




 本文探讨了数据补全的方法,从传统的填充方式如平均值、中位数,到使用随机森林,再到深度学习的GAIN(Generative Adversarial Networks for Imputation of Missing Values)。GAIN利用生成器和判别器的对抗过程来填补缺失数据,尤其在医疗数据等领域有广泛应用。通过优化目标和算法流程,GAIN能够生成接近真实数据分布的补全值。
本文探讨了数据补全的方法,从传统的填充方式如平均值、中位数,到使用随机森林,再到深度学习的GAIN(Generative Adversarial Networks for Imputation of Missing Values)。GAIN利用生成器和判别器的对抗过程来填补缺失数据,尤其在医疗数据等领域有广泛应用。通过优化目标和算法流程,GAIN能够生成接近真实数据分布的补全值。
实际中运用机器学习方法完成各种任务时,常常遇到数据缺失的问题 ,如果某特征缺失的样本占总数极大,我们可能就直接舍弃了;因为如果作为特征加入的话,可能反倒带入噪音,影响最后的结果,但是一般情况下我们会去寻找各种数据补全的方法来完善数据,提高模型效果。
数据分析
拿到数据的第一手肯定要看看具体情况,发现缺失再决定要去填充,那么我们拿到一个数据要怎么去看它的状况呢。首先可以用pandas自带的一些方法去看
比如用df.describe()就可以看到一些平均值、方差基础数学属性。

然后我们是要关注数据缺失与否的状况,data.isnull()可以判断为不为空,所以加上一个求每列空值综合再排序就可以得到特征缺失情况。(默认的排序是从小到大)
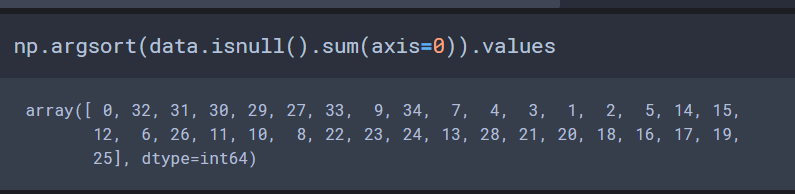
然后我们可以依次把这些这些缺失特征当作标签去进行填充啦。(记得把没有缺失的特征去掉)
但是我们不局限于这种简陋的分析,给大家安利一个特别好用的工具包 pandas-profiling.只需要几行简单的调用就可以生成一个分析报告展示。
from pandas_profiling import ProfileReport
profile = ProfileReport(df, title="Pandas Profiling Report")
profile.to_file("your_report.html")
内容十分丰富,不仅可以看到一个属性值的最大最小,平均等多种信息。
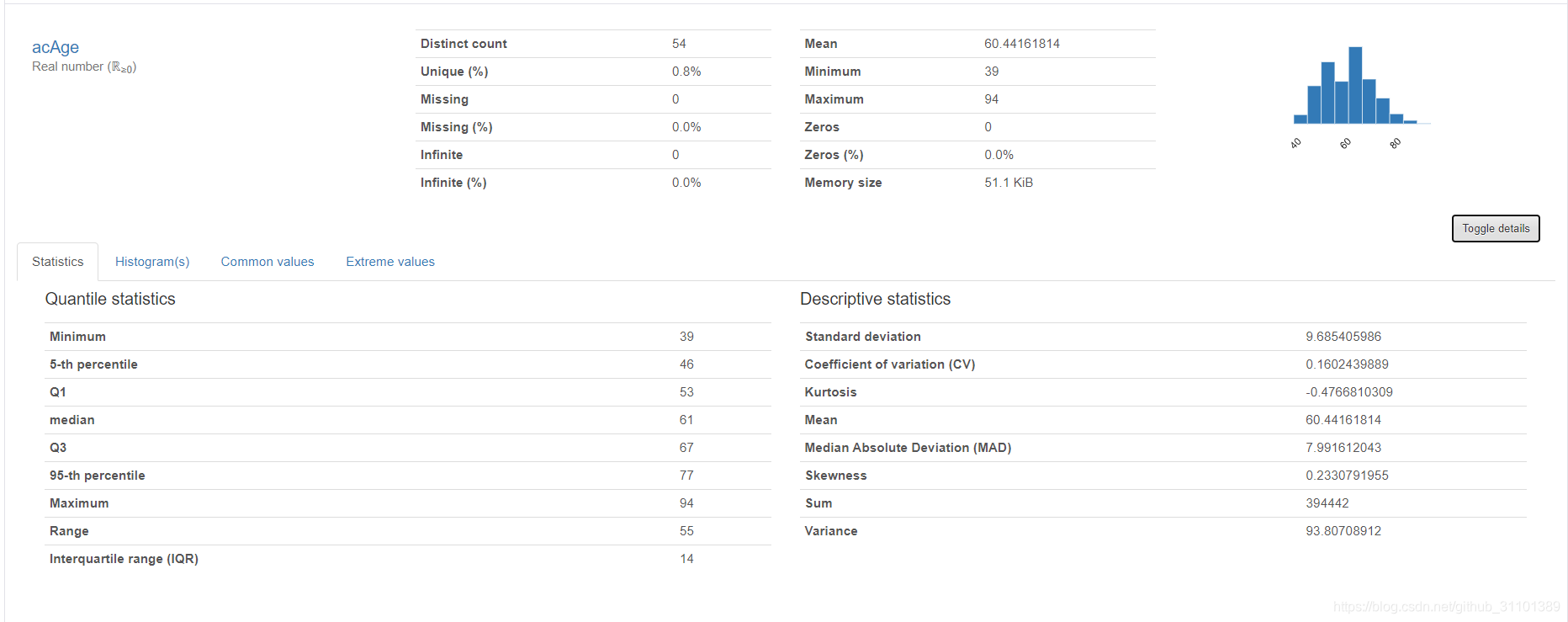
还可以看到特征之间各种相关性评估
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1702
1702

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









