







医学生一起来学习,挑战7天完成一篇药物靶向MR
Day 1!
上次我们挑战成功NHANES已经成功投稿啦,但是meta的PROSPERO还没下来,只有继续等等啦,这次我们发起7天药物靶向MR挑战!
Day 1:老规矩,还是设定目标期刊
药物靶向MR发的文章分都很高啊,检索一下就发现基本是顶刊文章,确实这个概念比较火热,发文数量也在疯狂增长。同样的思路移植到我自己的关注的领域就是一篇新的顶刊paper,所以我也来尝试挑战挑战自己
我初步检索了一下选了个心内科的疾病,花了一些时间来选题,发现确实没有被写过,所以就开干啦,选了个并且近期发表过药靶MR的期刊作为我的目标期刊。我选定了Cell and Bioscience作为我的目标期刊,选定了来自温州医科大学2024年刚发表的文章‘降糖药物靶点与胃肠癌风险的关联:孟德尔随机研究’作为我的目标文献,检索了一下这可不是什么水刊,发文量和影响因子都可以。这是一个生物学的综合期刊,药物靶向MR投这种杂志妥妥的啊
定下目标,冲锋冲锋!


Day2-3天
进度汇报:在这两天里,我的主要工作集中在深入的研究课题和阅读相关文献上。
孟德尔随机化的方法学是基本一样的,因为前期的一些工作,所以我有代码准备,也就是说只要准备好了代码,以后只需要换个结局、换个暴露就行啦。同时,也正是因为这样,更要充分的去确定选题的可行性,所以我用了2天的时间进行了充分的检索,避免出现撞车的情况,心衰的药物靶向竟然才15篇,有搞头,所以我就选择这个疾病啦,不过药物选哪个呢,充分检索一番???
药物靶点孟德尔随机化可以简单说成,涉及受体、酶、离子通道、转运体、免疫系统、基因等的孟德尔随机化,并且会引入eQTL、pQTL等一些概念。为了方便理解,我做了个药物和表型之间药物靶向MR的简单思路图,很容易就理解啦
所以基于药靶MR的基础,又有很多的衍生方法,比如炎症因子MR、代谢物MR、脂质MR等,方法学都是类似滴。同时呢,药物靶向也有两种思路,一种是老药新治,一种是老病开发新药,这两种情况在临床上都是会经常遇到的
老药新治就是:如果某种药物X对心衰是明确有益作用,通过药靶MR确定药物X对癫痫也有作用,那如果一个病人有心衰合并有癫痫的时候,X就是最佳选择。
老病开发新药就是:我通过药物靶向MR确定了心衰的一些靶点,进而针对这些靶点就可以开发新的药物。同时,数据量大是我们在分析结果时面临的一个限制因素。但只要我们找到了idea,代码其实是简单的事情,跑除了图片加上我的“框架写作发”,TOP顶刊指日可待了!
好的,今天的分享就到这里了!

Day 4-5!
进度汇报:寻找靶基因+跑代码+出图片
药物靶向的代码非常的简单,也非常的好理解,但是要注意的是要搞清楚整个过程中的思路
第1步:明确蛋白与疾病表型存在明显的因果关系或者已知该蛋白能够有效作用于该疾病的治疗。
第2步:寻找调节该蛋白表达的一类基因来模拟药物作用
第3步:寻找到这个靶基因后获取其工具变量与疾病进行单变量MR分析。
这就是我们的药靶的文章设计思路,很重要的一部就是寻找靶基因。一般我们通过eQTL的网站无寻找https:/www.eqtlgen.org/
因为基因表达的过程会受到很多的调控,所以不仅要关注该基因,还要关注该基因的上下游1兆的基因信息
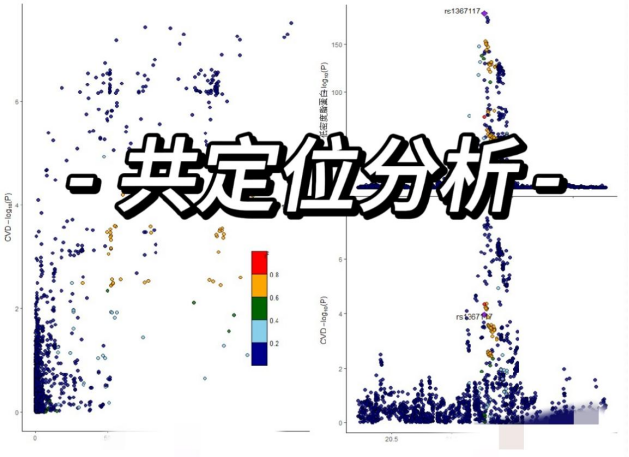
我的eGTL的数据来源于Genomic atlas of the proteome from brain, CSF and plasma prioritizes proteins implicated in neurological disorders,里面包括了来自人体血浆、CSF等的eQTL数据。我对这些下载来的数据进行了预处理,实际上本质就是本地数据的数据处理,然后再用这些数据进行药靶MR的分析,然后再做一个共定位分析
其实就是看暴露X与结局Y的GWAS summary中该区域的所有SNP的位置是不是基本一致的
今日图表弄完啦,就要开始写作啦!



Day 6-7!
完成挑战!
进度汇报:全文框架写作法写作+投稿准备(翻译+润色+选刊)
本次的主要内容是完成写作和进行投稿
经过多轮的挑战,我发现写作是最简单的,无非就是对结果的核心内容的展示,摸透了“框架写作法”,基本预留2天就可以了。1天用来完成初稿,1天进行修改、润色、投稿前的准备,就是有点费时间,不过在科室偶尔闲下来的这种时间可以用来做这部分工作
总结一下药物靶向MR,通过药物与靶点特异性结合,靶点可以通过eQTL、pQTL方法获得该靶点的GWAS数据,获得了GWAS数据就可以来和我关注的表型(具体的疾病等)做MR分析和公定位分析
第1天:设定目标
第2-3天:深入明确选题可行性
第4-5天:寻找靶基因+跑代码+出图片
第6-7天:写作+投稿
总而言之、言而总之,思路简单+核心代码就能轻松实现10+分,当然,因为现在很多的基础实验发布了很多的eQTL、pQTL的数据,这也就意味着,选择并清洗其中的数据都可以写出文章
最近有一些师弟师妹们对meta、nhanes、肠道菌群MR都比较感兴趣。其实我们有一整套的方案,一套光速出成果、发文章的方案:从文献阅读→选题→数据分析→论文框架→论文写作→方法学(双样本MR、药把、中介、多变量、肠道菌菌群、Meta、NAHNES、GBD。。。)
为了高分,冲锋,一起加油呀!!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









