







干货|两个常用的 Python 模块
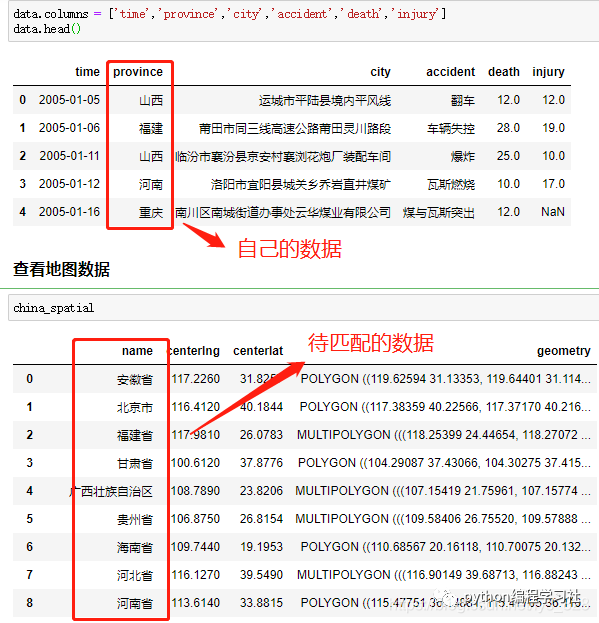
在日常开发工作中,经常会遇到这样的一个问题:要对数据中的某个字段进行匹配,但这个字段有可能会有微小的差异。比如同样是招聘岗位的数据,里面省份一栏有的写“广西”,有的写“广西壮族自治区”,甚至还有写“广西省”……为此不得不增加许多代码来处理这些情况。
今天跟大家分享FuzzyWuzzy一个简单易用的模糊字符串匹配工具包。让你轻松解决烦恼的匹配问题!
前言
在处理数据的过程中,难免会遇到下面类似的场景,自己手里头获得的是简化版的数据字段,但是要比对的或者要合并的却是完整版的数据(有时候也会反过来)
FuzzyWuzzy库介绍
FuzzyWuzzy 是一个简单易用的模糊字符串匹配工具包。它依据 Levenshtein Distance 算法,计算两个序列之间的差异。
Levenshtein Distance 算法,又叫 Edit Distance 算法,是指两个字符串之间,由一个转成另一个所需的最少编辑操作次数。许可的编辑操作包括将一个字符替换成另一个字符,插入一个字符,删除一个字符。一般来说,编辑距离越小,两个串的相似度越大。
这里使用的是Anaconda下的jupyter notebook编程环境,因此在Anaconda的命令行中输入一下指令进行第三方库安装。
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple FuzzyWuzzy1 fuzz模块
1 fuzz模块
该模块下主要介绍四个函数(方法),分别为:简单匹配(Ratio)、非完全匹配(Partial Ratio)、忽略顺序匹配(Token Sort Ratio)和去重子集匹配(Token Set Ratio)
_注意:如果直接导入这个模块的话,系统会提示__warning,_当然这不代表报错,程序依旧可以运行(使用的默认算法,执行速度较慢),可以按照系统的提示安装__python-Levenshtein__库进行辅助,这有利于提高计算的速度。

1.1 简单匹配(Ratio)
简单的了解一下就行,这个不怎么精确,也不常用
fuzz.ratio("河南省", "河南省")
output
100
f 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1296
1296

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











