




 本文详细解释了Flink中的背压机制,包括数据传输过程中的缓冲区管理、本地与远程交换的区别,以及背压如何影响任务间的吞吐量。通过实验展示了背压如何确保管道中的任务按最慢环节的速度运行。
本文详细解释了Flink中的背压机制,包括数据传输过程中的缓冲区管理、本地与远程交换的区别,以及背压如何影响任务间的吞吐量。通过实验展示了背压如何确保管道中的任务按最慢环节的速度运行。
Flink 运行时的构建块是操作符和流。每个操作符都在使用中间流,通过对它们进行转换, 产生新的流。描述网络机制的最佳类比是 Flink 使用具有有限容量的有效分布式阻塞队列。与 Java 连接线程的常规阻塞队列一样,一旦队列的缓冲区耗尽(有界容量),处理速度较慢的接收器就会降低发送器发送数据的速度。
可以看一下这个外国博主的描述被压机制图片,
-
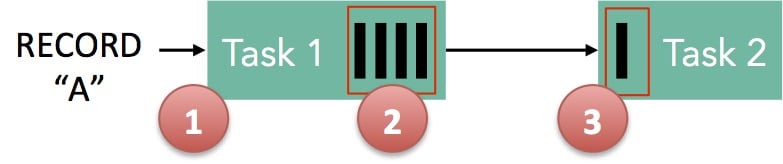
记录“A”进入Flink,被Task 1处理。
-
记录被序列化到缓冲区中,
-
这个缓冲区被传送到任务 2,然后从缓冲区读回记录。
为了使记录通过 Flink 进行处理,需要有可用的缓冲区。
在 Flink 中,这些分布式队列是逻辑流,有界容量是通过每个生产和消费流的托管缓冲池实现的。缓冲池是一组缓冲区,在它们被消费后会被重新回收。
总体思路很简单:从池中取出一个缓冲区,将数据放入缓冲区中,在数据被消费后,将缓冲区放回池中,由此实现缓冲区的利用高效性和防止因为不断创建缓冲池导致的时间消耗。
这些池的大小在运行时动态变化。
网络堆栈中的内存缓冲区量(= 队列容量)定义了系统在不同发送器/接收器速度下可以执行的缓冲量。Flink 保证总是有足够的缓冲区来进行*一些进程*,但是这个进程的速度是由用户程序和可用内存量决定的。
更多的内存意味着系统可以简单地缓冲掉某些瞬态背压(短周期、短 GC)。更少的内存意味着对背压的更直接的反应。
以上面的简单示例为例:任务 1 在输出端有一个与之关联的缓冲池,在其输入端有任务 2。如果有一个缓冲区可用于序列化“A”,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 335
335

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









