以理解,估计也是有问题。还是采有答案比较好理解,就是存储效率等于命中概率下的时间除以系统平均访问时间: e = T c / T a = 10 / 11.9 = 84 % e=T_c/Ta=10/11.9=84\% e=Tc/Ta=10/11.9=84%
扩展知识
存储体系概念
指的是构成存储填信息统的n种不同的存储器(M1 ~ Mn)之间,配上辅助软硬件或辅助硬件,使之从cpu的角度来看,它们在逻辑上是一个整体。
多级存储层次:

典型的存储系统:

Cache的地址编址(必考点)

如本题:先看一下主存的地址,如何逻辑编址?
Cache每块映射的主存块数,那就编几个区号,所以主存有8块,有4个cache块所以 区号数 = 主存容量 c a c h e 容量 = 2 区号数=\frac{主存容量}{cache容量}=2 区号数=cache容量主存容量=2,编2个区,每个区对应4个主存块。
区内也和cache一样,分成2组,每组对应 每个区对应的主存块数 2 \frac{每个区对应的主存块数}{2} 2每个区对应的主存块数=2个主存块,组号编号为0组和1组。块号一样,再往下分成0号块和1号块。
Cache与主存的地址映像(必考点)
要解决的问题是Cache如何映射全部的主存?
Cache每块映射主存块数为=
主存总块数
C
a
c
h
e
的块数
\frac{主存总块数}{Cache的块数}
Cache的块数主存总块数;发现没,这个和区号是一样的。
上面已经编址完成后,如何映射全部的主存呢?
将cache的0组号对应全部主存的0组号,1组号对应1组号,用虚线连起来。
也就是头对头,尾对尾,组号对组号连起来。

这个图,作为画lRC替换过程图的依据。也就是地址流中编号对应的cache中的哪个组。
访存加速比
题目没的提及加速比,但之前有考过,所以不再重新总结了,在这里加一问。
如题,近几年真题是没考的

分析
(1)是典型的cache地址编址问题,但总归是要有个分析的先后,所以主要看分析的次序。
(2)是一个新的知识点,之前一直也没遇到过。
解题
(1)cache编址求法
cache地址编址只是比主存地址编址少了个区号,其他都是完全一样的。
很明显,根据题意:
区号数
=
主存容量
c
a
c
h
e
容量
=
1024
K
/
32
k
=
32
,
区号
=
l
o
g
2
32
=
5
区号数=\frac{主存容量}{cache容量}=1024K/32k=32,区号=log_2 32=5
区号数=cache容量主存容量=1024K/32k=32,区号=log232=5,也就是说区号占5位。
缓存分了8组,
组号
=
l
o
g
2
8
=
3
组号=log_28=3
组号=log28=3,也就是说组号占了3位。
主存与缓存块大小为64,所以块内地址用多少位才能表示64呢?
块内地址
=
l
o
g
2
64
=
6
块内地址=log_264=6
块内地址=log264=6,虽然有点绕,但仔细想想这三个部分都不难理解。
唯一剩下的组内块号,这个如何确定呢?cache分为了8组,一共是32K,所以一组就是4k,也就是4 X 1024=4096,一个块大小为64,所以一组内共有4096/64=64个块,所以
组内块号
=
l
o
g
2
64
=
6
组内块号=log_264=6
组内块号=log264=6,占6位。
按照cache地址编址画出图,并标出字段名与位数,即可完成第一问,难点在于组号,组内块号,这些都抽象出来的,需要有一定的想像能力。
(2)访存加速比
加速比,这个概念是在系统结构考点之时空图及分析中提及的,指的是不用流水线的时间除以流水线时间。
在《自学辅导》P73,没有给出加速比的概念,但可以类比下,就是不使用cache访存时间,除以系统平均访问时间。所以
s
=
T
m
/
T
a
=
T
m
/
(
0.95
X
20
+
(
1
−
0.95
)
X
T
m
)
=
10
s=T_m/Ta=T_m/(0.95X20 + (1-0.95)XT_m)=10
s=Tm/Ta=Tm/(0.95X20+(1−0.95)XTm)=10,解这个方程,求得T_m=380ns
关于LRU替换算法
实际上就是看,从当前列开始,往看前,看当前页里面哪个页离着当前列距离最远,就是要被替换的数。
FIFO替换算法
如题2019年4月

分析
一个题型,不再单列,无论是主存的替换算法还是cache的替换算法都是一样的,在系统结构考点之堆栈型替换算法中已经对原理做了大概的记录,不再赘述了也不再单列文章了;直接进入正题,这个题与上面直接给出页地址流的情形是不太一样的,这个题是需要算出页地址流的。
解题步骤
-
先看主存有几页,根据页面大小为200字,主存容量为400.所以,主存有 400 / 200 = 2 页 400/200=2页 400/200=2页.
-
将虚存的地址流转成实页号。
一页为200字,所以16/200 取整对应的就是0页。
| 虚地址流 | 16 | 219 | 136 | 156 | 332 | 480 | 503 | 868 | 916 | 999 |
|---|---|---|---|---|---|---|---|---|---|---|
| 实页 | 0 | 1 | 0 | 0 | 1 | 2 | 2 | 4 | 4 | 4 |
3.剩下的就是FIFO算法,只要是先进去的就先出来,不论中间是否又进入。
| 虚页地址流 | 16 | 219 | 136 | 156 | 332 | 480 | 503 | 868 | 916 | 999 |
|---|---|---|---|---|---|---|---|---|---|---|
| 实页 | 0 | 1 | 0 | 0 | 1 | 2 | 2 | 4 | 4 | 4 |
| 0页 | 0 | 0 | 0 | 0 | 0 | 2 | 2 | 2 | 2 | 2 |
| 1页 | 1 | 1 | 1 | 1 | 1 | 1 | 4 | 4 | 4 | 4 |
| 命中 | H | H | H | H | H | H |
命中率为:6/10=60%
堆栈模拟替换算法
如题:2017年10月

分析
难就难在,不知道如下手,题目告诉是B的命中率,而画的和求的是A的处理过程及命中率。如何思考呢?这其实是一个干扰项,告诉了地址流,又告诉了是堆栈模拟A中的替换算法,那就可以画出替换的表及命中率,完全不用管B的命中率。
由系统结构考点之堆栈型替换算法可知LRU是属于堆栈型替换算法的,所以是可以用堆栈来模拟的。并且堆栈型替换算法特点为是命中率随页数增加而提高。
解题步骤
直接画表格就可以。堆栈与FIFO是不一样的,堆栈入栈时,如果原先的堆栈里面有要入栈的数,那么**要入栈的数是要放到栈顶位置的。**题目告诉了B分配4与5,那么A就是分配5与4个空间两种情形。
| 地址流 | 2 | 3 | 2 | 1 | 5 | 2 | 4 | 5 | 3 | 2 | 5 | 2 | 1 | 4 | 5 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| A空间 | 2 | 3 | 2 | 1 | 5 | 2 | 4 | 5 | 3 | 2 | 5 | 2 | 1 | 4 | 5 |
| 2 | 3 | 2 | 1 | 5 | 2 | 4 | 5 | 3 | 2 | 5 | 2 | 1 | 4 | ||
| 3 | 2 | 1 | 5 | 2 | 4 | 5 | 3 | 3 | 5 | 2 | 1 | ||||
| 3 | 3 | 1 | 1 | 2 | 4 | 4 | 4 | 3 | 5 | 2 | |||||
| 3 | 3 | 1 | 1 | 1 | 1 | 4 | 3 | 3 | |||||||
| 命中n=4 | H | H | H | H | H | H | H | ||||||||
| 命中n=5 | H | H | H | H | H | H | H | H | H | H |
(2)当a分配4页时,命中率为7/15
当a分配5页时,命中率为10/15


















 1153
1153

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











