




 本文详细介绍了Elasticsearch的基础索引操作,包括创建、修改映射、数据插入与搜索,以及高级查询技巧如多字段匹配、聚合、地理位置检索等。适合理解索引结构和进行高效信息检索。
本文详细介绍了Elasticsearch的基础索引操作,包括创建、修改映射、数据插入与搜索,以及高级查询技巧如多字段匹配、聚合、地理位置检索等。适合理解索引结构和进行高效信息检索。
索引和映射:
//查看分词结果
POST _analyze
{
"analyzer": "ik_max_word",
"text": "南京市长江大桥"
}
//创建索引
PUT /my-test
//查看索引信息
GET /my-test
//查看索引是否存在
HEAD /my-test
//打开关闭
POST /my-test/_close
POST /my-test/_open
//删除
DELETE /my-test
//创建索引和映射
PUT /my-test
{
"settings": {
"number_of_shards": 9,
"number_of_replicas": 1
},
"mappings": {
"properties": {
"name":{
"type": "text",
"analyzer": "ik_max_word"
},
"logo":{
"type": "keyword",
"index": false
},
"payment":{
"type": "float"
}
}
}
}
//修改索引映射(只能增加字段,其他修改只能删除索引重新建立)
PUT /my-test/_mapping
{
"properties": {
"address":{
"type": "text",
"analyzer": "ik_max_word"
}
}
}
//查看映射
GET /my-test/_mapping
映射类型:
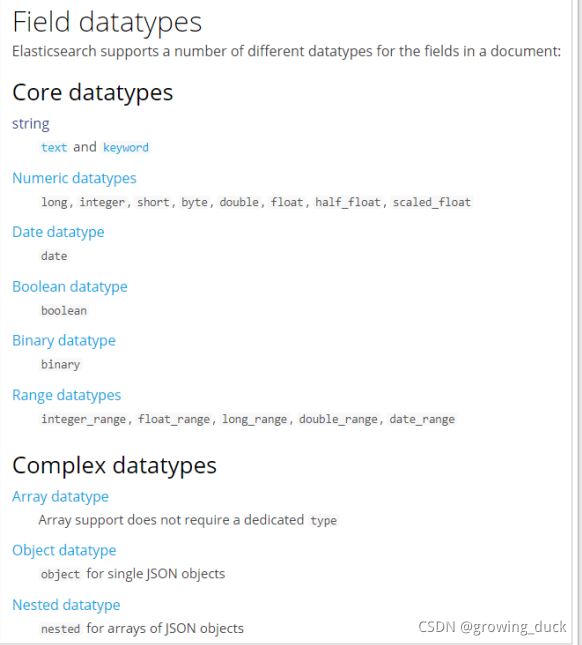
1) typeString类型,又分两种:text:可分词,不可参与聚合keyword:不可分词,数据会作为完整字段进行匹配,可以参与聚合Numerical:数值类型,分两类基本数据类型:long、interger、short、byte、double、flfloat、half_flfloat浮点数的高精度类型:scaled_flfloat需要指定一个精度因子,比如10或100。elasticsearch会把真实值乘以这个因子后存储,取出时再还原。Date:日期类型elasticsearch可以对日期格式化为字符串存储,但是建议我们存储为毫秒值,存储为long,节省空间。Array:数组类型进行匹配时,任意一个元素满足,都认为满足排序时,如果升序则用数组中的最小值来排序,如果降序则用数组中的最大值来排序2)indextrue:字段会被索引,则可以用来进行搜索。默认值就是true
false:字段不会被索引,不能用来搜索3)store是否将数据进行独立存储。 原始的文本会存储在 _source 里面,store:true来独立存储,要比从_source中解析快得多,但是也会占用更多的空间,所以要根据实际业务需求来设置, 默认为false。4)analyzer:指定分词器一般我们处理中文会选择ik分词器 ik_max_word ik_smart
文档:即数据
//插入数据
POST /my-test/_doc/1
{
"name":"张三",
"logo":"www.baidu.com",
"payment":30000
}
POST /my-test/_doc/2
{
"name":"李四",
"logo":"www.baidu.com",
"payment":30000
}
//查找
GET /my-test/_doc/1
//查找所有
GET /my-test/_search
POST /my-test/_search
POST /my-test/_search
{
"query": {
"match_all": {}
}
}
//按id查找,返回指定字段
GET /my-test/_doc/1?_source=name,logo
//更新
POST /my-test/_update/1
{
"doc": {
"name":"张三"
}
}
//删除
DELETE /my-test/_doc/1
//按条件删除
POST /my-test/_delete_by_query
{
"query": {
"match": {
"name":"李四"
}
}
}
//全部删除
POST /my-test/_delete_by_query
{
"query": {
"match_all": {}
}
}
Query DSL:
//分词后使用or查询
GET /my-test/_search
{
"query": {
"match": {
"name": "小米电视4A"
}
}
}
//分词后使用and查询
GET /my-test/_search
{
"query": {
"match": {
"name": {
"query": "小米电视4A",
"operator": "and"
}
}
}
}
//短语查询,最小须满足此短语
GET /my-test/_search
{
"query": {
"match_phrase": {
"name": "小米电视"
}
}
}
//query_string可以不指定字段查询,也可指定一个或多个字段
GET /my-test/_search
{
"query": {
"query_string": {
"query": "小米电视"
}
}
}
GET /my-test/_search
{
"query": {
"query_string": {
"default_field":"name",
"query": "小米电视"
}
}
}
//注意: AND大写,否则不生效
GET /my-test/_search
{
"query": {
"query_string": {
"default_field": "name",
"query": "小米 AND 手机"
}
}
}
GET /my-test/_search
{
"query": {
"query_string": {
"fields":["name","content"],
"query": "小米电视"
}
}
}
//multi_match也可支持多个字段,效果和query_string,但是不支持AND查询,
GET /my-test/_search
{
"query": {
"multi_match": {
"fields":["name","content"],
"query": "小米手机"
}
}
}
//term:查询指定字段中,有指定value的分词
//和上面and查询不一样的是,and要求分词中,同时包含小米和手机,而term要求分词中一定有小米手机这个词
GET /my-test/_search
{
"query": {
"term": {
"remark": {
"value": "小米手机"
}
}
}
}
//term也可指定多个value,分词中满足一个即可
GET /my-test/_search
{
"query": {
"terms": {
"name": [
"小米手机",
"电视"
]
}
}
}
//range范围查询
GET /my-test/_search
{
"query": {
"range": {
"payment": {
"gte": 500,
"lte": 10000
}
}
}
}
GET /my-test/_search
{
"query":{
"range":{
"create_time": {
"gte": "2021-05-11 00:00:00",
"lte":"2021-05-12 00:00:00",
"format": "yyyy-MM-dd HH:mm:ss",
"time_zone": "+08:00"
}
}
}
}
//exists:指定字段有值
GET /my-test/_search
{
"query": {
"exists":
{
"field": "logo"
}
}
}
//prefix: 指定的字段分词中,有以value开头的
GET /my-test/_search
{
"query": {
"prefix": {
"name": {
"value": "小米"
}
}
}
}
//wildcard: 字段分词中有 电xx的
GET /my-test/_search
{
"query": {
"wildcard": {
"name": {
"value": "电*"
}
}
}
}
//id集合查询
GET /my-test/_search
{
"query": {
"ids": {
"values": [1,2,3]
}
}
}
//fuzzy: 分词中包含指定value为电圈的,允许value中有一个词是错的,也就是分词包含电或者圈的都能查出来
GET /my-test/_search
{
"query": {
"fuzzy": {
"name": {
"value": "电圈",
"fuzziness": 1
}
}
}
}
复合查询:
GET /my-test/_search
{
"query": {
"term": {
"name": {
"value": "华为"
}
}
}
}
//constant_score: 可包装上面的term查询,并对结果给一个分值
GET /my-test/_search
{
"query": {
"constant_score": {
"filter": {
"term": {
"name": "华为"
}
},
"boost": 1.2
}
}
}
//bool: 组装多个条件
//must: 多个条件同时满足
//should: 多个条件中满足n个即可,n由minimum_should_match指定,不指定默认为1
//filter:同must,只是不对结果打分,可使用缓存,性能更好
GET /my-test/_search
{
"query": {
"bool": {
"must": [
{"match": {
"name": "手机"
}}
],
"must_not": [
{"match": {
"name": "aa"
}}
],
"should": [
{"term": {
"logo": {
"value": "小米手机"
}
}},
{
"term": {
"logo": {
"value": "华为手机"
}
}
}
],
"filter": [
{"range": {
"payment": {
"gte": 10000,
"lte": 40000
}
}}
],
"minimum_should_match": 1
}
}
}
排序分页统计:
//分页排序
GET /my-test/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"payment": {
"order": "asc"
}
},
{
"_id": {
"order": "desc"
}
}
],
"size": 5,
"from": 0
}
//count: 统计条数
GET /my-test/_count
{
"query": {
"range": {
"payment": {
"gte": 20000
}
}
}
}
//aggs: 桶。 将数据放到桶里,再进行统计如max,avg,group by 等
//最大值
GET /my-test/_search
{
"size": 0,
"aggs": {
"maxPayment": {
"max": {
"field": "payment"
}
}
}
}
//求和 sum
GET /edu_user_asset_trade_record/_search
{
"size": 0,
"aggs": {
"query_amount": {
"sum": {
"field": "trade_count"
}
}
},
"query": {
"bool": {
"must": [
{
"term": {
"trade_type": {
"value": 2
}
}
},{
"range": {
"create_time": {
"gte": "2022-06-01 00:00:00",
"lt":"2022-07-01 00:00:00",
"format": "yyyy-MM-dd HH:mm:ss",
"time_zone": "+08:00"
}
}
}
]
}
}
}
//value_count:统计payment字段不为空的条数
GET /my-test/_search
{
"size": 0,
"aggs": {
"paymentCount": {
"value_count": {
"field": "payment"
}
}
}
}
//效果同上
GET /my-test/_count
{
"query": {
"exists": {
"field": "payment"
}
}
}
//cardinality: 统计去重后的条数
GET /my-test/_search
{
"size": 0,
"aggs": {
"nameCount": {
"cardinality": {
"field": "payment"
}
}
}
}
//collapse: 查询去重后的字段:select distinct(logo) from xxx where name = '小米'
GET /my-test/_search
{
"query": {
"term": {
"name": {
"value": "小米"
}
}
},
"collapse": {
"field": "logo"
}
}
//select count(1) from xx group by payment
GET /my-test/_search
{
"size": 0,
"aggs": {
"group_by_payment": {
"terms": {
"field": "payment"
}
}
}
}
//不仅统计group by后的条数,还可以统计出group by后,对某个字段重后的条数
GET /my-test/_search
{
"size": 0,
"aggs": {
"group_by_payment": {
"terms": {
"field": "payment"
},
"aggs": {
"my_distinct": {
"cardinality": {
"field": "logo"
}
}
}
}
}
}
// select payment,avg(payment) my_by_payment,count(*) mycount from xxx group by payment having my_by_payment > 20000 and mycount >=1;
GET /my-test/_search
{
"size": 0,
"aggs": {
"group_by_payment": {
"terms": {
"field": "payment"
},
"aggs": {
"my_avg_value": {
"avg": {
"field": "payment"
}
},
"having":{
"bucket_selector": {
"buckets_path": {
"mycount": "_count",
"myAvgValue": "my_avg_value"
},
"script": {
"source": "params.myAvgValue >20000 && params.mycount >= 1"
}
}
}
}
}
}
}
//stats: 同时统计count max min avg sum 5个值
GET /my-test/_search
{
"size": 0,
"aggs": {
"my_count": {
"stats": {
"field": "payment"
}
}
}
}
//percentiles: 统计指定百分比的值,默认统计1,5,25,50,75,95,99这几个百分比阶段的值
GET /my-test/_search
{
"size": 20,
"aggs": {
"my_percent": {
"percentiles": {
"field": "payment"
}
}
}
}
//统计百分之二十和五十阶段的值
GET /my-test/_search
{
"size": 20,
"aggs": {
"my_percent": {
"percentiles": {
"field": "payment",
"percents": [
20,50
]
}
}
}
}
//统计小于15和小于1000000的数据的百分比
GET /my-test/_search
{
"size": 0,
"aggs": {
"my_percent": {
"percentile_ranks": {
"field": "payment",
"values": [
15,
1000000
]
}
}
}
}
bulk批量增删改:
//删除索引id为1的,创建索引id为6的数据,修改索引id为2的数据的name和logo字段
POST /my-test/_bulk
{"delete":{"_id":1}}
{"create":{"_id":6}}
{"name":"三星手机","logo":"三星手机","content":"三星手机","remark":"三星手机","payment":60000}
{"update":{"_id":2}}
{"doc":{"name":"小米电视手机","logo":"小米电视手机"}}
bulk通常用于批量插入,,批量删除,批量更改。
格式:每个json不能换行。相邻json必须换行。
实际用法:bulk请求一次不要太大,否则一下积压到内存中,性能会下降。所以,一次请求几千个操作、大小在几M最好。
坐标:geo_point
将上面的my-test索引删掉,从新建立索引:
PUT /my-test/
{
"mappings": {
"properties": {
"name":{
"type": "text",
"analyzer": "ik_max_word"
},
"remark":{
"type": "keyword"
},
"location":{
"type": "geo_point"
},
"age":{
"type": "integer"
}
}
}
}
//插入3条数据 注意:location使用[]传值,经纬度顺寻与其他两种不一样
POST /my-test/_doc/1
{
"name":"我是大帅哥",
"remark":"华为手机",
"age":10,
"location":[73.989,40.722]
}
POST /my-test/_doc/2
{
"name":"我是大帅哥2",
"remark":"华为手机",
"age":10,
"location":"40.722,73.989"
}
POST /my-test/_doc/3
{
"name":"我是大帅哥3",
"remark":"华为手机",
"age":10,
"location":{
"lat":40.722,
"lon":73.989
}
}
//geo_bounding_box:指定两个点,在其为对角线的长方形中,包含的所有点
GET /my-test/_search
{
"query": {
"bool": {
"must": [
{"match_all": {}}
],
"filter": [
{"geo_bounding_box": {
"location": {
"top_left": {
"lat": 40.73,
"lon": 71.12
},
"bottom_right": {
"lat": 40.01,
"lon": 74.0
}
}
}}
]
}
}
}
//geo_distance: 距离指定点100km半径范围内所有的点
GET /my-test/_search
{
"query": {
"bool": {
"must": [
{"match_all": {}}
],
"filter": [
{"geo_distance": {
"distance": "100km",
"location": {
"lat": 40.722,
"lon": 73.989
}
}}
]
}
}
}

















 1067
1067

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









