



本文来自九天老师的视频,由赋范空间运营进行整理编辑,如果你有任何建议欢迎评论告知哦~
仅需1/10的硬件成本,性能就能比肩DeepSeek R1满血模型,阿里千问QWQ-32B推理模型正式开源!
本期将为大家详细介绍QWQ模型的实测性能表现、硬件需求以及与R1模型的优劣势对比。
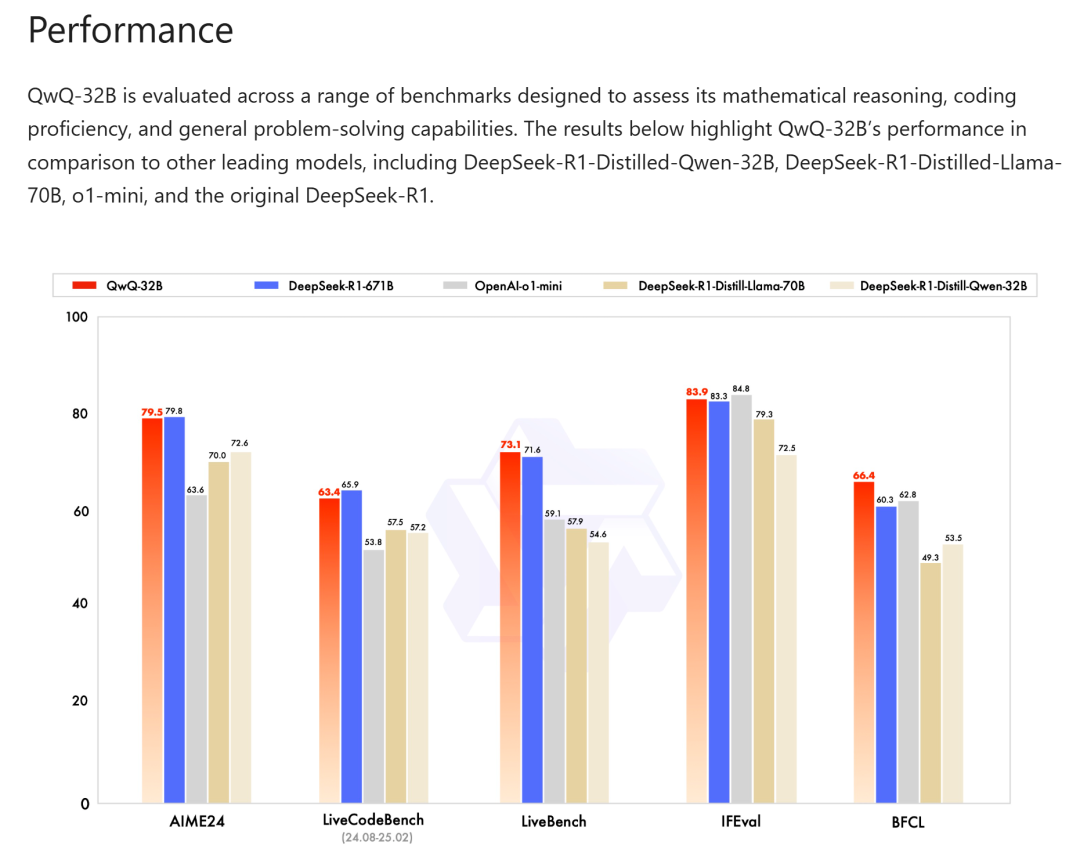
QWQ系列模型,是阿里千问模型中的推理类大模型,早在去年12月就发布了QWQ-32B-Preview预览模型,也是当时业内最早开源的推理大模型。
而现在,时隔3个月,QWQ模型再度回归,和此前Preview模型不同,现在的QWQ-32B正式版模型能力暴涨,在数学、编程等推理领域的能力甚至和671B的DeepSeek R1模型相当,
并且QWQ也具备了目前通用的&响应模式,一举甚至成为DeepSeek R1模型的最佳平替!
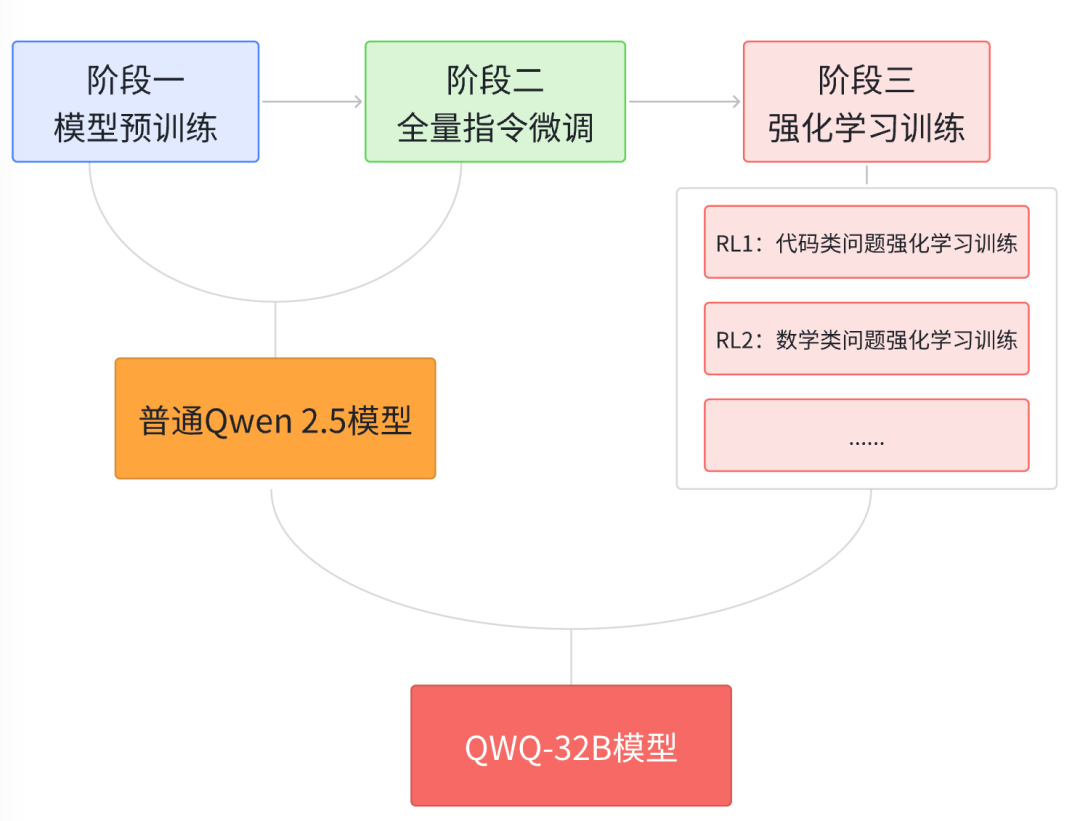
QWQ性能暴涨的原因,就在于它采用了DeepSeek R1完全相同的训练流程,也就是采用了预训练—全量指令微调—强化学习后训练的三训练流程。
并在强化学习的后训练阶段,原创性的提出了多段强化学习训练法,并在每个RL训练阶段,单独专注于提升模型的某一个方面的能力,如第一个阶段训练模型代码能力、第二个阶段训练模型编程能力等。
这个训练过程如图所示:
而最终模型效果也非常惊艳,除了各项评分指标和DeepSeek R1模型接近外,模型问答的语气风格也和R1模型相差无几。
这里进行一组简单的对比,例如输入“你好,好久不见,请介绍下你自己”,以下是DeepSeek R1模型的思考和回答内容:
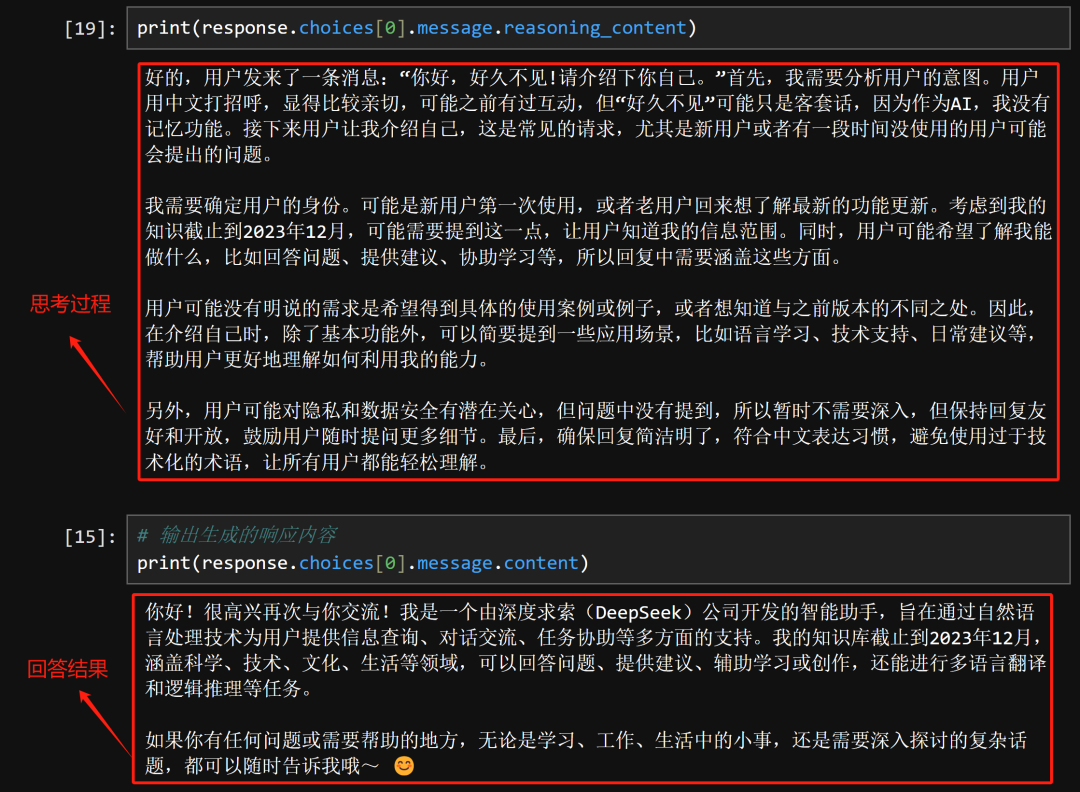
而以下是则QWQ模型的回答内容:
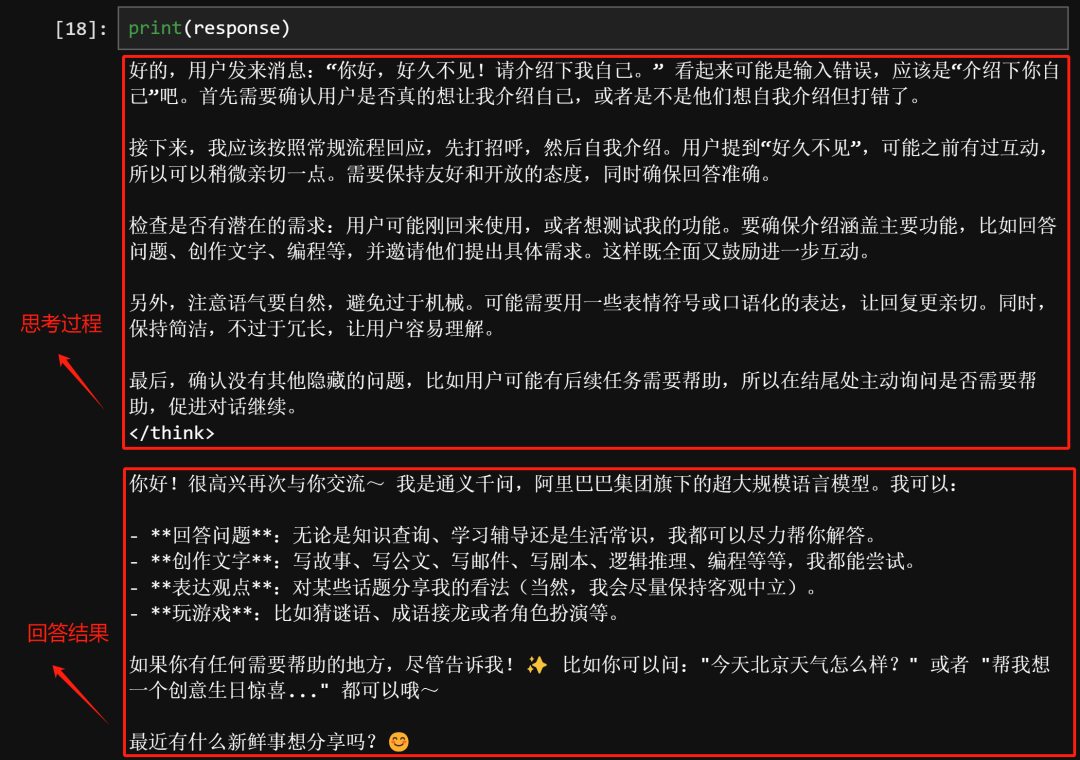
乍一看,如果不是模型自报家门,根本分别不出哪个模型是哪个。
而类似strawberry中有几个r这种推理问题,QWQ的推理和回答流程也堪称完美:

以上问答效果的展示,都是基于QWQ本地部署模型推理得到,并不是使用的在线API,结果更加真实可信。
而更加关键的是,QWQ模型,除了不如DeepSeek开源了底层的算法原理外,在实际应用上,各方面都有非常明显的优势。
首先就是更小的模型尺寸,能够在更轻量的硬件环境下部署。QWQ是一个32B的dense(密集型)模型,实测全精度推理的话仅需64G显存即可运行,也就是4卡4090就能流畅运行:
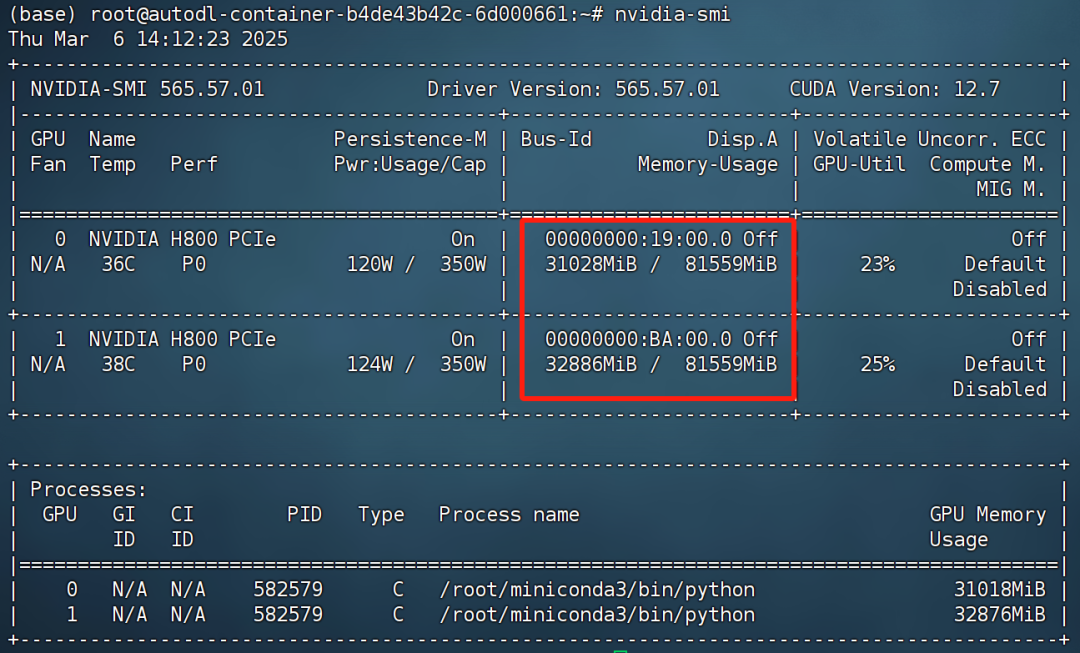
相比之下,DeepSeek R1模型全精度运行则需要至少1200G显存,几乎是QWQ模型的18倍。而如果是运行QWQ的Q4_K_M量化模型,也就是半精度的模型,显存占用甚至可以进一步压缩到不到24G,也就是单卡4090即可运行。
以下是QWQ模型推理、微调硬件要求、模型性能与推荐配置。欢迎扫码领取高清原图:

此外,QWQ模型的第二个核心优势,就在于超长的上下文长度,以及可以兼容Qwen模型生态的全套开发工具。QWQ开源模型就支持128K最大上下文长度,是DeepSeek R1开源版模型的两倍,并且在接入ModelScope-Agent后可以实现Function calling、ReAct等Agent开发核心功能。
同时由于QWQ和Qwen 2.5采用了完全相同的模型架构,因此,该模型已经在开源的第一时间无缝兼容了Ollama、vLLM、SGLang等主流推理框架,以及Unsloth、Llama-factory等主流训练和微调框架,各项功能的实现畅通无阻!
也正因如此,我们团队在第一时间就制作了QWQ模型的全系列教程,包括模型部署、调用、微调、知识库检索、Agent开发等,并上线至赋范大模型技术社区。
今晚8点半,由我主讲的QWQ-32B实战公开直播将正式开始,扫码进入社群即可获取直播链接。

好了,以上就是本期的全部内容。我是九天,如果觉得有用,记得点赞、关注支持哦!加入赋范大模型技术社区,还有更多技术干货等你来学!


















 4573
4573

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









