




 本文介绍了B树作为数据库索引的重要性,尤其是B+树在减少磁盘IO方面的优势。Greenplum使用的是Blink树,一种基于B+树的优化结构,提供高效的并发控制和故障恢复。文章详细讲解了B树的基本知识、存储结构、操作算法和并发控制,同时提到了索引相关的系统表。Blink树在Greenplum中用于提高查询性能,特别是在并发环境下。
本文介绍了B树作为数据库索引的重要性,尤其是B+树在减少磁盘IO方面的优势。Greenplum使用的是Blink树,一种基于B+树的优化结构,提供高效的并发控制和故障恢复。文章详细讲解了B树的基本知识、存储结构、操作算法和并发控制,同时提到了索引相关的系统表。Blink树在Greenplum中用于提高查询性能,特别是在并发环境下。
了解更多Greenplum技术干货,欢迎访问Greenplum中文社区网站
7月24日,Greenplum原厂内核研发马洪旭和大家直播分享了《深入浅出Greenplum内核》系列直播的第四期《Greenplum内核揭秘之B树索引》。相关视频已上传至Greenplum中文社区B站频道,戳这里即可观看。本文概括了文章的精华内容,欢迎大家给我们留言交流。
索引是数据库中的重要组件,而B树则是最常见的索引数据结构,同时它也是Greenplum中的默认索引类型。今天我将给大家详细介绍B树索引。本文将涵盖B树的基础知识、B树的存储结构、操作算法、并发控制,相关系统表等知识。
B树的基本知识
首先和大家介绍一下B树的基础知识。大家一般在大学的数据结构课程中都学过B树,如今回忆起来,很多人都会问,为什么数据库索引经常会选用b树来实现数据库索引呢?Greenplum的B树索引和我们大学课程中介绍的是否完全一样呢?它的数据结构和算法是不是和课程中介绍的完全一样呢?大家可以思考一下这几个问题,看完这篇文章就能知晓答案。
01 索引
在开始介绍B树索引之前,先给大家简单介绍一下索引。大家在网上看到的定义往往太过复杂,我自己给他下了一个简单的定义:索引就是能加速一个常规操作的数据结构。为了方便大家的理解,这里我给大家举了一个简单的例子,在用字典时,当我们想查某个词的时候,我们可以选择从这字典从头到尾逐页翻查,可想而知,这样的查询速度非常慢,如果我们使用这本字典附录中的索引,查询速度就会大幅提高。

索引包括本文即将详细介绍的B树索引,另外还有哈希索引和倒排索引。其中哈希索引比较常见,比如一个很简单的程序,里边会执行一个数据查询,查询到的结果都存储到哈希表里,下次再访问的时候,会先到哈希表里,判断数据是否已经存在,如果已经存在,就没有必要再运行这个查询,这就是哈希索引。
倒排索引往往用于全文检索中,大家平时在用百度或者谷歌搜索的时候,就会用到全文检索,其背后的索引是倒排索引。
02 B树
介绍完索引,我们再来了解一下B树。大家需要注意的是,B树实际上是一个很大的家族,因此大家在技术文章或者博客的时候,需要留意他所提及的B树具体是哪种B树。B树可以细分多个子类别,对比我们大学的数据结构课程,课里提及的一个结构容易与B树混淆。即二叉树。二叉树和B树都是平衡树,但二叉树它的每个节点里只能存储一个键值,而B树中的每个节点都存储了大量键值,因此树不会太高。
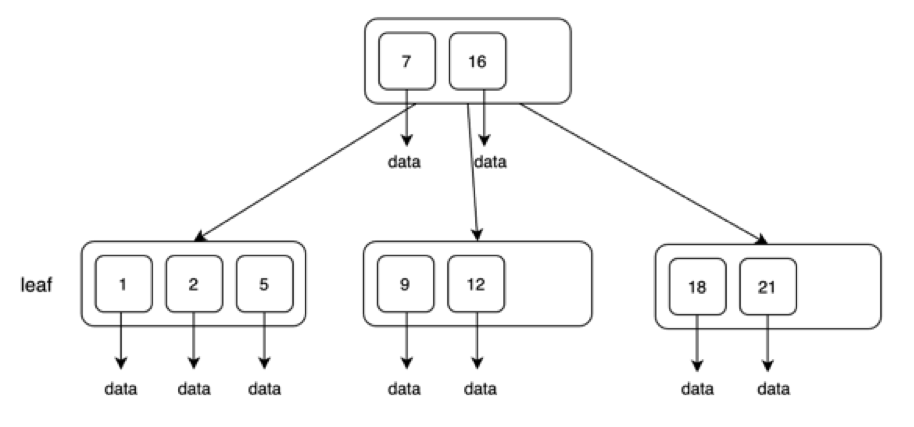
具体大家看上图这个典型的B树,它的节点里存储了很多键值,这些键值也是有序排列,比如图中的1,2,5,7,9,12,16,18,21。每个键值都会指向目标数据。
B+树是B树最常见的一个子类别,下图就是一个典型的B+树。B+树的特点是叶子层节点存储了全部键值,这些键值再指向目标数据,比如图中的1,2,5,9,12,18,21。内部节点中重复存储部分键值,但不含数据指针。叶子节点层有一个正向的遍历列表。
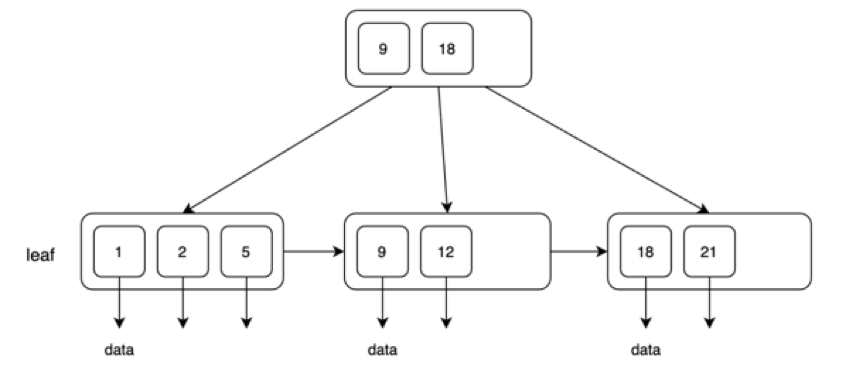
这里我们就会解答开始时让大家思考的第一个问题:为什么经常使用B树来作为数据库的索引结构?实际上是B+树。B+树非常适用于数据库中的索引结构,它的最主要的目的就是减少磁盘lO,每个节点对应磁盘中的一个页,访问节点对应一次磁盘IO。因此我们会希望树非常扁,即树的高度非常少,因为树的高度就是访问磁盘IO的次数。
为什么使用B+树?因为B+树在节点不用存储数据或数据指针,因此每个节点里能存储的键值要比B树多,存储的键值多,B树就会变得非常扁,高度会非常低,磁盘lO就更少。因此我们选用的经常是B+树。
还有一个原因是我们经常需要范围查找,比如上图中如果要找到有2~9的数据,我们把2的数据找到后,沿着右侧方向就能把5和9也找到,因为在页的节点层有右上指针,因此我们不再需要从根出发,而是直接向右移动就能找到。
B+树也是Greenplum中的默认索引类型。Greenplum是基于Postgresql并在其之上做了很多改进。因为Postgresql也是个传统数据库,因此它选用的也是B+树。比如下面的例子中,我们在一个大表中查找了一个ID等于1万数据,共花了20秒的时间。接着我们建立了一个索引,需要留意的是,这里并没有指明索引的类型,这样的话,默认就是B树的。然后我们再查一次,这次花了200毫秒,提升了100倍。大家可以看到,使用索引可以很好地提升查询的性能。
demo=# select * from big where id=10000;
…
Time: 19490.566 ms
demo=# create index 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 526
526

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









