 GPORCA优化器:详解Greenplum中的Cascades模型与Transform流程
GPORCA优化器:详解Greenplum中的Cascades模型与Transform流程





优化器是数据库的关键组件,GPORCA是Greenplum中的强大的模块化查询优化器,帮助用户对SQL进行优化,生成高效的查询计划,提高查询效率。GPORCA优化器架构是基于Cascades 模型,本文将对GPORCA优化器的Transform流程进行详细介绍。
优化器简介
SQL是一种描述性语言。对于一个复制的SQL语句,可能生成几十上百个等价的执行计划。实际上,选择最优执行计划的问题,已经被证明是一个 NP-HARD 问题。因此,人为的把SQL推导成执行计划,并从众多的执行计划中获取一个最优的,几乎是不可能的。
优化器作为数据库的关键组件不可或缺。它接收语法树,推导出等价执行计划,并选出最优的执行计划,交给执行器执行。
优化器一般使用动态规划实现,动态规划可以提供的特性:
-
无后效性:即子问题的解一旦确定,就不再变,不受这之后、包含它的更大的问题的求解决策影响。
- 重叠子问题:求解时,可能会遇到重复的子问题,记录子问题的解可以避免重复计算。
Cascades 优化器
我们知道,优化过程就是递归处理整个语法树的过程。遍历树可以从根节点开始,自上而下地访问。也可以从叶子节点自下而上的访问。Cascades作为新一代的优化器,使用的是自上而下的策略进行优化的。
Cascades 的关键组件
下面是 Cascades 的关键组件构成:
- Memo :为了执行优化,需要提供搜索空间
- Group :每个 Group 保存的是逻辑等价的 Group Expression Group
- Expression :作为表达式在Cascades中的管理器,真正的优化单元。
如下图所示,是一个被初始化好后的 Memo 。
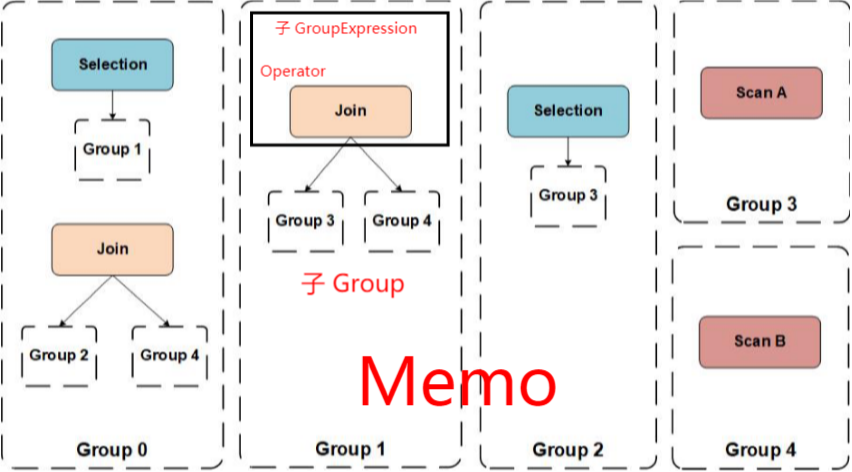
Group0 中的 Selection , Join 是等价的 Group Expression ,作为 Group0 的子 Group Expression
每个 Group Expression 又引用了其他的 Group ,作为这个表达式的子 Group 。
把上图的 Memo 的Group和Group Expression中的父子关系串联起来,就可得到图2的两个等价的表达式树。
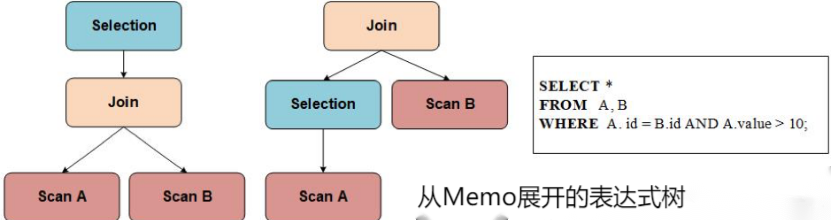
Cascades的优化流程
Cascades优化器的优化,主要分为3个阶段:
- Exploration :主要负责推导等价的逻辑表达式。
- Implementation :主要负责把逻辑表达式转化为物理表达式
- Optimization :主要负责搜索最优的执行计划 。
Optimization 主要是基于代价,比较不同的等价物理表达式树的代价,把总代价为最小的执行计划,作为最优解,输出给执行器执行;优化是基于代价的, 称为基于代价的优化(Cost Based Optimization,CBO)
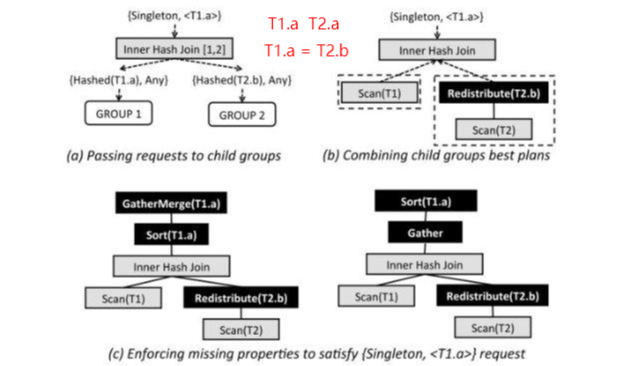
Cascades扩展机制
-
Cascasdes的设计中,设计了Property Enforcer(排序,Hash重分布)。
-
我们根据Enforcer Property信息,决定是否添加Enforcer节点。
-
在Optimization阶段添加Enforcer节点。
下图中的黑色节点,就是Enforcer的节点:
GPORCA Transformation 的实现
这篇文章,主要介绍基于规则的优化,我们称为Transformation。
初始化Memo
为了简单,我们这里的例子选取了简单的语句gpadmin=# \d testTable "public.test"Column | Type | Collation | Nullable | Default--------+---------+-----------+----------+---------a | integer | | |Distributed by: (a)例子语句:select a from test;
优化前,需要把语法树,放入Memo中,放入的规则是这样的:
-
为语法树的每个表达式,创建一个Group,为表达式中的操作符,创建一个Group Expression,放入这个Group中。
-
原来表达式的父子关系,转变为父的Group Expression,和子表达式所在Group的引用关系。
-
把表达式中的派生属性,放入Group中。
Greenplum的Log信息输入的表达式树:Algebrized query:+--CLogicalGet ""test"" (""test""), Columns: [""a"" (0), ......]---顺序扫描的逻辑操作符Initinal Memo:ROOT ----语法树的根表达式所在的组Group 0 (#GExprs: 1):0: CLogicalGet ""test"" (""test""), Columns: [""a"" (0), ......]---顺序扫描的逻辑操作符
- 表达式树中的CLogicalGet, 实际上是作为CExpression对象的操作符存在的。
- Group中的CLogicalGet, 实际上是作为CGroupExpression对象的操作符存在的。
Transformation
初始化完Memo(搜索空间)后,就会进入Transformation阶段。整个树进行Transform是一个后序遍历的过程。
GPORCA通过规则对表达式做转换,规则分为两类:
-
- Exploration,是对逻辑表达式做等价变换的。
- Implementation,是把逻辑操作符转换为物理操作符。
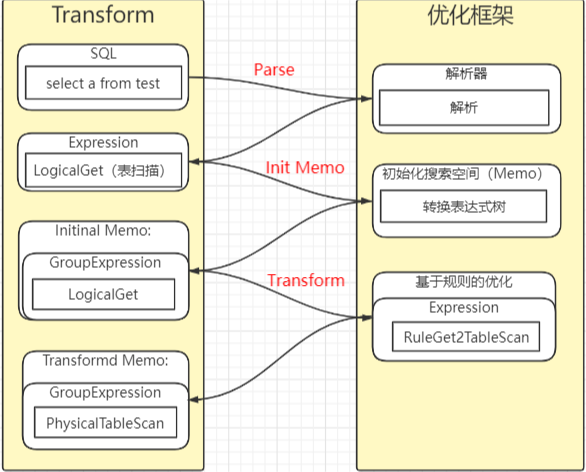
上图中可以看到,在 Transformation 阶段, LogicalGet 通过规则转换为 PhysicalTableScan
下面来看 Transformation 的Log信息:
Xform: CXformGet2TableScan---->RuleGet2TableScanInput:+--CLogicalGet ""test"" (""test""), Columns: [""a"" (0), ......(系统列)]Output:+--CPhysicalTableScan ""test"" (""test"") cost:-0.500000
这就是例子语句的Transformation的Log信息。 CLogicalGet 通过规则 CXformGet2TableScan 转换为 CPhysicalTableScan。
这里需要说明,因为例子语句,对应的是顺序扫描,在 Exploration 阶段,不需要做等价变换,所以直接在 Implementation 阶段,通过 CXformGet2TableScan 做了转换。
-
规则管理
一个表达式,可能对应多个规则。Cascades的设计中,使用集合来管理规则。工程实现中,GPORCA使用位图来管理规则。
规则的集合分两类:
- Exploration Set: 用于 Exploration 的规则。
- Implementation Set: 用于 Implementation 的规则。
- Exploration阶段,拿操作符的规则集和逻辑变换集合取与,得到操作符这个阶段需要的规则
- Implementation阶段,拿操作符的规则集和实现变换集合取与,得到操作符这个阶段需要的规则集
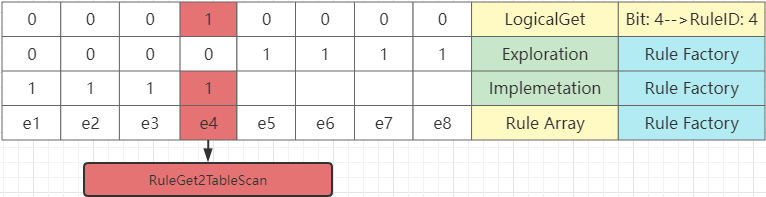
GPORCA通过规则工程管理规则集,包括 Exploration 和 Implementation 。上图中,0和1有8列,表示规则集。为了简单,我们假设CLogicalGet需要的规则ID是4。
-
LogicalGet所在的行,左边的规则集记录了LogicalGet需要的规则。可以看到第四位被设置为1,可以知道LogicalGet需要ID为4的规则进行转换。
-
Exploration所在的行的规则集,表示所有的规则的集合。5,6,7,8位被设置为1,所以Exploration的规则集是ID为{5,6,7,8}的规则集。
-
同样的,Implementation的规则集为{1,2,3,4}
规则匹配:
-
Exploration 优化阶段, LogicalGet 和Exploration的规则集取与的结果为空集,所以直接跳过。
-
Implementation 阶段,取与的结果是 4 ,是 CXformGet2TableScan 的ID,所以应用这个规则
-
绑定
实际上在应用规则前,还涉及到规则和表达式的匹配逻辑,称为绑定流程。
通过前面的Memo的介绍可以看到, Group 和 GroupExpression ,形成了一个森林。Group内部,都是等价的表达式,所以理论上说,不同 Group 中的 GroupExpression 可以随意组合,形成一个新的操作符树。但是不是所有的树,都有意义,所以在组装操作符树的时候,需要控制信息做指导,以生产新的有意义的操作符树。我们把这个过程称为规则的绑定。
我们把控制规则绑定的对象称为模式,抽象为接口类:CPattern。CPattern被几个子类继承,代表了不同的模式。
-
模式的分类
GPORCA设计:
- CPatternLeaf
- 匹配规则:叶子节点。
- 展开规则:只需要展开当前节点。
- CPatternTree
- 匹配规则:操作符树。
- 展开规则:先循环遍历子节点,并展开子节点;再展开当前节点。
- CMultiPatternLeaf
- 匹配规则:多于一个叶子节点。
- 展开规则:只需要展开多个叶子节点。
- CMultiPatternTree
- 匹配规则:多于一个操作符树。
- 展开规则:先循环遍历多个子节点,并展开子节点;再展开当前节点。
2. 模式的匹配
模式作为特殊的操作符,多个模式最终组合成一棵模式树,来做模式匹配的工作;模式树的节点也可以是普通的操作符。
- 非根 Group 的 GroupExpression 可以被重复使用
- Group 的子节点必须至少有一个匹配模式树中相应的子节点。
- 如果模式树中被处理的节点是Pattern节点,则匹配所有 Group 中的 GroupExpression
- 如果模式树中被处理的节点是一个普通的表达式
1.Pattern.OperatorId==GroupExpression.OperatorId1. Pattern.ChildNum == GroupExpression.ChildNum -----> success2. Pattern.Child[0] -->MultiPatternLeaf || MultiPatternTree1. Pattern.ChildNum == 1 || Pattern.ChildNum == 21. GroupExpression.ChildNum > 1 -----> success
3. 模式的绑定
绑定过程是递归的从 Group 中取出所有的 GroupExpression ,以后序遍历的顺序,匹配给定的模式树。
绑定的操作:
- 展开匹配模式的 GroupExpression , 输出为 Expression 。
- 这个 Expression ,会拷贝原始 Group 的属性。
- 建立 Expression 之间的父子关系
- 把展开后的 Expression (表达式树),插入到 Memo 中。
4. 绑定要解决的问题
- 符合模式的父与子可以任意匹配
- 以当前展开的表达式作为 Cursor ,对一个 GroupExpression 展开下一个符合 Pattern 的表达式,直到所有匹配 Pattern 的 Expression 被产生,并 Transform 。
CGroupExpression::Transform(......){CExpression *pexprPattern = pxform->PexprPattern(); //模式CExpression *pexpr = binding.PexprExtract(......); //展开第一个表达式。while (nullptr != pexpr){// resultNum := len(result.AlternativeExprs)pxform->Transform(pxfctxt, pxfres, pexpr); //应用规则CExpression *pexprLast = pexpr; //设置 Cursorpexpr = binding.PexprExtract(......, pexprLast) //展开下一个表达式,循环处理}}func (binding *Binding) ExtractGroupExpr(......) *Expression {// Cursor:pexprLast,生成下一组子表达式。if (!FExtractChildren(mp, pgexpr, pexprPattern, pexprLast, pdrgpexpr)){return nil //返回空,对应 FExtractChildren 返回 false, 即所有的子Group已经处理完成。}//生成要被转换的表达式CExpression *pexpr = PexprFinalize(mp, pgexpr, pdrgpexpr);// GPOS_ASSERT(nil != ret);return pexpr;}BOOL CBinding::FExtractChildren (.......) bool{return binding.AdvanceChildCursors(groupExpr, pattern, lastExtractedExpr, exprs)}CBinding::FAdvanceChildCursors(......) bool{//**GroupExpression** 的孩子数const ULONG arity = pgexpr->Arity();for (ULONG ul = 0; ul < arity; ul++){childPattern := binding.ExpandPattern(......) //取子 Patternif cursorAdvanced{//找到匹配的下一个表达式CExpression *pexprPatternChild = PexprExpandPattern(......);}else{lastExtractedChild := lastExtractedExpr.Children[i] //取子 Cursor// 展开子Groupchild = binding.ExtractGroup(group, childPattern, lastExtractedChild)if (nullptr == pexprNewChild){// 从 lastExtractedChild 没有找到匹配的表达式,把 Cursor 重置为空从头开始// 重复利用子表达式pexprNewChild = PexprExtract(......)//增加重置Cursor数ulExhaustedCursors++;}else{// 找到匹配节点fCursorAdvanced = true;}}}//如果相等,则说明所有的子Group都重置了Cursor,说明所有的子Group处理完成return ulExhaustedCursors < arity;}
实际上,因为 Cursor 本身是一个表达式树,所以 Cursor 的子表达式作为子 Cursor ,在绑定子表达式时被用作 Cursor ,处理绑定。
- 绑定产生的新的 Group 的处理
-
- Memo 中的 Group , GroupExpression 只会增加,不会删除
- Group 的 ID ,和 GroupExpression 的 ID 是递增关系,绑定时,是按照ID的顺序从小到大处理的。这样就能保证新添加的 ID 一定大于已有元素的 ID ,在后序的遍历中得到处理。
- 绑定中所有父节点需要绑定的子节点都存在
-
- 后序遍历,处理 GroupExpression 的 Transform 。这样,在父 GroupExpression 被处理前,所有的子 GroupExpression 已经做完 Transform ,新生成的所有符合子 Pattern 的子 Expression 被放入 Memo ,供父 GroupExpression 使用。
到这里,Transformation的主要流程就介绍完了。后续会介绍GPORCA的属性管理,统计信息管理,优化流程,请多多关注。
作者
简介
杜士雄,资深研发,架构师
曾就职于百度,搜狗等厂。现在专注研究分布式数据库领域,负责分布式数据库的开发工作

 来一波 “在看”、“分享” 和 “赞” 吧!
来一波 “在看”、“分享” 和 “赞” 吧!
本文分享自微信公众号 - Greenplum中文社区(GreenplumCommunity)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“ OSC源创计划 ”,欢迎正在阅读的你也加入,一起分享。

















 638
638

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









