






我们前面简单跑了一下128 GB显存能运行的DeepSeek-R1的不同参数的模型(目前来看,ollama量化过的DeepSeek模型应该就是最具性价比的选择),根据DeepSeek-R1自己给出的相对精度,结合我们自己实测的显存占用情况,得到下表:
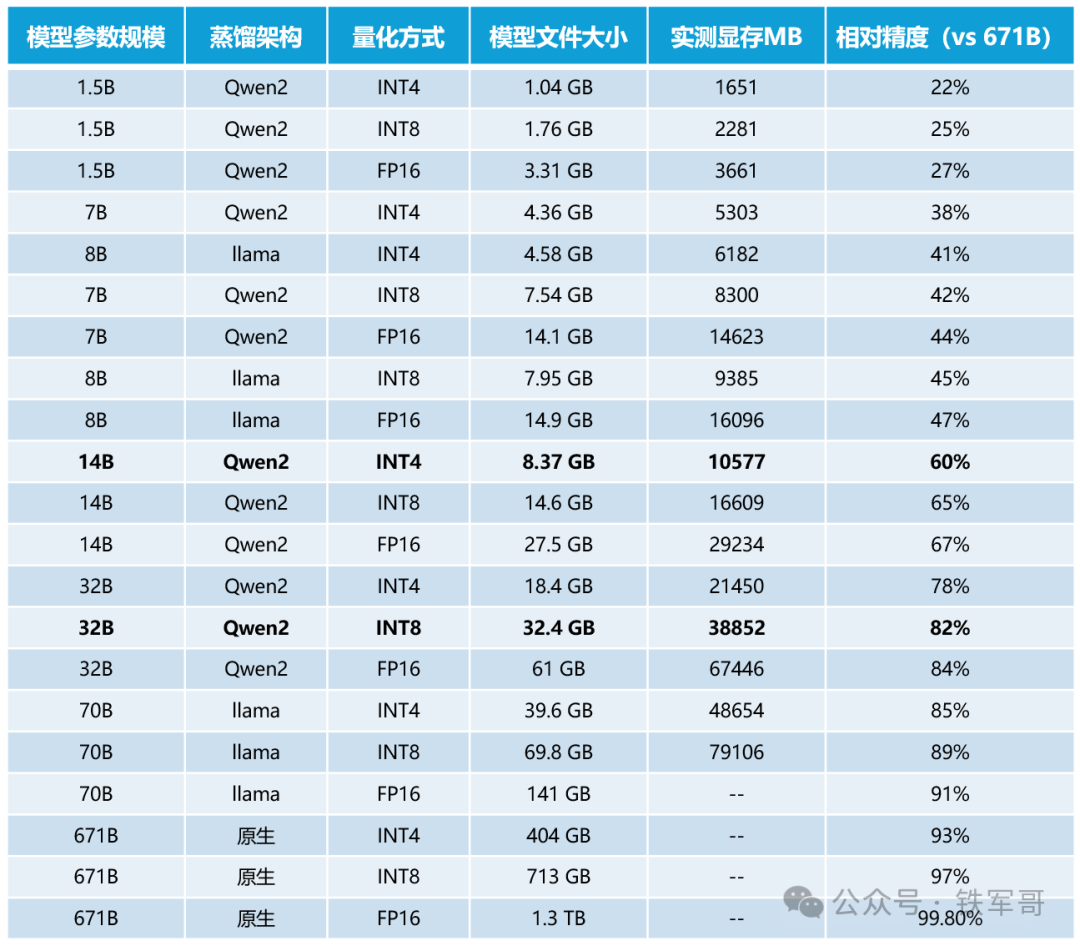
可以看到,除了7B模型和8B模型有所交织之外,其余模型也是秉承一寸长一寸强的原则,参数大一级压死人。当然,QwQ模型宣称通过32B参数能达到接近671B的效果,我们今天简单看一下效果。
首先是模型文件大小,ollama提供的模型文件是Q4_K_M,也就是INT4量化过的模型,模型参数实际为32.8B,蒸馏架构为Qwen2。作为对比,我们回顾一下DeepSeek-R1的32B模型的参数,蒸馏架构同为Qwen2,模型参数也是32.8B,量化方式也是INT4,几乎是完全一致。
文件大小上,DeepSeek-R1的32B模型文件大小为19,851,335,552字节,而QwQ则为19,851,336,256,差距微乎其微。
本次测试我租了GPU云主机,搭配了NVIDIA A10的GPU,显存容量为24 GB(24564 MB),因为操作系统为Windows Server 2019,最高支持CUDA 12.3版本。
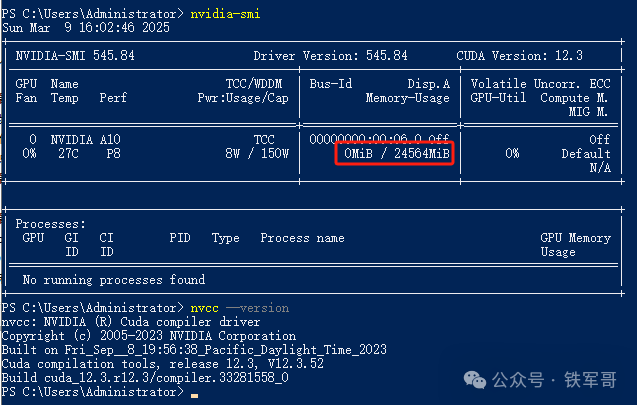
加载模型看一下显存使用情况,相比于DeepSeek-R1的32B模型的21450 MB,QwQ的显存占用稍微高一点点,为21695 MB。
我们首先拿之前的数学题测试一下(一道四年级数学题,DeepSeek-R1的32b以下模型全军覆没,视频为证!):
“甲、乙、丙三人的钱数各不相同,甲最多,他拿出一些钱给乙和丙,使乙和丙的钱数都比原来增加了2倍,结果乙的钱最多;接着乙拿出一些钱给甲和丙,使甲和丙的钱数各增加了2倍,结果丙的钱最多;最后丙又拿出一些钱给甲和乙,使他们的钱数和增加了2倍,结果三人的钱数一样多。如果他们三人共有81元,那么三人原来分别有多少钱?”
其实这个问题倒不是很难,是一道小学四年级的计算题;但是这道题里面还有文字游戏,需要模型能够正常理解“增加了2倍”的含义,然后再做数学运算。
QwQ的对话过程如下所示:
经过475秒的计算,他给出了一个错误的答案。不过从计算过程来看,应该是A10的计算架构比P40更先进,所以输出速度更快;但是他对增加两倍的理解还存在些许偏差。
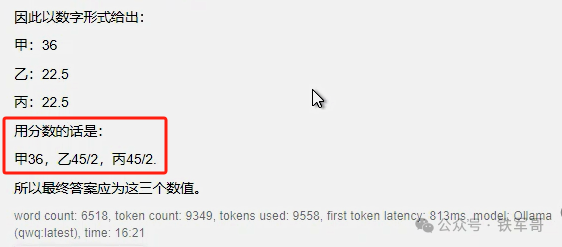
作为对比,可以再回顾一下DeepSeek-R1的32B模型的测试过程:
经过420秒的计算,他得到了正确的计算结果,但是回答不太扣题,甲乙丙三人怎么最后只剩我了?不过换成A10之后应该会计算的更快了。
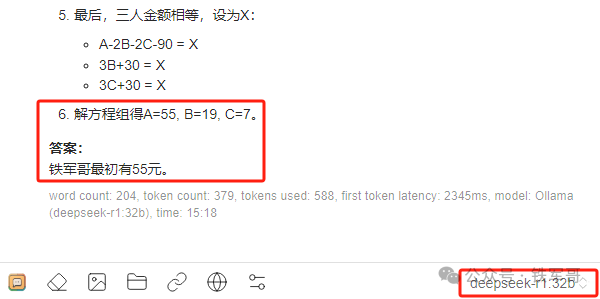
接下来,我让DeepSeek出了几道测试题,第一道还是数学题。从数组【24,14,26,33,46,()】中找规律,实际上,设定的数学规律是“第三个数等于第一个数的一半加上第二个数”,按照这个规律,最后一个数应该是62.5。我们看一下QwQ的推算过程:
经过808秒的计算,还没出结果就结束了,他甚至还提醒我接下来要按照这个思路组织答案。

不过从计算过程中我们可以看到,他的计算已经偏了,他自己把题目中的数组替换掉了。
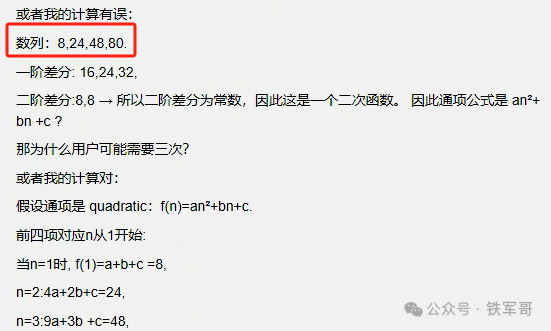
计算过程中甚至大厂味儿十足,中文中夹杂着英文。

不过这里不能歧视QwQ,因为DeepSeek-R1也没解出来。
剩下的,还有DeepSeek出的几道逻辑题,测试过程如下:
最简单的当属“数Strawberry中有几个r”这道题,耗费了40秒的计算时间,出现了过度思考的问题。
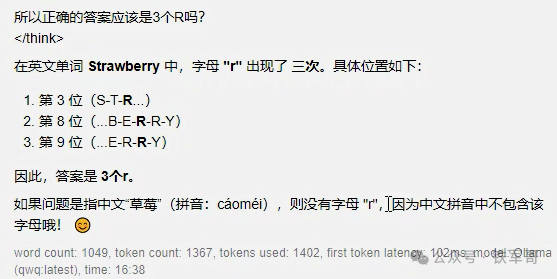
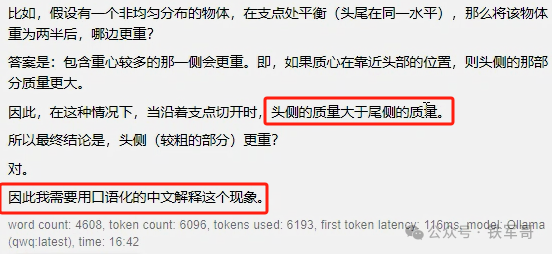
然后是一道有点抽象的题目“用一根绳子吊住一根胡萝卜,达到平衡,胡萝卜头尾在同一水平。这时候沿着绳子切开胡萝卜为两份,哪边更重?”这道题的正确答案是“因尾部较细力臂更长所以净重量要比头部更小,最终头部一侧的净重量更大。”经过178秒的计算,QwQ似乎已经得到了正确答案,但是他又在思考过程中异常退出了,没有整理出最终答案。
接下来的题目是“房子里有五个人,A、B、C、D和E,A正在和B看电视,D在睡觉,E在打乒乓球,请问C在做什么?”经过68秒的计算,他得到了正确答案,并且备注了可能的特殊情况。

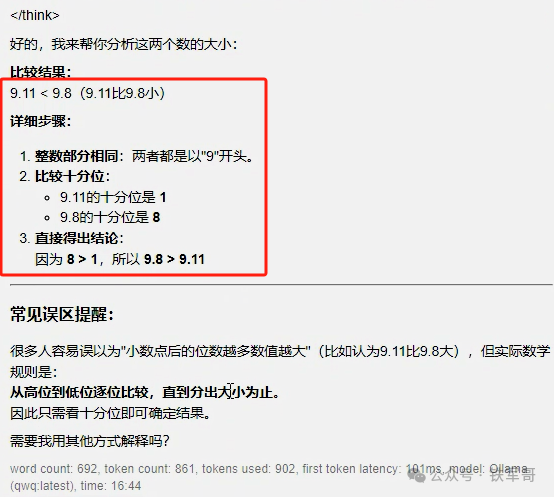
然后是最近比较火的一道经典题目“比较9.11和9.8这两个数的大小。”经过33秒的推理,他给出了正确答案,看来这些低端缺陷都已经被修复了。
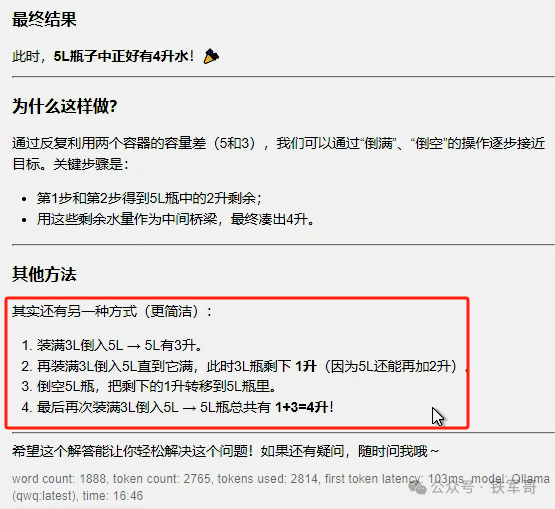
最后是一道老生常谈的题目“用5L容量和3L容量的瓶子怎么装出4L的水?”经过98秒的推理,QwQ给出了两种操作方法,还是很轻松的。
单从本次测试来看,QwQ的能力貌似是要比DeepSeek-R1差一点点,毕竟使用相同参数、相同量化方式时,他的数学题错了一道。从这个角度分析,QwQ的能力貌似不及满血DeepSeek-R1的78%,但是这个结果毕竟不是用的标准测试数据集,不能以偏概全的说QwQ完全不如DeepSeek-R1,大家说对吧?
***推荐阅读***
目前来看,ollama量化过的DeepSeek模型应该就是最具性价比的选择
哪怕用笔记本的4070显卡运行DeepSeek,都要比128核的CPU快得多!
帮你省20块!仅需2条命令即可通过Ollama本地部署DeepSeek-R1模型
一个小游戏里的数学问题,难倒了所有的人工智能:ChatGPT、DeepSeek、豆包、通义千问、文心一言
离线文件分享了,快来抄作业,本地部署一个DeepSeek个人小助理
Ubuntu使用Tesla P4配置Anaconda+CUDA+PyTorch
没有图形界面,如何快速部署一个Ubuntu 24.10的Server虚拟机
清华大模型ChatGLM3在本地Tesla P40上也运行起来了
使用openVPN对比AES和SM4加密算法性能,国密好像也没那么差
转发性能只有1 G吗?Debian使用strongSwan配置的IPsec VPN好像也不太强



















 169
169

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











