



 本文深入探讨了Go语言内存管理中的mcache设计,分析了为何选择将其与逻辑处理器P关联而非系统线程M。通过对比TCMalloc,指出在Go的GMP调度模型下,由于I/O操作可能导致M与P解绑,mcache绑定到P能更好地保证内存缓存的有效复用,从而提高性能。
本文深入探讨了Go语言内存管理中的mcache设计,分析了为何选择将其与逻辑处理器P关联而非系统线程M。通过对比TCMalloc,指出在Go的GMP调度模型下,由于I/O操作可能导致M与P解绑,mcache绑定到P能更好地保证内存缓存的有效复用,从而提高性能。
导读
本文基于Go源码版本1.16、64位Linux平台、1Page=8KB、本文的内存特指虚拟内存今天我们开始进入《Go语言轻松系列》第二章「内存与垃圾回收」第二部分「Go语言内存管理」。

关于「内存与垃圾回收」章节,会从如下三大部分展开:
读前知识储备(已完结,点击下方链接查看)
Go语言内存管理(当前部分)
Go语言垃圾回收原理(未开始)
第一部分「读前知识储备」已经完结,为了更好理解本文大家可以点击历史链接进行查看或复习。
目录
关于讲解「Go语言内存管理」部分我的思路如下:
介绍整体架构
介绍架构设计中一个很有意思的地方
通过介绍Go内存管理中的关键结构
mspan,带出page、mspan、object、sizeclass、spanclass、heaparena、chunk的概念接着介绍堆内存、栈内存的分配
回顾和总结
通过这个思路拆解的目录:
-
mcachemcentralmheap
为什么线程缓存
mcache是被逻辑处理器p持有,而不是系统线程m?(本篇内容)Go内存管理单元mspan
page的概念mspan的概念object的概念sizeclass的概念spanclass的概念heaparena的概念chunk的概念
Go堆内存的分配
微对象分配
小对象分配
大对象分配
Go栈内存的分配
栈内存分配时机
小于32KB的栈分配
大于等于32KB的栈分配
在学习Go语言内存管理部分过程中,发现了一个很有意思的问题,今天就借助这篇文章:
把这个问题也抛给大家,建议大家看见这个问题后,可以先自己思考一番🤔再读下文
进一步强化大家对Go内存架构的理解
开始本篇文章之前,我们快速回顾下「Go内存架构」相关的核心知识点,温故知新。
回顾「TCMalloc内存管理架构」
先来简单回顾下「TCMalloc内存管理架构」。详细讲解可查看之前的文章《18张图解密新时代内存分配器TCMalloc》
痛点
多线程时代 ---> 线程共享内存 ---> 线程申请内存会产生竞争 ---> 竞争加锁 ---> 加锁影响性能。
解法
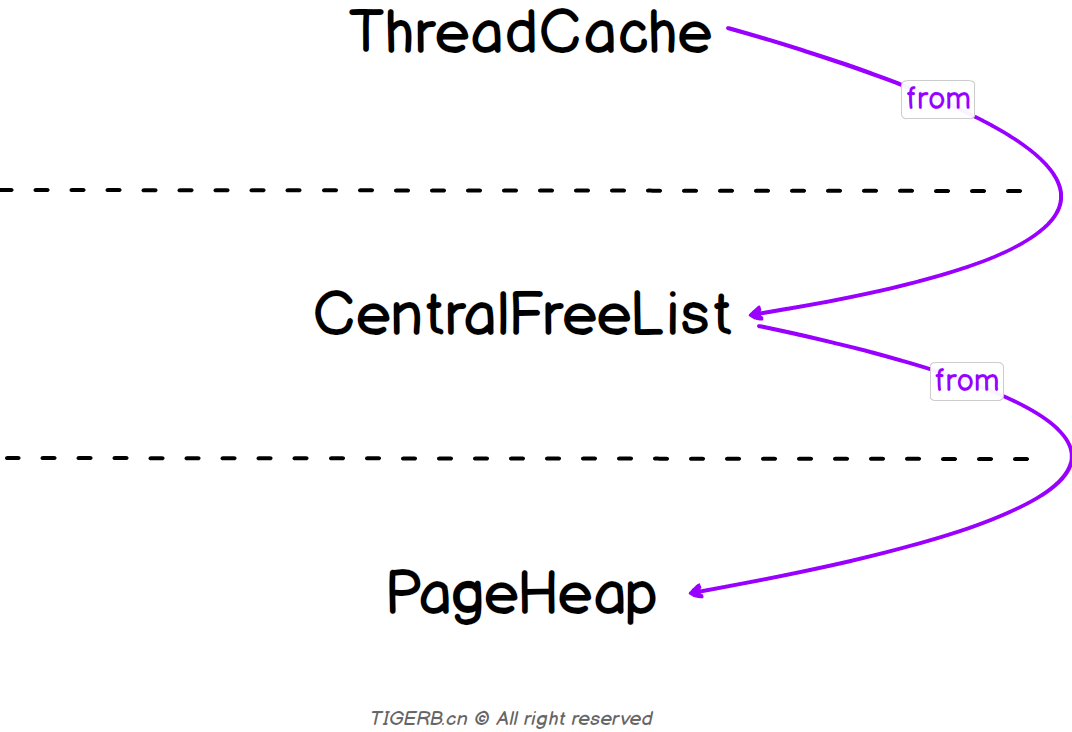
每个线程上增加内存缓存ThreadCache。
简易架构图如下:
回顾「Go内存管理架构」
接着简单回顾下「Go内存管理架构」。详细讲解可查看之前的文章《浅析Go内存管理架构》
痛点
同上。
解法
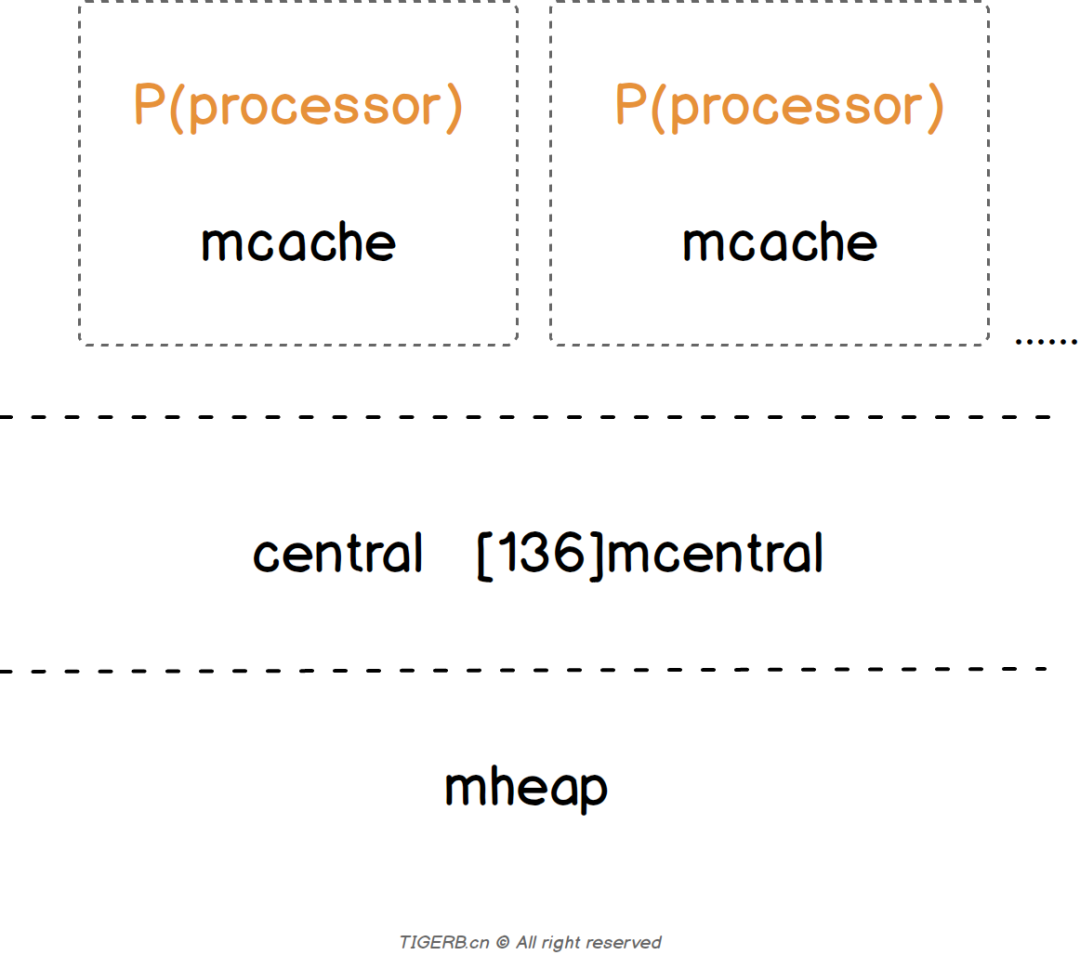
同上,基于「TCMalloc」实现。
简易架构图如下:
有趣的问题
关于这个有趣的问题,通过上述的内容,细心的朋友可能已经发现了,具体问题如下:
为什么Go的内存管理器的线程缓存是
mcache被逻辑处理器p持有,而并不是被真正的系统线程m持有?
个人思考时间
是不是很有意思,关于这个问题。对面的你不妨先停下来思考几分钟:
为什么?
解密
按照原TCMalloc的设计思想,线程缓存mcache确实应该被绑定到系统线程M上。
那么我们就假设:按照原TCMalloc的思想,把mcache绑定系统线程M上。接着我们只需要看看这个假设有什么问题即可。
要论证这个假设需要先来简单看看「Go的调度模型GMP」。
Go的调度模型GMP
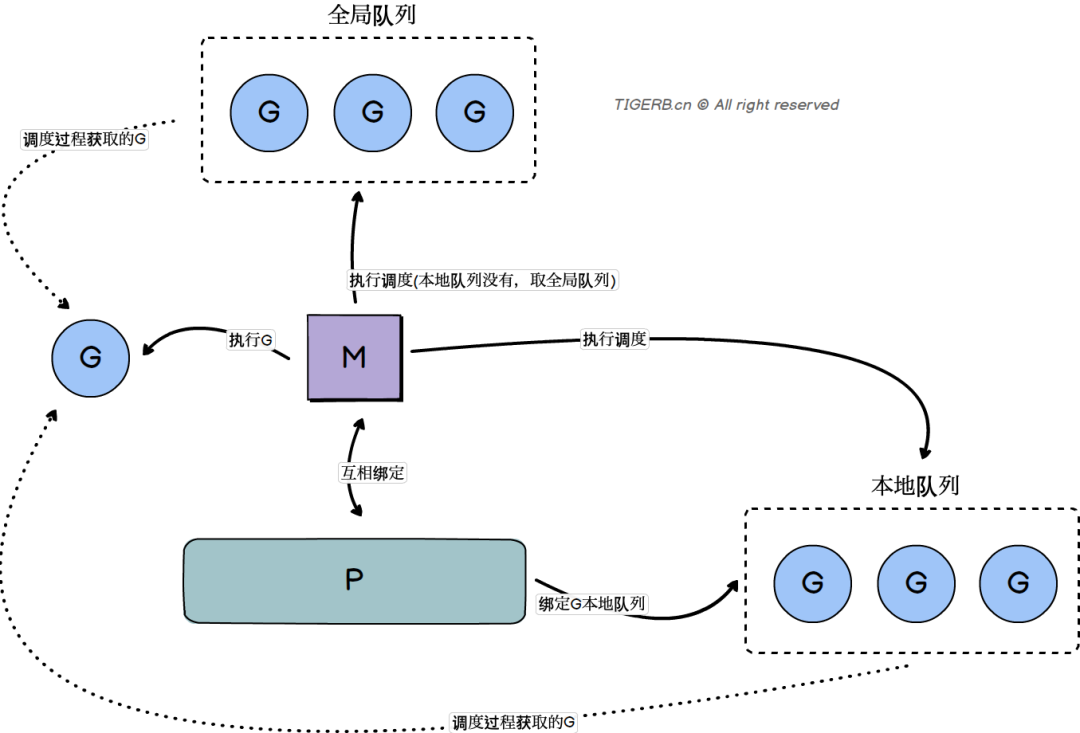
首先直接上入门级「Go的调度模型GMP」架构图:
关于「Go的调度模型GMP」的原理,大家应该看了无数文章,我这里就不细说了,如果还有不熟悉可以自行搜索哈。
这里简单提下关于GMP的入门级知识哈,其实GMP对应的只是Go语言自身的逻辑结构而已,含义如下:
M:代表结构体m,全称Machine,这个结构体的核心是会和真正的系统线程thread绑定。G:代表结构体g,全称Goroutine,这个结构体就是大家熟知的协程,简单理解其实就是这个结构体绑定了一个有着被并发执行需求的函数。P:代表结构体p,全称Processor,这个结构体表示逻辑处理器,通过这个结构体和计算机的逻辑处理器建立对应关系,P的数量通常和计算机的逻辑处理器数量一致通过runtime.GOMAXPROCS(runtime.NumCPU())设置。
三者的简单职责以及关系:
P
和一个
M互相绑定维护了一个可执行
G的队列
M
和一个
P互相绑定负责执行
G的调度,通过调度当前M绑定的P的G队列、以及全局G队列,达到G可被并发执行的目的。负责执行
P调度过来的当前G
此阶段结论:以上的调度过程P的数量和M的数量是一一对应的,所以把mcache绑定系统线程M上和P看起来都可以。所以我们上面的假设「按照原TCMalloc的思想,把mcache绑定系统线程M上」目前看起来确实也没啥问题。
我们继续往下看,一种特殊的场景M会和P解绑。
I/O操作的系统调用
当G执行一个I/O操作的系统调用时,比如read、write,因为系统调用过程中的阻塞(原因:内核往用户态拷贝数据的过程产生的阻塞,不在本文范畴,后续文章详解)问题,会发生如下操作:
当前
G(我们命名为g1)的M(我们命名为m1)和当前的P(我们命名为p1)解绑上面的
p1会绑定一个其他的M(m2)m1执行完成系统调用之后会被放到闲置M链表里
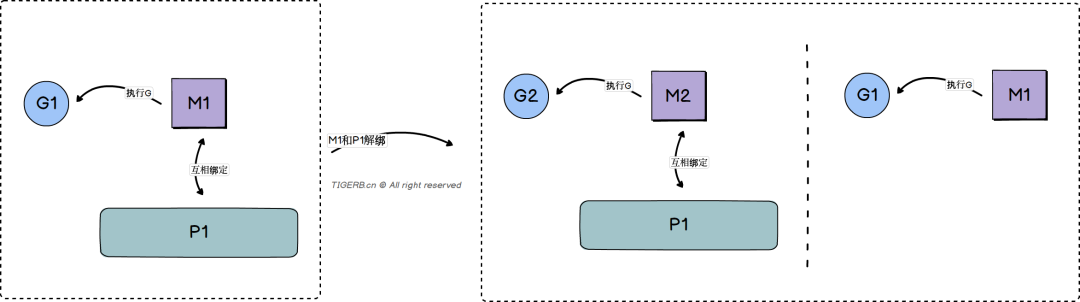
由于m1会被放进闲置链表,这是不是就意味着m1上的mcache当前就不能被复用,所以这样看起来是不是mcache绑定到p1上更合适。
结论: 由于M可能因为执行一个I/O操作的系统调用被阻塞(原因:内核往用户态拷贝数据的过程产生的阻塞),M会和当前P解绑,当前P绑定其他闲置或者新的M,之前的M结束系统调用会被放进闲置M链表。之前的M的mcache就不会得到有效的复用,反而mcache绑定到P上就不存在这个问题,所以mcache绑定到P上更合适。
源码论证
通过Go的源码进一步证明我们的结论。
代码位置:
src/runtime/proc.go::3813函数名称:
func exitsyscall0(gp *g)
源码如下:
// Go版本1.6
// 退出系统调用的代码逻辑
// 代码位置
// src/runtime/proc.go::3813
func exitsyscall0(gp *g) {
_g_ := getg()
casgstatus(gp, _Gsyscall, _Grunnable) // 把执行系统调用的g从系统调用状态改为可执行
dropg()
lock(&sched.lock)
var _p_ *p
if schedEnabled(_g_) {
_p_ = pidleget() // 找空闲的p
}
if _p_ == nil {
globrunqput(gp) // 找不到空闲的p 则放进全局队列
} else if atomic.Load(&sched.sysmonwait) != 0 {
atomic.Store(&sched.sysmonwait, 0)
notewakeup(&sched.sysmonnote)
}
unlock(&sched.lock)
if _p_ != nil {
acquirep(_p_)
execute(gp, false) // 执行当前因系统调用阻塞的g
}
if _g_.m.lockedg != 0 {
stoplockedm()
execute(gp, false) // 执行当前因系统调用阻塞的g
}
stopm() // 停止m,并放到调度器的m闲置链表
schedule() // 触发调度
}Go轻松进阶系列 更多文章
点击下方关注我的公众号



















 1455
1455

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









