




 本文详细解读了Elasticsearch集群的节点配置、分片策略、脑裂问题防范以及索引设置技巧。包括主从分离、分片副本配置、性能优化建议,适合处理千万至亿级数据的架构设计与调优。
本文详细解读了Elasticsearch集群的节点配置、分片策略、脑裂问题防范以及索引设置技巧。包括主从分离、分片副本配置、性能优化建议,适合处理千万至亿级数据的架构设计与调优。
一:集群
Node节点组合:
主节点
+
数据节点(
master+data) 默认 。
node.master: true (为true只是代表有成为master的资格,如果集群中多个节点为true,需要竞选master)node.data: true (如果请求量和数据量较大,master节点最好不要存储数据)
数据节点(
data
)
node.master: falsenode.data: true
客户端节点(
client
)
不会成为主节点,也不会存储数据,主要是针对海量请求的时候可以进行负载均衡,分担压力
分片:
每个索引有1个或多个分片,均衡分布在集群中的节点上,存储不同的数据。 分片还可以指定副本,防止主分片挂掉,也可以响应查询。 创建索引时在settings中指定(不指定默认一个主分片,一个副本分片):
PUT /my_test
{
"settings":{
"number_of_shards" : "2",
"number_of_replicas" : "2"
},
"mappings":{
"properties":{
"name":{
"type":"text"
}
}
}
}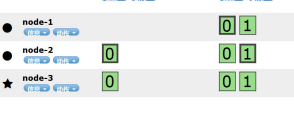
如上,左边是没有设置分片和副本时候,默认一个主分片,一个副本分片。 右边有两个主分片0和1,各有两个副本分片。(主分片不一定在master节点)
集群规划:
1、需要多大规模:
Elasticsearch JVM heap 最大可以设置32G 。 30G heap 大概能处理的数据量 10 T。如果内存很大如128G,可在一台机器上运行多个ES节点实例。 所以通常业务在千万到几亿的数据量,2-4台节点即可。 跟随数据量增加。
2、如何避免脑裂:
脑裂:
集群中出现多个master。
比如master因为处理任务太多,或者网络原因,和其他节点失去联系,然后选出了新的master,后续原master又恢复了。
又比如网络分区,将集群节点划分到两个区域,各分区选出自己的master,后续网络恢复后就有多个master。
解决方式:
1 ) Master 和 dataNode 角色分开,master不存储数据,防止处理业务压力过大或者发送fullGC等失去响应。2)延长 ping master 的等待时长discovery.zen.ping_timeout: 30 (默认值是 3 秒,超过后其他节点ping不通就认为不可用了)es7 中换成了 discovery.request_peers_timeout3)es7之前,尽量避免脑裂,需要添加最小数量的主节点配置discovery.zen.minimum_master_nodes: ( 有 master 资格节点数 /2) + 1。也就是要求过半才选新的master。 这样做可以防止分区后,每个分区都选举。es7中不需要配置,集群自己控制。
以上措施都只能在一定程度上防止脑裂,并不会真正杜绝。
3、索引设置多少分片和副本?
分片: ElasticSearch 推荐的最大 JVM 堆空间是 30~32G, 所以把你的分片最大容量限制为 30GB(也就是es能直接使用的内存), 然后再对分片数 量做合理估算 . 例如 , 你认为你的数据能达到 200GB, 推荐你最多分配 7 到 8 个分片(理论上一个节点只有一个分片是最快的,实际上不可能那么设置)。在开始阶段 , 最好是根据你的节点数量按照 1.5~3 倍的原则来创建分片 . 例如 , 如果你有 3 个节点 , 则创建不超过9个。当性能下降时,增加节点,ES 会平衡分片的放置副本: 为保证高可用,副本数设置为 2 即可,所以要求至少3个节点。 如果增加节点,可以重新设置副本数,提升查询性能。
注意: 创建索引后,分片数就不能变。 但是副本数是可以调节的。
性能优化建议:
写操作:
1. 副本数置 0如果是集群首次灌入数据 , 可以将副本数设置为 0,写入完毕再调整回去,这样副本分片只需要拷贝,节省了索引过程.2 自动生成 doc ID如果写入 doc 时如果外部指定了 id ,则 Elasticsearch 会先尝试读取原来doc 的版本号,以判断是否需要更新。这会涉及一次读取磁盘的操作,通过自动生成 doc ID 可以避免这个环节。3、合理设置mappings。 不需要分词的尽量用keyword,不需要索引字段的就不要索引。4、对不需要打分的字段,禁用norms属性。5、增大索引的刷新时间(默认1s),这种方式牺牲了可见性,不能及时看到最新的结果。PUT /my_index/_settings{"index" : {"refresh_interval": "30s"}}6、写操作使用批处理。
读操作:
1、使用filter代替query如果搜索不需要打分,可以直接使用 filter 查询。如果部分搜索需要打分,建议使用 'bool'查询。把打分的查询和不打分的查询组合在一起使用。2、对于不需要range查询的numeric 类型,还是尽量使用keyword来等值查询。numeric为了做范围查询,没有使用倒排索引,而是使用的block KD tree的存储结构。3、对参数做优化,不要出现很多OR或者* 的查询
相关文章推荐:

















 2169
2169

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









