




 因子分析是一种统计方法,用于从高维数据中提取少数几个综合因子,以简化数据和探索变量间的关系。它基于主成分分析但更注重因子的可解释性。在Python中,可以使用factor_analyzer库进行因子分析,包括KMO检验、碎石图和因子旋转等步骤,以确定合适的因子个数并解释因子含义。
因子分析是一种统计方法,用于从高维数据中提取少数几个综合因子,以简化数据和探索变量间的关系。它基于主成分分析但更注重因子的可解释性。在Python中,可以使用factor_analyzer库进行因子分析,包括KMO检验、碎石图和因子旋转等步骤,以确定合适的因子个数并解释因子含义。
什么是因子分析
因子分析是通过研究变量间的相关系数矩阵,把这些变量间错综复杂的关系归结成少数几个综合因子,并据此对变量进行分类的一种统计分析方法。由于归结出的因子个数少于原始变量的个数,但是它们又包含原始变量的信息,所以,这一分析过程也称为降维。
因子分析与主成分分析的关系
主成分分析直接对因子进行降维,无法很好进行后续的解释,因而对其进行扩展:不仅注意变量之间是否相关,而且考虑相关关系的强弱,使得提取出来的公因子不仅起到降维的作用,而且能够被很好的解释,该方法就是因子分析。因子分析是在主成分分析法的基础上进行因子旋转,使得因子载荷重新分布,从而使得新因子能够很好的解释之前的因子。
为什么使用因子分析
因子分析主要包含以下三个原因:
- 探索结构:在变量之间存在高度相关性的时候我们希望用较少的因子来概括其信息;
- 简化数据:把原始变量转化为因子得分后,使用因子得分进行其他分析,比如聚类分析、回归分析等;
- 综合评价:通过每个因子得分计算出综合得分,对分析对象进行综合评价。
因子分析就是将原始变量转变为新的因子,这些因子之间的相关性较低,而因子内部的变量相关程度较高。
因子分析的步骤
因子分析的一般步骤:
- 判断数据是否适合因子分析;
- 构造因子变量;
- 利用因子旋转方法使得因子更具有实际意义;
- 计算每个因子得分;
- 确定因子个数
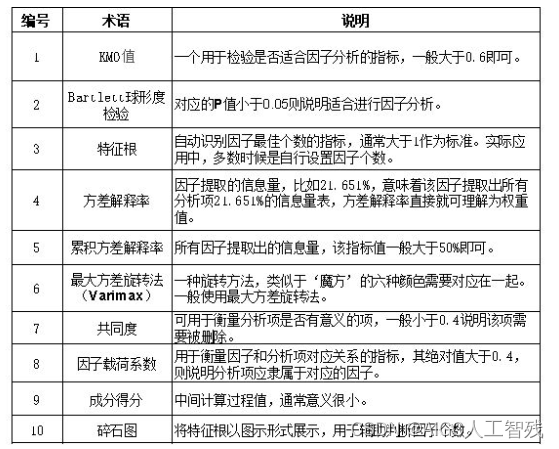
因子分析的变量要求是连续变量,分类变量不适合直接进行因子分析;建议个案个数是变量个数的5倍以上,这只是一个参考依据,并不是绝对的标准;KMO检验统计量在0.5以下,不适合因子分析,在0.7以上时,数据较适合因子分析,在0.8以上时,说明数据极其适合因子分析。
提取因子个数的标准
- 初始特征值大于1的因子个数;
- 累积方差贡献率达到一定水平(60%)的因子个数;
- 碎石图中处于较陡峭曲线上所对应的因子个数;
- 依据对研究事物的理解而指定因子个数;
python实例
- 导入相关包和数据
# 导入相关包和数据
import numpy as np
import pandas as pd
from factor_analyzer import FactorAnalyzer
from sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer()
import matplotlib.pyplot as plt
import matplotlib
import warnings
warnings.filterwarnings("ignore")
%matplotlib inline
plt.rcParams['font.sans-serif']=['Arial Unicode MS']
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 744
744

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











