







 本文探讨了Redis中的两种高效数据结构ziplist和skiplist,重点介绍了ziplist的压缩链表原理及其内存优化,以及skiplist的多层链表特性。讨论了如何根据数据增长和性能需求选择合适的结构,并提到了ziplist可能转为dict的动态调整策略。
本文探讨了Redis中的两种高效数据结构ziplist和skiplist,重点介绍了ziplist的压缩链表原理及其内存优化,以及skiplist的多层链表特性。讨论了如何根据数据增长和性能需求选择合适的结构,并提到了ziplist可能转为dict的动态调整策略。
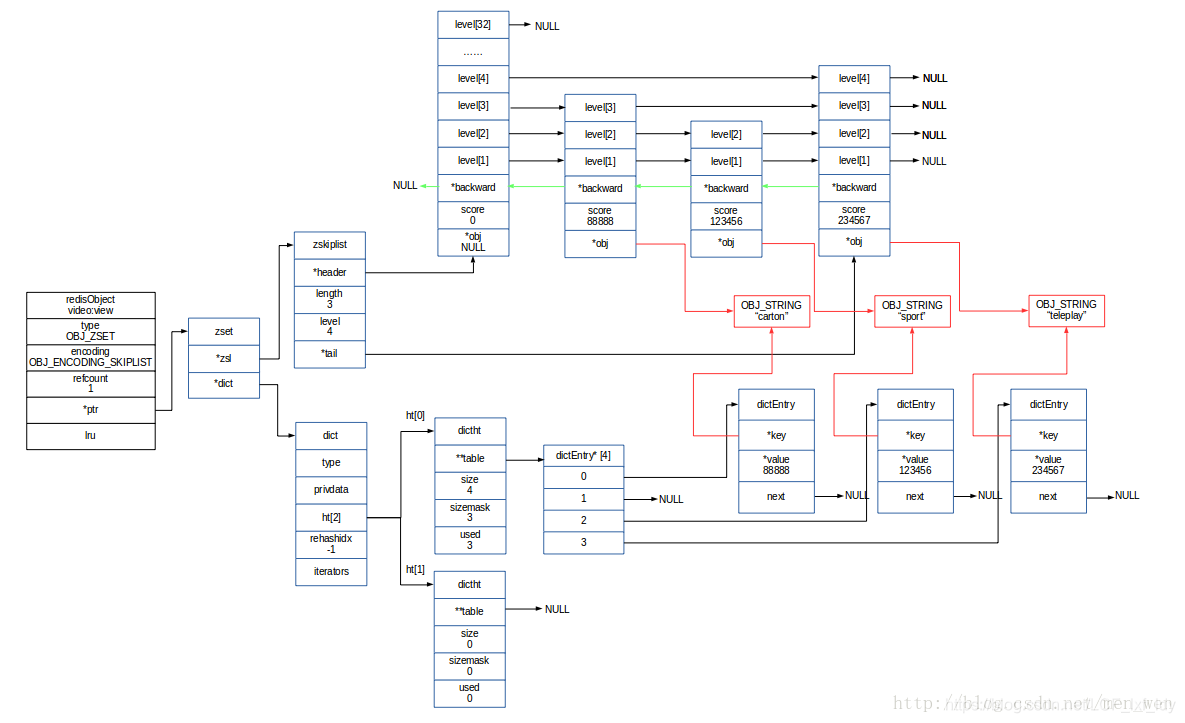
sortedset的两种编码分别是ziplist和skiplist 【根据情况选择具体使用哪一种编码】
1. ziplist
我们从 添加一个有序元素 zadd key score member 命令上就可以发现 key,score,member是同时设置的,score和member是同时作为value被存在list里面,member放在第一个节点,score放在第二个节点。ziplist内的集合元素按score从小到大排序,score较小的排在表头位置

ziplist【压缩链表】是一个经过特殊编码的双向链表,主要是为了提高存储效率,能以O(1)的时间复杂度在表的两端提供push和pop操作
ziplist为了节省内存,提高存储效率,对于值的存储采用了变长的编码方式,大概意思是说,对于大的整数,就多用一些字节来存储,而对于小的整数,就少用一些字节来存储。
各个部分在内存上是连续的:
zlbytes: 存储一个无符号整数,固定四个字节长度(32bit),用于存储压缩列表所占用的字节(也包括<zlbytes>本身占用的4个字节),当重新分配内存的时候使用,不需要遍历整个列表来计算内存大小。
zltail: 存储一个无符号整数,固定四个字节长度(32bit),表示ziplist表中最后一项(entry)在ziplist中的偏移字节数。<zltail>的存在,使得我们可以很方便地找到最后一项(不用遍历整个ziplist),从而可以在ziplist尾端快速地执行push或pop操作。
zllen: 压缩列表包含的节点个数,固定两个字节长度(16bit), 表示ziplist中数据项(entry)的个数。由于zllen字段只有16bit,所以可以表达的最大值为2^16-1。
注意点:如果ziplist中数据项个数超过了16bit能表达的最大值,ziplist仍然可以表示。ziplist是如何做到的?
如果<zllen>小于等于2^16-2(也就是不等于2^16-1),那么<zllen>就表示ziplist中数据项的个数;否则,也就是<zllen>等于16bit全为1的情况,那么<zllen>就不表示数据项个数了,这时候要想知道ziplist中数据项总数,那么必须对ziplist从头到尾遍历各个数据项,才能计数出来。
entry,表示真正存放数据的数据项,长度不定。一个数据项(entry)也有它自己的内部结构。
zlend, ziplist最后1个字节,值固定等于255,其是一个结束标记。
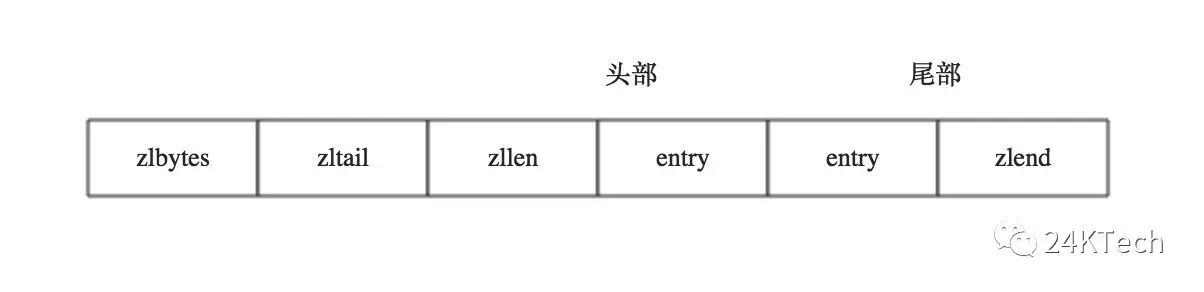

总结:压缩列表的原理,ziplist并不是对数据利用某种算法进行压缩,而是将数据按照一定规则编码在一块连续的内存区域,目的是节省内存,这种结构并不擅长做修改操作。一旦数据发生改动,就会引发内存realloc,可能导致内存拷贝。
2. 当随着数据的插入,hash底层的这个ziplist就可能会转成dict?【配置项灵活】
变更的目的是为了提高性能【避免:内存的realloc和查找效率的低效】

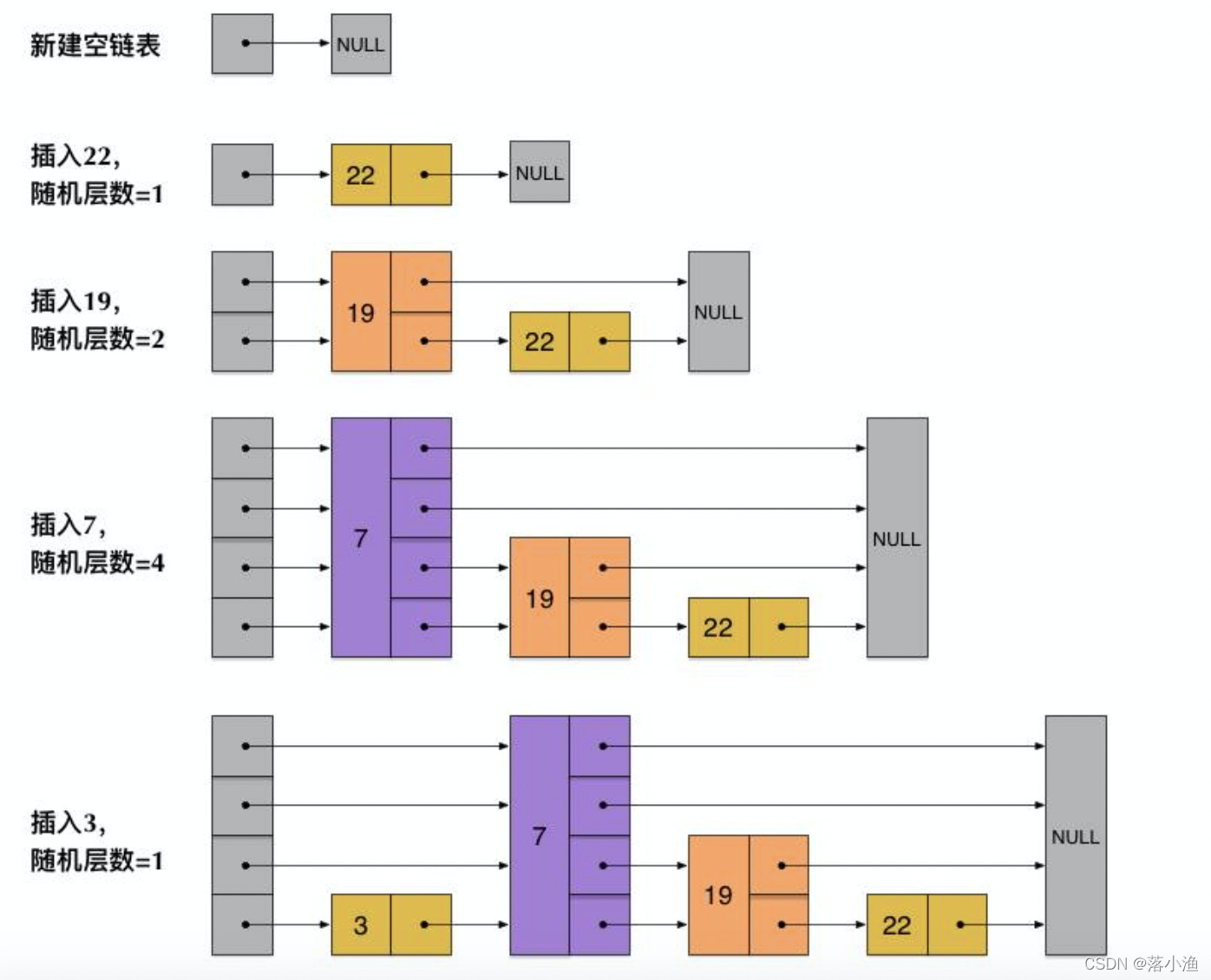
skipList:Redis数据结构之skiplist(续) - 三石雨 - 博客园
多层链表。每个节点随机出一个层数


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









