




原文链接:An Efficient Matrix Transpose in CUDA C/C++
上一篇CUDA C++文章介绍了使用共享内存的机制,包括静态和动态分配。在这篇文章中,我将展示一些使用共享内存带来的性能提升。具体来说,我将优化矩阵转置,以展示如何使用共享内存将跨步全局内存访问(strided global memory accesses)重新组织为合并访问(coalesced accesses)。
矩阵转置
我们希望优化的代码是异位(out-of-place,区别于in-place)的单精度矩阵的转置,即输入和输出是内存中的两个独立数组。为了简单起见,我们只考虑维数为32的整数倍的方阵。整个代码可在Github获得。它由几个内核和主机代码组成,用于执行典型任务,如主机和设备之间的内存分配和数据传输、几个内核的启动和计时以及结果的验证,以及主机和设备内存的释放。在这篇文章中,我将只包括内核代码;您可以在Github上查看其余部分。
除了执行几个不同的矩阵转置外,我们还运行简单的矩阵复制内核,因为复制的性能揭示了矩阵转置可以达到的性能。对于矩阵复制和转置,与衡量性能有关的指标是有效带宽,以GB/s为单位计算,方法是将矩阵的大小(以GB为单位)的两倍(一次用于加载矩阵,一次用于存储)除以执行时间(以秒为单位)。
本研究中的所有内核都启动了大小为32×8个线程的块(代码中TILE_DIM=32,BLOCK_ROWS=8),每个线程块转置(或复制)一个大小为32×32的矩阵数据片(tile)。使用线程比数据片中的元素少的线程块对于矩阵转置是有利的,因为每个线程转置四个矩阵元素,所以索引计算成本的大部分都分摊到了这些元素上。
本例中的内核使用笛卡尔(x,y)映射而不是行/列映射将线程映射到矩阵元素,以简化CUDA C中自动变量的含义:threadIdx.x是水平的,threadIdx.y是垂直的。这个映射由程序员决定;需要记住的重要一点是,为了确保内存合并,我们希望将变化最快的部分映射到内存的连续元素中。在Fortran中,连续地址对应于多维数组的第一个索引,threadIdx.x和blockIdx.x分别在块(blocks)和网格(grids)中变化最快。
这里译者将矩阵初始化的代码插入文章中,以方便理解:
// 1024*1024的矩阵按行存储在一维数组中
// 矩阵元素从0开始累加,直至1024*1024-1
for(int j=0; j<ny; j++){
for(int i=0; i<nx; i++){
h_idata[j*nx + i] = j*nx + i; // 矩阵数据为[0, 1, 2, ..., 1023*1024+1023]
}
}
简单矩阵复制
让我们从矩阵复制内核开始。
__global__ void copy(float *odata, const float *idata)
{
// blockIdx.x: x方向,数据片的序号
// threadIdx.x: x方向数据片内,数据列的序号
int x = blockIdx.x * TILE_DIM + threadIdx.x; // 当前线程要拷贝的数据在矩阵中的列索引
// blockIdx.y: y方向,数据片的序号
// threadIdx.y: y方向,block中8个线程的序号
int y = blockIdx.y * TILE_DIM + threadIdx.y; // 当前线程要拷贝的数据在矩阵中的行索引
int width = gridDim.x * TILE_DIM; // 32*32=1024
// j=0, 8, 16, 24
// 4次循环,block中的32*8个线程分别拷贝当前32*32数据片的第0-7, 8-15, 16-23, 24-31行
// 这样,一个warp中的连续的32个线程在每次for循环中都拷贝内存中连续的32个float数据
for (int j = 0; j < TILE_DIM; j+= BLOCK_ROWS)
odata[(y+j)*width + x] = idata[(y+j)*width + x];
}
在该例程结束时,每个线程在循环中复制矩阵的四个元素,因为块中的线程数量是数据片中的元素数量的四分之一(TILE_DIM/BLOCK_ROWS)。还要注意的是,在计算矩阵索引y时必须使用TILE_DIM,而不是BLOCK_ROWS或blockDim.y。循环在第二个维度上迭代,而不是在第一个维度,这样连续的线程就可以加载和存储连续的数据,并且所有对idata的读取操作和对odata的写入操作都会合并。
简单矩阵转置
我们的第一个转置内核看起来与复制内核非常相似。唯一的区别是odata的索引被交换了。
__global__ void transposeNaive(float *odata, const float *idata)
{
int x = blockIdx.x * TILE_DIM + threadIdx.x;
int y = blockIdx.y * TILE_DIM + threadIdx.y;
int width = gridDim.x * TILE_DIM;
// 一个warp内,idata的连续32个float数据被合并读取,
// 但写入odata时数据不连续,相邻线程写入的数据相隔一行(1024个float)的位置,数据写入操作无法合并
for (int j = 0; j < TILE_DIM; j+= BLOCK_ROWS)
odata[x*width + (y+j)] = idata[(y+j)*width + x];
}
在transposeNaive中,对idata的读取操作与复制内核中一样被合并,但对于我们的1024×1024测试矩阵,对odata的写入操作来说,连续线程之间具有1024个元素(或4096个字节)的步长。这个情况符合前面一篇文章(全局内存合并)中的跨步内存访问图中的渐近线,我们预计该内核的性能将受到相应的影响。copy内核和transposeNaive内核的结果证明了这一点。
| 有效带宽(GB/s,启用ECC) | Tesla M2050 | Tesla K20c |
|---|---|---|
| copy | 105.2 | 136.0 |
| transposeNaive | 18.8 | 55.3 |
transposeNaive内核只实现了copy内核有效带宽的一小部分。因为copy内核除了复制之外几乎不做什么,所以我们希望能更接近copy的性能。让我们看看如何做到这一点。
通过共享内存实现合并转置
针对较差的转置性能的补救措施是使用共享内存来避免在全局内存中的巨大步长。下图描述了矩阵转置中共享内存是如何使用的。
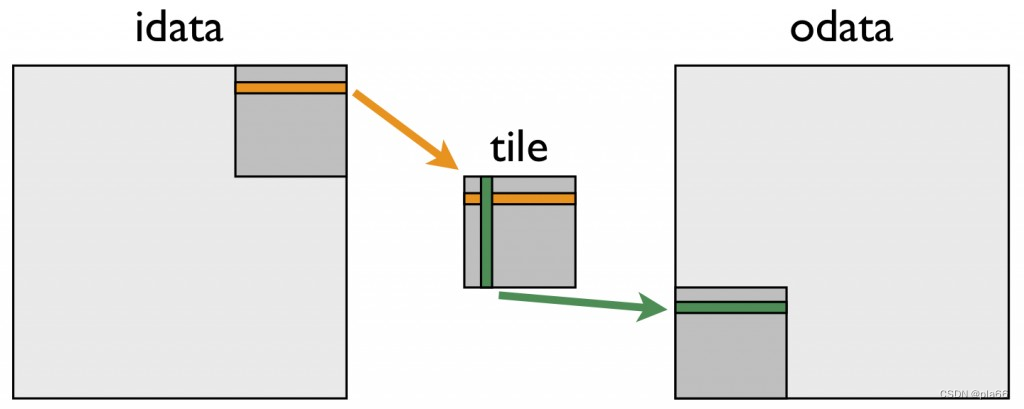
下面的内核实现了这种转置。
__global__ void transposeCoalesced(float *odata, const float *idata)
{
__shared__ float tile[TILE_DIM][TILE_DIM];
int x = blockIdx.x * TILE_DIM + threadIdx.x;
int y = blockIdx.y * TILE_DIM + threadIdx.y;
int width = gridDim.x * TILE_DIM;
// 将32*32数据片整体存入共享内存
// 存入时,一个warp的线程将数据存入共享内存的一行
for (int j = 0; j < TILE_DIM; j += BLOCK_ROWS)
tile[threadIdx.y+j][threadIdx.x] = idata[(y+j)*width + x];
__syncthreads();
// 按行存入odata
// x表示一行中32个数据的横坐标
x = blockIdx.y * TILE_DIM + threadIdx.x; // transpose block offset
// y表示该行数据的列坐标
y = blockIdx.x * TILE_DIM + threadIdx.y;
// 因为需要将对odata的写入操作进行合并,因此数据存入odata的方式是按行存
// 存入odata的一行数据,对应到共享内存中是一列数据,因此从共享内存中读取数据时,一个warp的线程读取一列
for (int j = 0; j < TILE_DIM; j += BLOCK_ROWS)
odata[(y+j)*width + x] = tile[threadIdx.x][threadIdx.y + j];
}
在第一个循环中,一个warp的线程将连续数据从idata中读取到共享内存数据片的一行中。在重新计算数组索引之后,共享内存数据片中的一列被写入odata中的连续地址。因为线程向odata写入的数据与从idata读取的数据不同,所以我们必须使用块内同步语句__syncthreads()。这种方法很好地加速了转置,如更新后的有效带宽表所示。
| 有效带宽(GB/s,启用ECC) | Tesla M2050 | Tesla K20c |
|---|---|---|
| copy | 105.2 | 136.0 |
| transposeNaive | 18.8 | 55.3 |
| transposeCoalesced | 51.3 | 97.6 |
transposeCoalesced的结果相比transposeNaive有所改进,但它们仍然远未达到copy内核的性能。我们猜测,性能差距的原因可能是与使用共享内存相关的开销和必需的__syncthreads()同步。我们可以通过以下使用共享内存的copySharedMem内核地测试这一点。
__global__ void copySharedMem(float *odata, const float *idata)
{
__shared__ float tile[TILE_DIM * TILE_DIM];
int x = blockIdx.x * TILE_DIM + threadIdx.x;
int y = blockIdx.y * TILE_DIM + threadIdx.y;
int width = gridDim.x * TILE_DIM;
for (int j = 0; j < TILE_DIM; j += BLOCK_ROWS)
tile[(threadIdx.y+j)*TILE_DIM + threadIdx.x] = idata[(y+j)*width + x];
__syncthreads();
for (int j = 0; j < TILE_DIM; j += BLOCK_ROWS)
odata[(y+j)*width + x] = tile[(threadIdx.y+j)*TILE_DIM + threadIdx.x];
}
请注意,在这里,技术上不需要调用__syncthreads(),因为一个元素的操作是由同一个线程执行的,但我们在这里包含它是为了模拟转置行为。下表的第二行显示问题不在于共享内存的使用或同步。
| 有效带宽(GB/s,启用ECC) | Tesla M2050 | Tesla K20c |
|---|---|---|
| copy | 105.2 | 136.0 |
| copySharedMem | 104.6 | 152.3 |
| transposeNaive | 18.8 | 55.3 |
| transposeCoalesced | 51.3 | 97.6 |
共享内存bank冲突
对于32×32个元素的共享内存数据片,一列数据中的所有元素都映射到同一共享内存bank,从而导致内存bank冲突中的最坏情况:读取一列数据会导致32路bank冲突。幸运的是,解决方法是只需在共享内存数据片的声明中填充(pad)宽度,使数据片宽33个元素,而不是32个。
__shared__ float tile[TILE_DIM][TILE_DIM+1];
以这种方式消除bank冲突使我们的有效带宽达到copy的95%左右。
| 有效带宽(GB/s,启用ECC) | Tesla M2050 | Tesla K20c |
|---|---|---|
| copy | 105.2 | 136.0 |
| copySharedMem | 104.6 | 152.3 |
| transposeNaive | 18.8 | 55.3 |
| transposeCoalesced | 51.3 | 97.6 |
| transposeNoBankConflicts | 99.5 | 144.3 |
总结
在这篇文章中,我们介绍了三个内核,它们代表了矩阵转置的各种优化方法。几个内核展示了如何使用共享内存来合并全局内存访问,以及如何填充数组以避免共享内存bank冲突。从内核的相对收益来看,合并全局内存访问是获得良好性能的最关键因素,这在许多应用程序中都是如此。因为全局内存合并非常重要,所以我们在下一篇文章——在3D网格上进行有限差分计算中再次讨论它。


















 2660
2660




 到【灌水乐园】发言
到【灌水乐园】发言







