




一、 架构分析
我们来实现一个简单的线程池,先看一下都需要实现哪些部分。
我们对需求进行一下简单的抽象分析,就可以发现这个跟生产者/消费者模型有点像,我们可以画个图,边分析边往上加
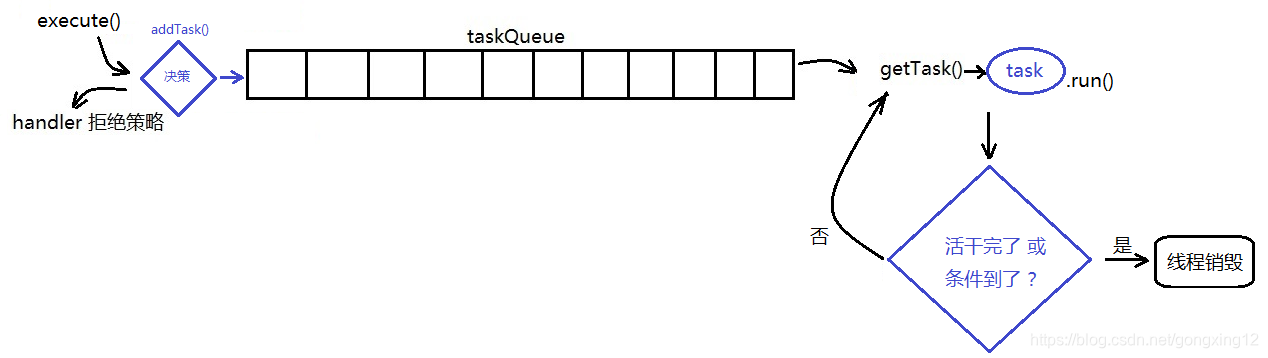
1. 以生产者/消费者模型为基础创建架构。需要一个队列taskQueue 用以缓存要执行的任务,通过execute()方法从外部向线程池提交任务,封装一个方法用来决策,是立即创建线程、放入队列还是拒绝。
2.创建线程可以用工厂设计模式封装一个ThreadFactory内部类。
3. 拒绝策略可以简单封装一个RejectedHandler类,当线程数已达maxPoolSize且taskQueue满时拒绝添加新的任务。
4. 封装一个runTask()方法。在方法中需要不断地利用getTask()方法来从taskQueue中获取任务并执行。一个线程执行完任务就会销毁,为了防止频繁地创建和销毁线程,这里需要用while()循环不断getTask()并执行。
5. 关闭并销毁线程池。
二、具体代码实现
package threadpooldemo;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.LinkedBlockingQueue;
import java.util.concurrent.RejectedExecutionException;
import java.util.concurrent.ThreadFactory;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicInteger;
import java.util.concurrent.atomic.AtomicLong;
public class MyThreadPool {
final static int MAX_QUEUE_SIZE = 100; //默认的最大任务队列长度
private volatile long corePoolSize; //加volatile是为了后面支持set扩展
private volatile  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 595
595

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









