




 本文深入探讨Redis的集合(set)和有序集合(zset)数据类型。set类似于Java的HashSet,提供数据唯一性,而zset结合了HashSet和SortedSet特性,支持按分数排序。文章详细介绍了这两种数据结构的内部实现、操作示例以及跳跃列表的原理。
本文深入探讨Redis的集合(set)和有序集合(zset)数据类型。set类似于Java的HashSet,提供数据唯一性,而zset结合了HashSet和SortedSet特性,支持按分数排序。文章详细介绍了这两种数据结构的内部实现、操作示例以及跳跃列表的原理。
这一节我们介绍Redis的集合(set)和有序集合(zset)两种数据类型
一、set(集合)
1、Redis的set相当于java里面的HashSet,他的内部的键值是无序的,唯一的。内部实现是一个所有value都是一个值null的字典结构。
2、当集合中最后一个元素被删除后,数据结构被自动删除,内存被回收
3、set结构具有去重功能,可以保证数据的唯一性。
com.xiaozhameng.aliyun:6379> sadd person zhameng
(integer) 1
com.xiaozhameng.aliyun:6379> sadd person zhameng
(integer) 0
com.xiaozhameng.aliyun:6379> sadd person alier
(integer) 1
com.xiaozhameng.aliyun:6379> smembers person
1) "zhameng"
2) "alier"
com.xiaozhameng.aliyun:6379>
二、zset(有序集合)
1、zset 是Redis非常有特色的数据结构,它类似java里面的HashSet和SortedSet的结合体。一方面它是一个set,保证其value的唯一性,另一方面,它可以给每个value赋予一个score,代表这个value的排序权中。
2、zset的内部实现是跳表(也叫做跳跃列表)
3、zset中最后一个value被删除后,数据结构被自动清空,内存被回收。
4、举个栗子,比如我们有一个图书排名的集合,使用zset存储,用score来指定排名的权重
com.xiaozhameng.aliyun:6379> zadd books 9.0 "think in java"
(integer) 1
com.xiaozhameng.aliyun:6379> zadd books 8.9 "java concurrency"
(integer) 1
com.xiaozhameng.aliyun:6379> zadd books 8.2 "java cookbook"
(integer) 1
com.xiaozhameng.aliyun:6379> zadd books 8.6 "java vm"
(integer) 1
com.xiaozhameng.aliyun:6379> zrange books 0 -1
1) "java cookbook"
2) "java vm"
3) "java concurrency"
4) "think in java"
com.xiaozhameng.aliyun:6379> zrevrange books 0 -1
1) "think in java"
2) "java concurrency"
3) "java vm"
4) "java cookbook"
com.xiaozhameng.aliyun:6379> zcard books
(integer) 4
com.xiaozhameng.aliyun:6379> zscore books "java concurrency"
"8.9000000000000004"
com.xiaozhameng.aliyun:6379>
三、跳跃列表
1、zset内部的排序功能是基于跳跃列表的数据结构来实现的,跳表的实现相对于前面几种数据结构的实现略微复杂,我们首先看一下Redis里面每一个kv(key/value)块对应的结构,如下面代码中的zslnode,kv header 也是这个结构,不过value字段都是NULL值,score则是Double.MIN_VALUE,用来垫底。
struct zslnode {
string value;
double score;
zslnode*[] forwards;
zslnode* backward;
}
struct zsl {
zslnode* header;
int maxLevel ;
map<string,zslnode*> ht;
}
2、kv之间使用指针串起来形成了双向链表结构,他们是有序排列的。不同kv层高度可能不一样,层约高kv约少,同一层的kv会使用指针串起来。每一层的元素遍历都是从kv header 出发。kv之间使用双向链表结构,且是有序(从小到大)存储的。Redis的跳表结构总共有64层,如下的示意图中只画了4层
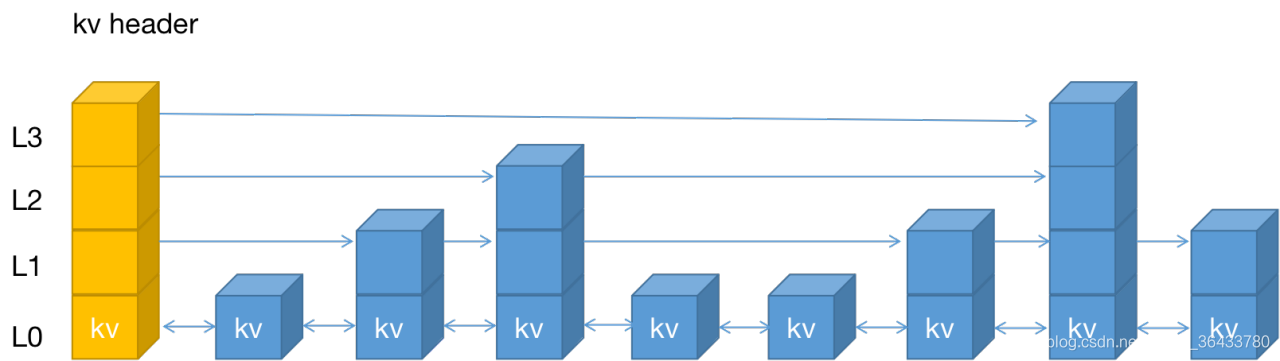
3、查找过程
如果跳表只有一层,要插入,删除操作时,需要定位到响应的节点(最后一个比目标目标元素小的元素,或者说第一个比目标元素大的元素),这样需要遍历整个链表,上面示意图中的L0层,时间复杂度将是O(n),也许你想到了二分查找,但是这里采用的是链表结构,二分查找算法需要有序的数组结构。
跳跃表有了多层结构结构之后,这个查找算法的时间复杂度就会降低到O(lg(n))。
如上图所示,我们要定位其中的某个元素,需要从header的最高层开始遍历,找到第一个节点(比目标元素小的元素),然后降一层(所谓降一层就是根据指针往下查找元素,注意对比图中的数据,降一层的数据元素跟当前节点的元素是相同的)再进行遍历。这种抽取层的遍历的过程,减少了元素遍历的次数。如上,如果在L0层进行遍历查找最后一个元素,最坏需要查找n次,但是如果从L3开始遍历查找,则每一层遍历的元素为下一层元素的一半(实际上,跳表结构中这里的上下层数据关系并不是严格的2:1的关系),大大降低了查找的次数,提高了效率。
4、新增一个元素
上面提到查找过程的时候,我们提到上下层元素之间的个数并不是严格的2:1,这是因为如果按照严格的2:1比例,当跳表中新增一个元素时,就需要调整后续元素的层,这不是我们愿意看到的。实际上,redis在新增元素的时候,会为每一个元素随机出一个层,比如随机出来的层是2,那就会把这个元素插入到第1层到第2层的链表中,我们看一下这个过程,假设当前的跳表结构如果所示,我们要往该跳表中新增一个元素8,通过随机函数计算出来的随机层为3
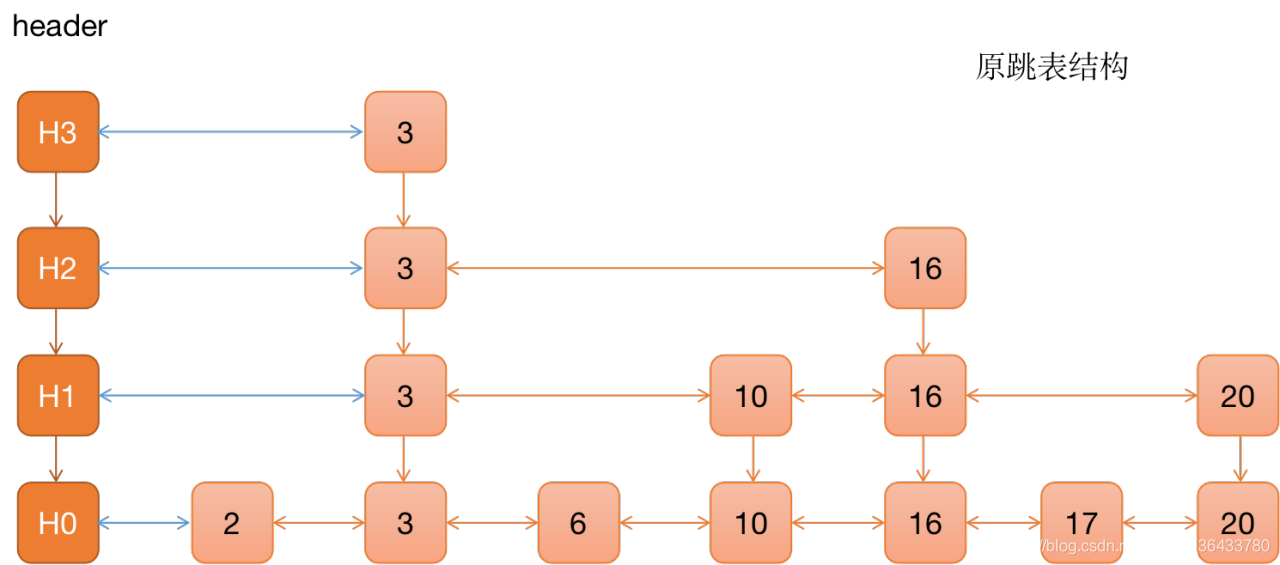
从头指针开始,一层一层遍历找到要插入的未知(图中0层元素6的后面),再根据计算出来的随机层数,将该元素插入到0层,1层,2层这三层中。
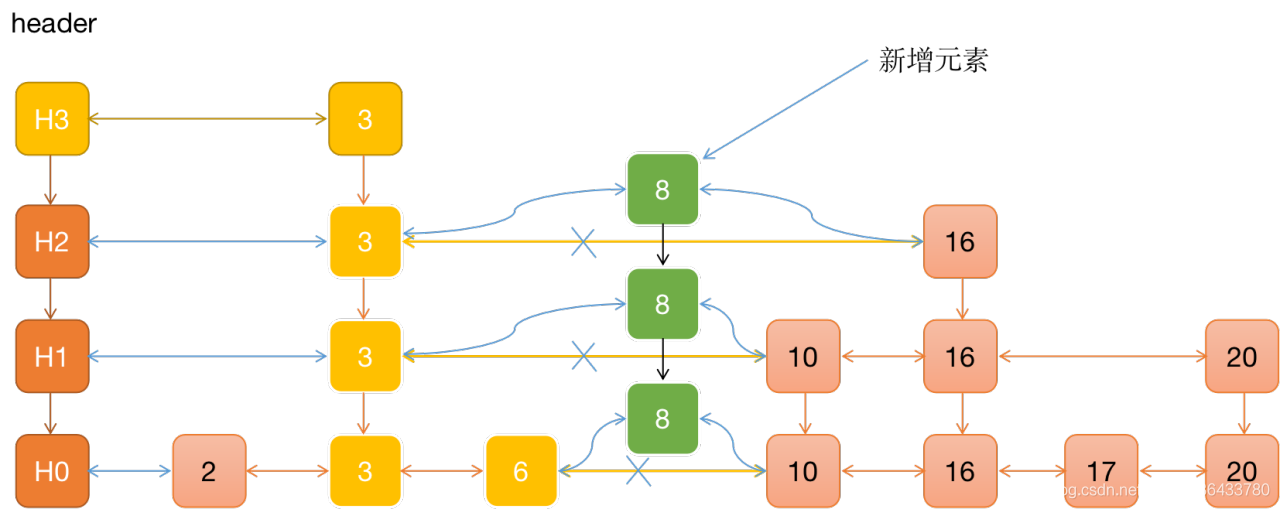
5、我们看一下redis跳表结构中的随机层数,对于每一个新插入的节点,都需要调用一个随机算法给它分配一个合理的层数,一般理解上,50%的概率会被分配到Level1,25%的概率会被分配到Level2,12.5%的概率会被分配到level3,依次类推,2^-63的概率会被分配到最顶层,因为这里每一层晋升的概率是50%。不过redis源码中的晋升的概率只有25%,跳表更加扁平化,在单个层上遍历的节点会稍微多一点,所以,对于redis而言,从顶层往下遍历的时候会非常浪费,所以redis跳表会记录一下当前的最高层数maxLevel,遍历时,从这个最高层maxLevel开始遍历,这样性能就会提高很多。
6、关于score
可能细心的小伙伴发现了,既然使用score值来进行排序,那么当score值都一样的情况下会怎么样呢,查询的时间复杂度将退化到O(n),不过别担心,redis肯定早就考虑到这一点了,redis不仅仅通过score值来进行排序,还会对value值进行比较(字符串比较)
7、元素排名是怎么计算出来的
zset可以获取元素的rank,那你有没有考虑过redis中的rank是怎么计算出来的呢?redis在skiplist的forward指针做了优化,每一个指正都加了一个span属性,span标识从前一个节点,沿着当前层跳转到当前节点时中间会跳过多少个节点,redis在插入,删除操作是会更新span的值,这样我们要计算一个元素的排名时,只需要将搜索路径经过的所有及诶单的span进行叠加就可以计算出来rank值
三、总结
好了,关于redis的几种常用数据类型我们已经介绍完了,zset结构使用到的跳表是一种非常高效的动态数据结构,在java中,我们知道HashMap 中使用了的红黑树是一种稳定高效的动态数据结构,跳表的实现比起红黑树要简单,但是性能上并不必红黑树差。其实,redis中不仅仅就这5中基本的数据类型,随着Redis5.0的发布,还引入了listpack数据结构,它是对ziplist的改进版,在存储结构上会更加紧凑,此外redis内部还有很多有趣又高效的数据结构值得借鉴,基于这些数据结构我们能实现很多高效的功能。后续有时间的时候,我们会持续挖掘!
因为个人水平有限,如果小伙伴在查阅过程中有什么问题,欢迎批评指正!

















 3278
3278

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









