



自动驾驶中的统计相关多任务学习
瓦西姆·阿巴斯1 •穆罕默德·法希尔·汗1 •穆尔塔扎·塔吉1 •阿里夫·马哈茂德2
自摘要驾驶研究是机器学习领域的一个新兴方向。大多数现有方法执行单任务学习,而多任务学习(MTL)由于利用了不同任务之间的共享信息,因此效率更高。然而,MTL具有挑战性,因为不同任务可能具有不同的重要性和变化范围。在本研究中,我们提出了一种基于单张输入图像的端到端深度学习架构,用于统计相关多任务学习(SCMTL)。通过在架构中引入共享层来处理任务间的统计相关性,后续网络则分为不同的分支以应对各任务行为上的差异。训练具有不同范围的任务时,目标函数可能仅收敛于较大数值。为此,我们探索了多种归一化方案,并通过实验观察到逆验证损失加权方案表现最佳。除了估计转向角、制动和加速度外,我们还估计车辆左侧和右侧的车道数量。据我们所知,我们是首个提出端到端深度学习架构来估计此类车道信息的研究。所提出的方案在四个公开可用数据集上进行了评估,包括Comma.ai、Udacity、伯克利深度驾驶和苏利·陈数据集。我们还为自动驾驶研究提出了一个合成数据集GTA‐V。实验结果表明,与当前最先进的方法相比,所提出的方法具有更优的性能。GTA‐V数据集以及四个现有数据集上的车道标注将通过https://cvlab.lums.edu.pk/scmtl/公开发布。
关键词多任务学习 自动驾驶 深度学习
1引言
多任务学习(MTL)是机器学习和深度学习领域中的一个重要范式[29]。MTL利用多个相关任务中包含的共享信息来提高学习效率和预测性能准确率以及学习模型[27]的泛化性能。深度学习模型在优化单个任务[47]时通常能取得良好的性能。然而,相关任务中包含的信息被忽略,而这些信息若以联合方式优化,可能提升所有任务的学习效率。因此,相关任务之间的表示共享能够使深度学习模型在所有任务上更好地泛化[27, 33]。
传统多任务学习方法通常通过利用已经学习到的较简单任务来促进复杂任务的学习[45]。相比之下,本文同时学习多个统计相关任务。所提出的多任务学习方法应用于自动驾驶领域,我们观察到在自动驾驶以及许多其他领域中,经常学习的任务是统计相关的。尽管当前算法通过为每个任务训练单独的模型来分别学习这些任务[4, 21, 26],,但本文提出了一种多任务学习模型以并发地学习一组相关任务。为此,我们提出了一种深度神经网络
&穆尔塔扎·塔吉murtaza.taj@lums.edu.pk瓦西姆·阿巴斯15060009@lums.edu.pk穆罕默德·法希尔·汗 fakhir.khan@lums.edu.pk阿里夫·马哈茂德 arif.mahmood@itu.edu.pk 1拉合尔管理科学大学计算机科学系,巴基斯坦拉合尔2信息技术大学计算机科学系,巴基斯坦拉合尔
123
神经计算与应用https://doi.org/10.1007/s00521‐021‐05941‐8
本文档由funstory.ai的开源PDF翻译库BabelDOCv0.5.10(http://yadt.io)翻译,本仓库正在积极的建设当中,欢迎star和关注。
架构,该架构包含一些共享层以捕捉多任务之间的相关性,然后我们引入独立分支以更高效地学习每个任务的个体独特属性。多任务学习文献已充分证实,当通过训练独立网络来学习相同任务时,尽管这些独立网络总共使用了大量的网络参数[33],预测精度仍会下降。
同时学习多个统计相关任务具有诸多优势,例如减少了需要学习的网络参数数量、提高了精度以及更好的泛化能力[49]。与此同时,这也带来了新的挑战。例如,需要同时学习的不同任务可能具有不同的范围。如果处理不当,某个任务可能会因构成大部分错误而主导优化过程,从而导致其余任务出现学习饥饿[46]。在我们的研究中,通过研究融入深度神经网络目标函数的不同类型的归一化方案来应对这一挑战。我们通过实验发现,采用逆向验证损失权重进行归一化能够产生最佳性能。
自动驾驶本质上是一个多任务问题,因为车辆执行的每个动作都涉及改变多种控制参数(例如,转向、加速度和制动)。为了准确估计这些控制参数的值,必须获取场景的详细信息[28]。然而,白天光照变化和天气变化等自然因素使得这一任务变得困难。端到端深度学习是最广泛使用的方法之一[4, 14, 24],其利用单摄像头视角进行感知。早期的方法[4, 7]尝试仅使用单一前向摄像头的视频流来估计转向角。已有研究通过引入多传感器的额外信息或增加时间或视觉线索以提高精度;然而,这会带来复杂性的增加。相反,我们提出了一种基于深度学习的多任务学习方法,利用单摄像头视角来估计统计相关任务,如转向角、加速度和制动压力。我们提出的统计相关多任务学习(SCMTL)方法在公开可用数据集上的表现优于当前最先进的方法。该方法需要视觉传感器来捕获时空场景数据。由于产生数据量巨大,本地处理这些数据比将其传输至云数据中心更为合适。我们建议采用类似于王等人[39]提出的技术,在边缘侧处理所捕获的数据。
对于路线偏离避免、车道保持辅助和变道操作,当前车道以及数量需要估计自动驾驶车辆左侧和右侧的车道数量 [22, 30, 36, 40]。由于交通干扰、光照条件差异、道路标线不清以及交通拥堵与路边结构共同造成的阴影,该问题变得具有挑战性[6, 16]。在当前工作中,我们还使用所提出的基于深度学习的SCMTL来估计这些任务(见图1)。该技术的一些初步结果最近已在一次会议中发表[1]。当前手稿在理论和实验上均是对先前发表论文的显著扩展。所提出的SCMTL以单张驾驶员视角图像作为输入,能够在不同道路和交通条件下估计当前车道左侧和右侧的车道数量。据我们所知,目前尚无适用于车辆位置和车道计数问题的公开可用数据集。罗伯茨等人也提出了一种包含车道段的数据集[32];然而,该数据集尚未公开。我们手动标注了四个公开可用数据集,并创建了一个新的合成GTA‐V数据集。当前工作的主要贡献包括:
•我们提出了一种基于深度神经网络的多任务学习架构,用于估计多个统计相关的任务,称为统计相关多任务学习(SCMTL)(见图1)。为了同时学习具有不同范围的多任务,我们在目标函数中引入了不同的归一化方案。我们通过实验观察到,逆验证损失加权方案表现出最佳性能。尽管所提出的方法具有通用性,但我们已在自动驾驶领域进行了测试。
•除了主要提出的架构外,还在三种不同的架构上进行了实验,包括“早期分离”(ES)、“带注意力的早期分离”(ESA)和“无分离”(NS)网络。
•使用提出的SCMTL模型,通过前视摄像头的一张图像来估计转向角、制动压力和加速度。同时还对车辆在道路上的定位进行估计,包括车辆左侧和右侧的车道数量,从而揭示道路的总车道数以及车辆所在的当前车道。
使用GTA‐V游戏环境生成了一个新的合成数据集,其中包含驾驶参数(转向角、加速度、制动)和车道定位的标注。这些标注涵盖了包括Comma[34], Udacity[38],BDD[41], SullyChen的[10],在内的基准数据集的车道信息。这些标注和新数据集将很快发布。
神经计算与应用
123
通过https://cvlab.lums.edu.pk/scmtl/公开提供。
所提出的基于深度学习的SCMTL架构在上述五个数据集上进行了评估,并与当前最先进的方法进行了比较。实验结果表明,该提出的方法在估计精度和处理速度方面均优于当前最先进的技术。
本文其余部分组织如下:第2节描述相关工作,第3节详细描述提出的4节讨论实验结果,最后在第5节讨论结论。
2相关工作
现有自动驾驶领域的文献大致可分为单任务和多任务学习方法。
2.1单任务学习(STL)方法
单任务学习(STL)可被视为将原始输入图像映射到单一任务;例如,转向角[4, 5, 26]。这些方法的架构由五个卷积(Conv)层和三个全连接(FC)层组成,使得这些方法适用于实时应用。Chen&Huang[11]提出了一种更简单的网络,仅包含三个卷积层和两个全连接层。该网络可以在较小的数据集上进行训练。此外,强化学习也被提出用于单任务学习以预测转向角 [21]。
Xu等人[42]使用LSTM结合时序信息来预测角速度。 John等人[23]则采用LSTM学习粒子滤波器以预测转向角。 类似地,Chi和Mu[13]提出了两个LSTM子网络, 一个用于特征提取,另一个用于转向角预测。门控循环单元(GRU)[31]和增量网络[14]也被用于估计驾驶控制参数。He等人[44]提出了基于LSTM的网络, 用于估计速度和转向角。这些时序网络被发现对梯度消失[14]具有较强的鲁棒性;然而,LSTM在计算上难以训练。
时空注意力块也被发现对预测转向角[24]有效。 为提高估计精度,[24]提出了端到端深度学习模型, 其中引入了三种利用注意力、时序和全局信息的变体。 另一种利用时序信息的架构是基于LSTM的deep steering[12]。类似地,基于ResNet的三维长短期记忆网络50[19]也被提出用于转向角估计[15]。
FM‐Net被提出通过结合辅助网络(PSPNet、 FlowNet)[20]来学习转向命令。这些方法已取得优异成果;然而,由于引入了多个深度网络,复杂性有所增加。
2.2多任务学习(MTL)方法
使用深度神经网络的多任务学习有助于提高估计性能 [48]。一种近期的MTL方案同时检测物体并预测距离 [8]。Yang等人[44]提出了一种多任务学习模型,使用独立层分别预测转向角和速度。转向角模块的信息被共享给速度模块,从而提高了速度预测的性能。
Chen&Xiao[7]以及Al‐Qizwini等人[3]提出了混合方法,利用卷积神经网络提取车道和物体距离等可行驶性指标,并进一步用于提取车辆控制参数。
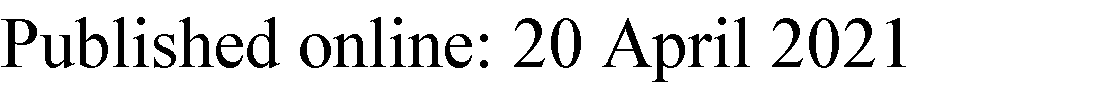
神经计算与应用
123
例如转向角和速度。类似地,李奥等人[28]通过建模在环境刺激下同时启动的生物可及性竞争过程,对减速和制动进行了建模。同样,基于生物信号的驾驶行为也通过多任务学习[2]进行监测。除了估计控制参数外,多任务学习还被用于估计多种与场景相关的信息,例如物体的检测、分割和分类[37]。
与这些现有方法不同,我们在提出的SCMTL架构中,利用共享层处理不同任务之间的统计相关性,并利用任务特定层处理任务之间的差异。我们还提出了不同类型的归一化方案,并观察到“逆验证损失”的表现最佳。据我们所知,SCMTL是新颖的,此类技术此前尚未被提出。
3统计相关多任务学习(SCMTL)算法
我们提出了一种用于统计相关任务(SCMTL)的学习架构。我们的架构基于深度卷积神经网络,并包含任务特定层。初始的共享层学习对所有任务都有用的共同信息(见图1)。所提出的SCMTL算法具有通用性,可应用于任何需要学习统计相关任务的问题。在本研究中,我们将SCMTL应用于自动驾驶汽车,并在平均绝对误差(MAE)方面观察到相比现有方法的改进。
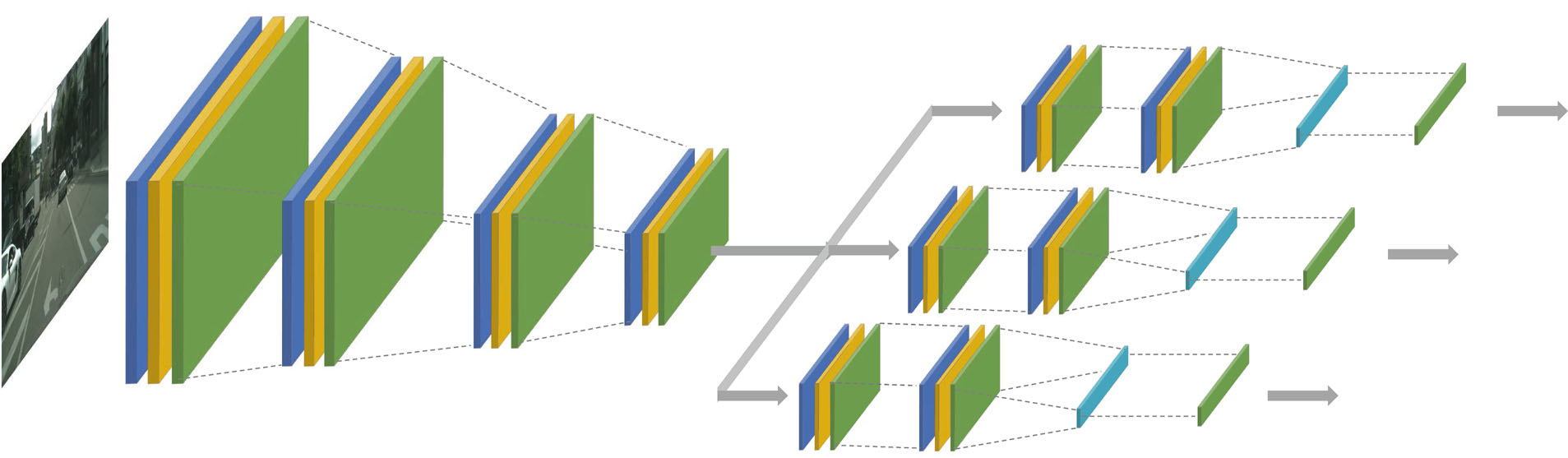
我们探索了不同驾驶控制参数之间的统计相关性,以找到公共参数与任务特定可学习参数之间的适当划分。 在自动驾驶的情况下,需要使用视觉传感器自动学习转向角、加速度、制动压力等控制任务以及车辆左右两侧车道数量等场景信息任务。然而,单个模型可能并不适合所有任务;独立处理每个任务也不是最优选择。为了找到可以同时学习的任务组合,各任务集之间必须存在统计相关性。图2展示了控制任务之间的统计相关性。它显示了Comma.ai数据集中任务对之间的二维散点图[34]。图2表明制动b和加速度a高度相关,而在大多数区间内,转向角s与加速度和制动也具有高度相关性。我们观察到左侧和右侧车道数(l L , l R )彼此之间也相关;然而,在{s,a, b}和{lL , l R} 这两个集合之间没有强相关性。因此,在我们提出解决方案中,采用两个独立的模型学习得到的,一个用于控制任务,另一个用于车道信息任务。
这两个模型都继承了图1中所示的相同架构,如下文各小节所述。
3.1提出的SCMTL网络架构
使用卷积神经网络(CNN)实现的多任务学习通过启用归纳迁移来实现,利用学习对每个独立任务都有信息量的共同特征的层。我们观察到,如果所学习的任务之间存在统计相关性,并且共享层与任务特定层之间建立了适当的平衡,则这种参数共享将改善模型。
在本工作中,我们通过引入表现出强相关性的任务集之间的归纳迁移,利用多任务学习(MTL)来改进自动驾驶模型。因此,我们提出对控制任务集和车道信息任务集进行分离学习。由于这些任务集之间的相关性显著,所提出的SCMTL网络架构以包含四个卷积块的公共分支开始。每个任务特定分支由五个卷积块组成,最终的激活被展平以回归每个任务的值。与单任务学习模型不同,SCMTL中的初始公共层通过学习不同任务间共同有用的信息实现了泛化。
在提出的SCMTL中,为了保持共享层和任务特定层之间网络参数的平衡,我们提出在共享层中使用更多数量且滤波器大小更大的滤波器,而在任务特定层中使用较少数量且滤波器大小更小的滤波器。因此,在共享层中,滤波器大小呈递减趋势,而滤波器数量呈递增趋势;而在任务特定层中,滤波器的大小和数量均呈递减趋势。这种设计有助于初始层学习场景中存在的多个任务共有的全局特征,而任务特定层仅学习任务特定的局部特征[5]。全局特征包括道路形状、车道标记和交通(见图4)。
3.2权重方案
具有不同范围的多任务学习会使模型仅对具有较大范围的任务收敛,而较小范围的任务可能会被忽略。这是因为优化器通常旨在最小化总损失幅度,并朝着仅增加大范围任务重要性而降低其他任务重要性的方向收敛。为了在此类多任务场景下训练模型,有两种方法可以消除范围差异的影响:将每个任务归一化到特定范围,或为每个任务分配一个权重因子[18]。
神经计算与应用
123
我们提出了一种目标函数,用于最小化组合损失以及个体损失。设x ¼ fxig N i¼1为训练图像集合,y ¼ f yj igi¼=N;j¼Nt ¼1 ¼1 i;j为对应标签集合,其中N为训练样本数量, Nt为任务数量。为了便于表述,我们定义W ¼ fW ig L+1 ¼1 i为网络的权重,B ¼fBig L+1 ¼1 i为偏置,该网络具有 L+ 1层(图1)。为了学习所有任务,我们提出以下目标函数:
L ¼ min X Nt j=1 xj Lj(x; W; B); ð1Þ
其中,第j个任务的贡献通过xj 控制,该权重应用于相应任务的均方误差(MSE)损失函数(Lj):
L ¼ min 1 b X N t j=1 x j X b i=1 ðy j i y^ j iÞ 2 ; ð2)
其中b是小批量大小,^yj i 是估计任务值。对于^y的估计,在本研究中我们考虑了三种选择权重xj的策略:
•方案I:等权重,即在此方案中每个任务使用xj ¼ 1。该方法可能导致具有更宽范围的任务训练收敛,而其他任务可能仍未被学习。
•方案II:我们建议根据方案I获得的验证损失对每个任务进行加权。设 Lv j 为第j个任务在方案I中获得的验证损失。利用这些验证损失,每个损失函数的权重计算如下:xj ¼ 1=Lv j, 该方案有助于解决范围变化的问题,并确保模型仅在每个特定任务的损失最小化时才收敛。
•方案III:在此方案中,权重的选择与每项任务的误差范围成反比,以使每项任务对整体目标函数的贡献相等。因此,对于转向角xs ¼ 0:1,加速度xa ¼ 0:2, 以及制动xb ¼0:7被采用。
在第4.2节中,我们分析了每种加权方案的影响,结果表明逆向验证(即方案II)有助于更好地收敛。关于梯度计算、反向传播以及学习到的权重的更新将在第3.3节中讨论。
3.3所提出的损失函数的随机梯度下降
给定一个具有L + 1 层的网络,其中回归器位于最后一层(ðL + 1Þ‐thlayer),第l层表示任意中间层。网络参数W和B通过使用随机梯度下降(SGD)获得。 回归层输出hrðxiÞ ¼^yi、最后的卷积特征层hLðxiÞ以及任意中间层hlðxiÞ可定义为:
hrðxiÞ ¼ WrhLðxiÞ + Br ð3)
hLðxiÞ ¼ W WLhlðxiÞ + BL Þ; for l ¼ L 1 ð4)
hlðxiÞ ¼ W Wlhl1ð xiÞ + Bl 1=bP b k=1 jjWl h l1ð xiÞ + B ljj k 2 ! ð5)
其中xi 是给定输入,W是激活函数。在我们的实现中,使用了修正线性单元(ReLU)激活函数,这也有助于避免梯度消失问题。
损失函数 L 关于权重(Wr;WL) 和偏置(Br;BL) 的梯度可以计算为:
神经计算与应用
123
oL oWr ¼ o oWr X Nt j=1 xj 1 bX b i=1 yj i hj rðxiÞ 2 ! ð6)
oL oWr ¼ X Nt j=1 2xj b X b i=1 y j i hj rðxiÞ hj LðxiÞ > ð7)
oL oBr ¼ 2 bX N t j=1 xj X b i=1 y j i hj rðxiÞ ð8)
oL oWl ¼ X N t j=1 2xj b X N i=1 glh j L1ð xiÞ > ð9)
oL oBl ¼ 2 bX N t j= 1 x j X b i=1 gl ð10)
gL ¼ W > r ðy j i hj r ðxiÞÞ QðOLðxiÞÞOLðxiÞ ð11)
gl ¼ W > l+1gl+1 OlðxiÞ ; l ¼ 1; 2;::; L 1 ð12)
其中中间函数Q和O的表达式为[9]:
QðOLð x iÞÞ , I jjOLð x iÞjj2 ðOLð x iÞÞ O Lð x iÞ T jjOLð x iÞjj N t 2 ð13)
OlðxiÞ,Wlhl1ðxiÞ + Bl; l ¼ 1; 2;::; L ð14)
其中I表示单位矩阵。使用随机梯度下降更新模型参数 (W;B)的规则可以定义为:
Wr:¼ Wr g oL oWr ð15)
Wl:¼ Wl g oL oWl ; l ¼ 1; 2;::; L ð16)
Br:¼ Br g oL oBr ð17)
Bl:¼ Bl g oL oBl ; l ¼ 1; 2;::; L ð18)
随机梯度下降(SGD)中的一个挑战是为每个小批量选择合适的学习率g。 使用随机梯度下降进行优化可能会导致过拟合, 如图8中所示的提出的模型及其变体。为了避免过拟合,不使用丢弃法,而是采用[17],早停准则[1]。
3.4变体架构
为了比较所提出的SCMTL架构的效率,还实现了三种变体,如图3所示。
神经计算与应用
123
早期分离(ES)网络使用相对较少的共享卷积块和更多的任务特定分支中的块。我们还使用了 Inception[35]和ResNet[19]提出的残差连接,以提高该网络的性能。带注意力的早期分离(ESA)使用注意力机制[5], 关注场景中最重要的区域,并忽略较不重要的区域。 ESA与ES架构类似,只是在输入处额外增加了一个带有注意力机制的卷积层。无分离网络(NS)仅包含一个单一分支,该分支类似于ES的中间分支,并增加了卷积层。

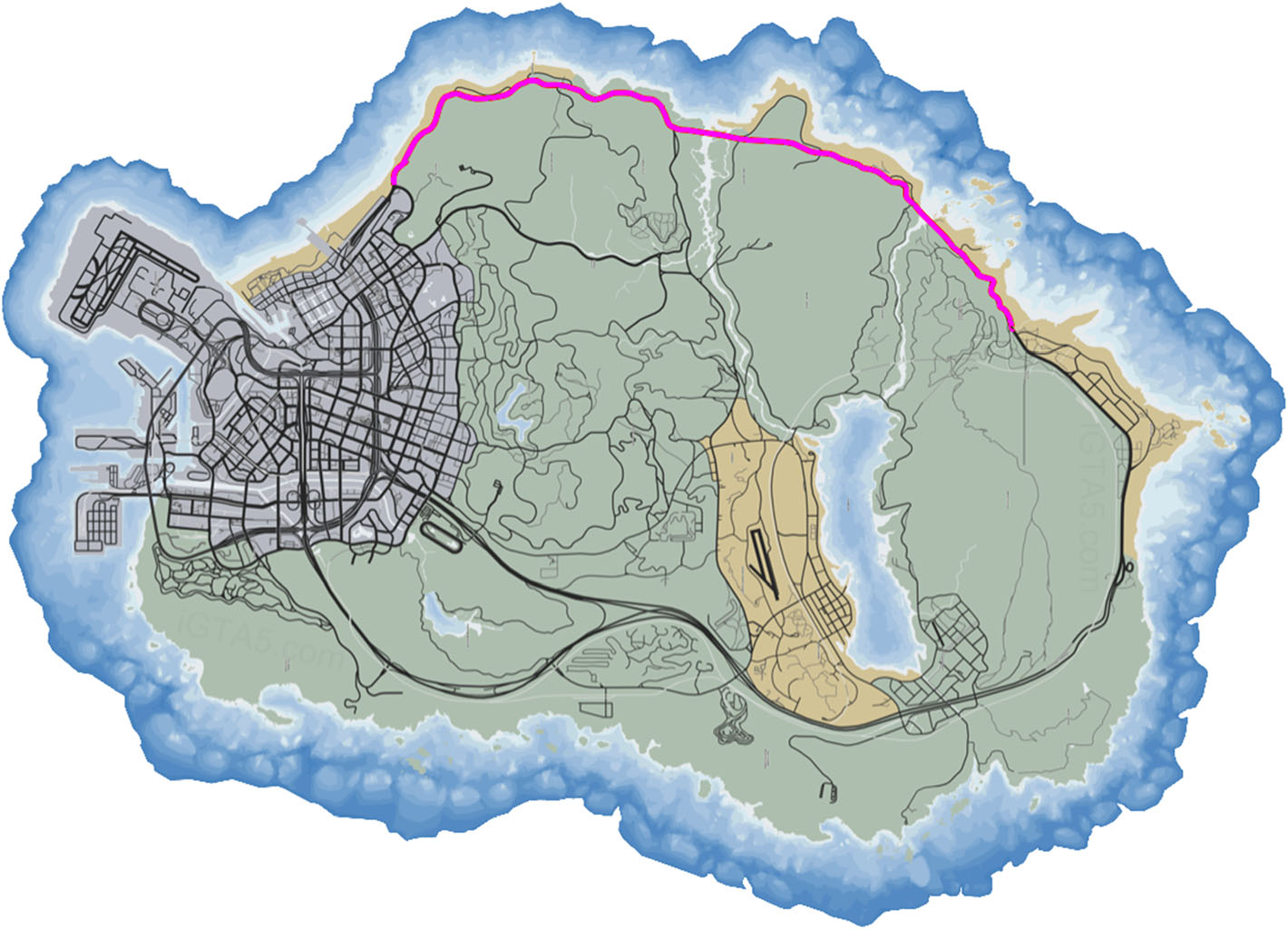
图5GTA‐V仿真环境地图。一辆车辆在该城市的道路上行驶, 道路由品红色线标记。路线中包含左转和右转,道路上有随机交通移动(建议彩色查看) (在线彩色图)
神经计算与应用
123
块以增强网络的表示能力。所有层都学习共同特征以及特定任务的特征。
4实验与结果
4.1数据集与实现细节
数据集:实验在五个数据集上进行,包括Comma.ai [34], 、Udacity[38], 、伯克利深度驾驶(BDD) [41],、SullyChen的[10]以及新提出的GTA V数据集。这五个数据集均由在高速公路和城市道路中拍摄的多个视频组成。Comma.ai数据集[34]是一个公开可用的自动驾驶汽车数据集,采集于高速公路,包含7.25小时的驾驶数据。为了公平比较,我们采用了与[11]相同的方法,并从Comma.ai数据集中使用了15万帧。Udacity数据集 [38]包含使用三个前向摄像头(左、中、右)采集的多个驾驶视频,为公平比较,我们仅选取中心摄像头的数据,遵循[11][15]中报告的相同协议。伯克利深度驾驶 (BDD)数据集[41]的驾驶参数未公开;我们使用该数据集进行车道信息的评估。我们利用BDD提供的可行驶区域分割(10万张高分辨率图像)标注来辅助生成车道信息标注。SullyChen的数据集[17]包含在城市和城市道路上采集的4.5万张图像。用于评估的在模拟器中的模型,我们从GTA‐V环境生成了合成驾驶数据,这些数据由在高速公路上多次会话中采集的70万张图像序列组成(见图5)。我们将每个数据集分为三部分, 70%用于训练的图像, 20%用于验证,以及 10%用于测试。这些数据集的概要如表1所示。所有实验均在配备 NVIDIAGTX‐1080ti显卡、i7处理器和32GB内存的设备上进行。
模型训练:对于驾驶参数预测的实验,我们训练了提出的模型(见
| 表1 | 基准数据集中可用标注的驾驶参数以及本研究中为车道信息所完成的标注的汇总 |
|---|---|
| Comma.ai Udacity BDD Chen GTA‐V | |
| 帧 | 522,434 39,422 100,000 40,000 700,000 |
| FPS | 20赫兹 20赫兹 20赫兹 20赫兹 – |
| 小时 | 7.25小时 0.5小 时 – – |
| 条件 | 高速公路/城市城市城市/街道城市高速公路 |
| 位置 | 加利福尼亚州/美国 加利福尼亚州/ 美国 加利福尼亚州/美国 加利福尼亚州/美国 加利福尼亚州/美国 |
| 照明 | 白天/夜晚 Day day day day |
| 可用标注 | 转向角 p p p p |
| 加速度 p p p p | |
| 速度 p p | |
| 制动 p p p | |
| 转向扭矩 p | |
| 转向速度 p | |
| 车道信息 | |
| 已完成的标注 | 帧数 110,000 40,000 100,000 40,000 70,000 |
| 左侧车道数 p p p p p | |
| 右侧车道数 p p p p p |
图6提出的多任务模型在Comma.ai数据集上使用权重方案II时各驾驶参数的归一化验证损失[34]。在训练轮数中可观察到各参数损失的收敛情况(建议彩色查看)(在线彩色图)
神经计算与应用
123
| 表2 | 方案I、II、III在 Comma.ai[34], Udacity [38],和GTA‐V数据集上的均方误差(MSE)比较 |
| — | — |
| 数据集 | 方案 转向角 加速度 制动扭矩速度 |
| Comma.ai | I 310 0.024 747 – – II 304 0.011 710 – – III 324 0.022 736 – – |
| Udacity | I 0.004 – – 0.021 0.419 II 0.002 – – 0.015 0.395 III 0.004 – – 0.017 0.412 |
| GTA‐V | I 1.698 – – 1.206 0 II 1.238 – – 1.115 0 III 1.724 – – 1.192 0 |
最佳值以粗体显示
神经计算与应用
123
准确率。在与最先进的方法进行比较时,我们仅限于使用已发表结果中采用的指标[12, 24], ,即在 Comma.ai和Udacity数据集上分别定义的MSE(均方误差) 1 NPN i¼1ðyi ^yiÞ 2以及RMSE(均方根误差) ffiffiffiffiffiffiffiffiffiffiMSEp。此外,我们还通过误差频率图进行了扩展分析,从而能够区分误差最大和最小的输出区间。
4.2提出的加权方案的比较
为了分析第3.2节中讨论的三种加权方案的性能,我们使用提出的SCMTL在Comma.ai[34], Udacity[38]和 BDD[41]数据集上学习驾驶参数。图6和7分别显示了在Udacity和Comma.ai数据集上方案II中三个损失项随迭代次数的收敛情况。使用逆验证损失的加权方法(方案II)在所有三个数据集上的表现均优于其他两种方案(见表2)。这是因为该方法在任务特定损失之间具有归一化效果,从而抑制了由于不同任务范围差异而产生的偏差。我们在本文的其余实验中选择了方案II。
4.3SCMTL与ES、ESA和NS网络的比较
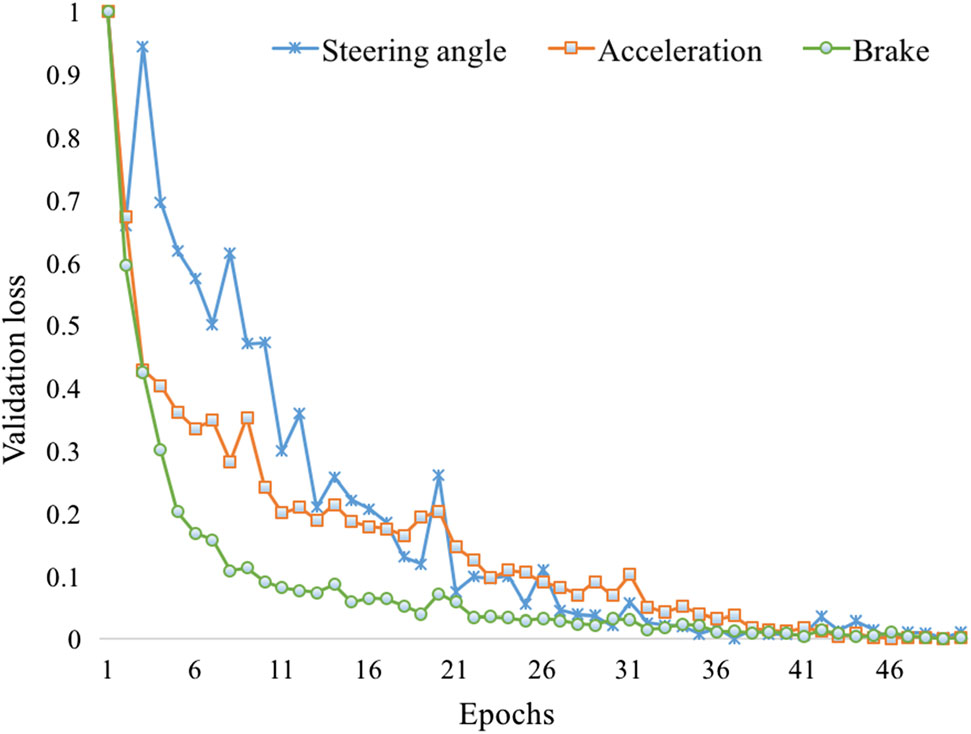
我们在Comma.ai、Udacity和BDD数据集上训练了提出的 SCMTL网络以及图3中所示的ES、ESA和NS,使得每个模型都能根据单个查询图像预测所有驾驶参数。在Comma.ai数据集上,验证损失随训练轮数变化的曲线如图所示
 )
)
 )
)
神经计算与应用
123
表3在Comma.ai[34], Udacity[38], SullyChen的[10],和GTA‐V数据集上针对驾驶参数的方案II评估矩阵
| 数据集 | Loss参数多任务 | 单任务 |
|---|---|---|
| NS ES ESA 提出的 自动驾驶系统 [34] PilotNet [4] 提出的 | ||
| Comma.ai验证损失转角向度 | 1111 778 1567 304 1065 606 345 | |
| 加速度 | 0.190 0.024 0.019 0.011 0.022 0.143 0.008 | |
| 制动 | 380 522 883 710 22656 23085 22890 | |
| 平均绝对误差 ± STD 转角向度 | 4.656 ± 0.403 19.021 ± 21.595 20.820 ± 21.595 3.614– 18.350 0.149 ± 33.320 0.140 ± 28.918 0:023 22:442 | |
| 加速度 | 0.378 ± 0.341 0.483 ± 0.347 0.475± 0.347 0:037 0:270 0.480 ± 0.265 0.625 ± 0.338 0.059–0.291 | |
| 制动 | 6.597 ± 0.094 67.126 ± 73.366 68.490 ± 73.366 3:961 12 74.136 ± 33.760 62.943 ± 21.984 41.900 ± 19.014 | |
| Udacity验证损失转向角度 | 0.003 0.005 0.006 0.002 1.673 1.650 1.621 | |
| 转向扭矩 | 0.020 0.016 0.019 0.015 0.020 0.016 0.017 | |
| 转向速度 | 0.411 0.496 0.421 0.395 0.460 0.489 0.433 | |
| 平均绝对误差 ± STD 转向角度 | 0.181 ± 0.374 0.184 ± 0.312 0.170± 0.410 0.131–0.217 0.106 ± 0.410 0.098 ± 0.295 0:074 0:366 | |
| 转向扭矩 | 1.2918 ± 0.395 1.31 ± 0.210 1.630± 0.571 1.220–0.428 1.120 ± 0.610 1.144 ± 0.376 1:106 0:471 | |
| 转向速度 | 2.985 ± 1.887 3.06 ± 1.085 2.909± 1.683 2.875–1.157 2.578 ± 1.115 2.560 ± 1.568 2:449 1:231 | |
| 陈的验证损失转向角度 | – – – – 59 53 28 | |
| 平均绝对误差 ± STD | – – – – – 0.093 ± 0.023 0.235 ± 0.018 0.056–0.011 | |
| GTA‐V验证损失转向角度 | 1.789 1.238 1.674 1.238 1.673 1.650 1.621 | |
| 速度 | 1.243 1.182 1.142 1.115 1.190 1.174 1.168 | |
| 制动 | – – – – 0.006 0.004 0.001 | |
| 平均绝对误差 ± STD 转向角度 | 0.060 ± 0.884 0.013 ± 0.831 0.019± 0.860 0:012 0:711 0.012 ± 0.798 0.011 ± 0.772 0.009–0.747 | |
| 速度 | 13.475 ± 2.724 13.874 ± 2.536 13.402 ± 2.879 9:118 1:968 12.763 ± 2.935 10.091 ± 2.771 9.239–2.347 | |
| 制动 | 0.045 ± 0.122 0.060 ± 0.102 0:023 0:097 0.067± 0.045 0.088 ± 0.098 0.078 ± 0.077 0.042–0.065 |
注:ES早期分离,ESA带注意力的早期分离,NS无分离,SD标准差,MAE平均绝对误差,STD标准差。验证损失的最低值表示最佳性能。SullyChen的数据集仅包含转向角,因此仅报告转向角的评估结果。目前BDD数据集不包含任何控制参数,因此未进行评估
神经计算与应用
123
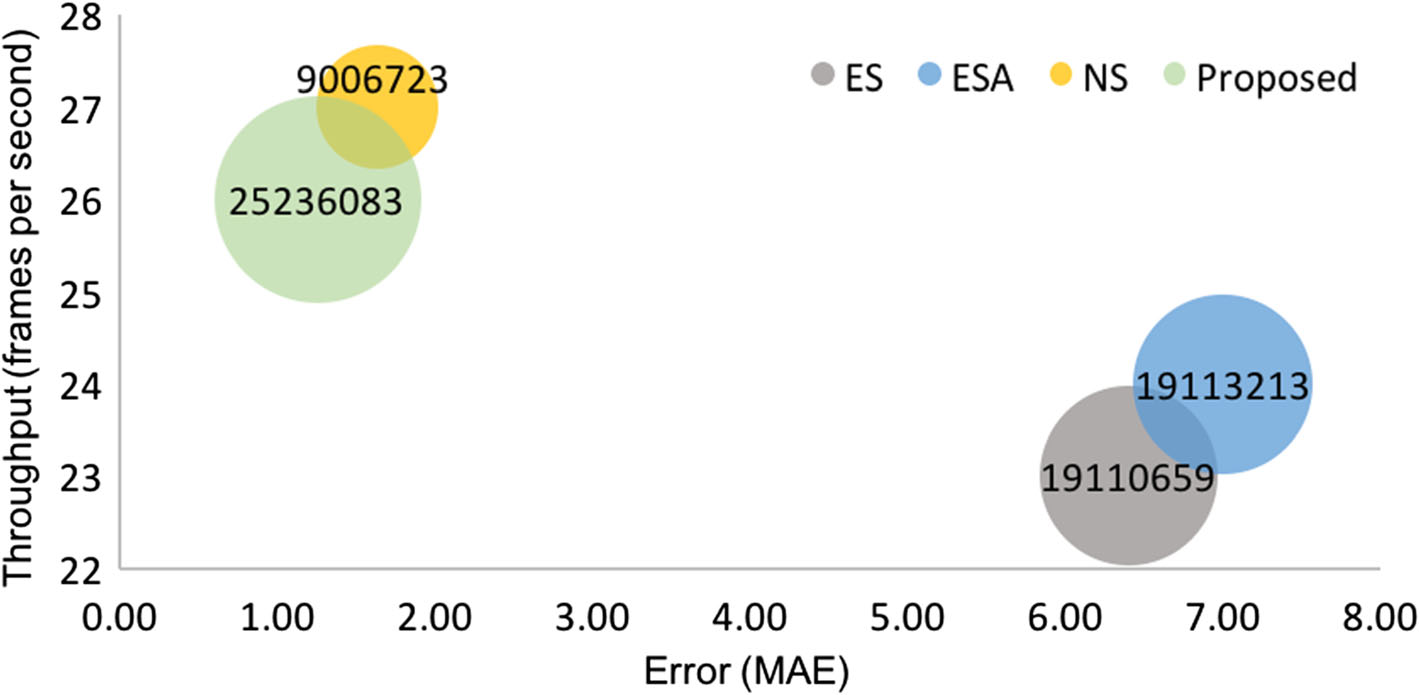
图9每秒推理次数与平均绝对误差、网络参数数量的关系。说明在三个数据集( Comma.ai、Udacity、 GTA‐V)上预测误差与吞吐量 (每秒帧数)之间的关系(彩色查看效果最佳)(在线彩色图)
 )
)
神经计算与应用
123
图8。与ES、ESA和NS相比,提出的SCMTL模型以更小的验证损失更快地收敛。
训练和测试不同模型的3总结见表3。在 Comma.ai数据集上,我们提出的模型在转向角、加速度和制动上的验证损失分别为304、0.011和710。另一方面,NS在制动估计的验证损失上优于所有模型,但提出的模型在测试数据集上的MAE和STD方面超过了所有变体。类似地,在Udacity和GTA‐V数据集的测试集上,提出的模型在多任务问题上也优于所有变体。三个控制任务之间的统计相关性(图2)有助于提出的模型更好地学习前四个模块中的共同特征,从而提升了SCMTL的泛化性能。
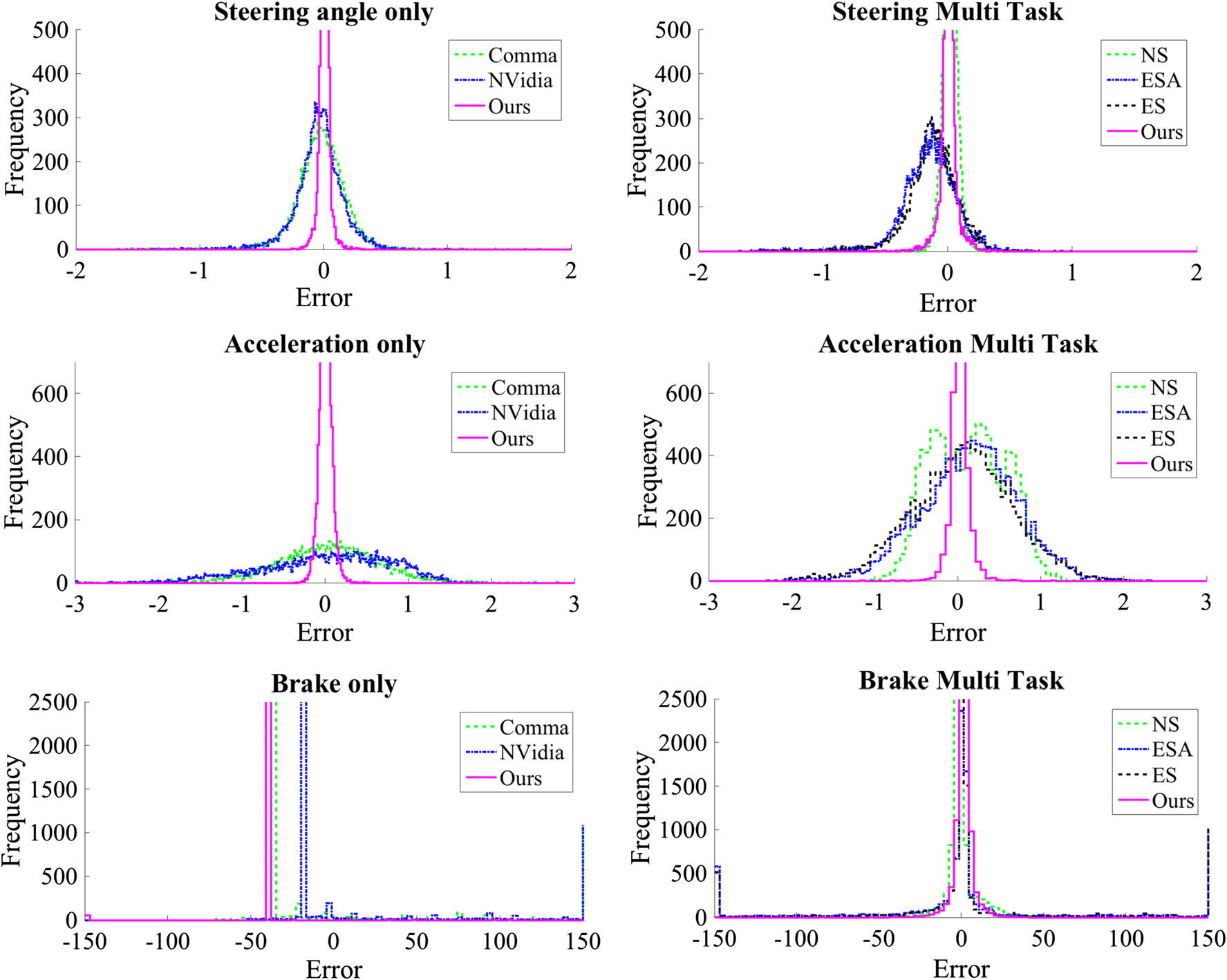
真实值s、a、b^与相应的预测值^s、^a、b之间的误差频率用于分析整体误差分布。图10展示了提出的模型及其在Comma.ai上单任务和多任务学习变体的误差频率图。图10显示了多任务学习算法的误差直方图。与其他模型相比,提出的SCMTL在零误差附近的峰值更大且标准差更小,表明该模型显著优于其他变体。
4.4错误与吞吐量比较
我们对提出的SCMTL以及早期分离、ESA和无分离的错误、吞吐量和模型参数数量进行了分析。图9展示了在Comma.ai、Udacity和GTA‐V数据集上的这一分析结果。一个高效的模型应在具有较少
具有最高吞吐量的网络参数。对于Comma.ai,我们注意到ES、ESA和NS的错误明显高于提出的模型。在所有模型中,ES和SCMTL的吞吐量几乎相同,分别为 27fps和26fps。在Udacity和GTA‐V数据集上,提出的模型在更小的错误和更大的吞吐量方面表现出更优的性能。
4.5单任务学习(STL)与多任务学习(MTL)的对比
在Comma.ai、Udacity、SullyChen和GTA‐V数据集上进行了STL实验,而MTL实验则在除SullyChen的仅包含转向角的数据集[10],之外的所有数据集上进行。为了公平比较,我们训练了提出的SCMTL模型、ES、ESA、NS以及两种最先进的模型
表3还表明,除了在Udacity数据集上STL模型略优外,提出的SCMTL在所有其他情况下均优于MTL变体和STL模型。 在Comma.ai和Udacity数据集上,将我们的方法与最先进的单任务学习方法在转向角上的表现进行比较,结果分别如表4和5所示。先前的研究表明,注意力机制的表现优于全卷积网络和长短期记忆网络[5];然而,提出的SCMTL方法在所有对比方法中表现最佳,即使该模型同时预测多个控制参数,仍取得了最低的平均绝对误差和标准差。
最近,已在Udacity数据集上探索了使用端到端深度学习[15]来预测转向角。类似地,Chi等人[12]使用了多种变体的长短期记忆网络(LSTM),并结合或不结合预训练的 AlexNet和VGG‐16。我们将我们的方法与二维长短期记忆网络[12]和三维长短期记忆网络[15]进行了比较。我们还训练了PilotNet 和自动驾驶系统以在Udacity数据集上进行转向角估计。 我们提出的SCMTL模型表现优于这些最先进的方法,达到了0.0595的均方根误差(见表5)。此外,我们提出的模型在不损害转向角估计性能的前提下,同时预测了转向角以及另外两个控制参数。这些实验表明,如果任务之间存在统计相关性,并且使用诸如逆验证损失之类的智能加权方法进行组合,多任务学习中的归纳迁移可以改善所有任务的结果。
4.6估计左侧和右侧车道
我们已对表1中提到的五个数据集标注了车辆左右两侧的车道数量。标注的数据集包含多种具有挑战性的场景,例如光照条件差、道路可见性差、车道标记不清、高速公路车道之间的区分以及应急车道(图11)。
对于车道估计,我们在全部五个数据集上训练了提出的SCMTL、PilotNet和自动驾驶系统。SCMTL模型的最终层包含两个任务特定网络分支,用于估计车辆左侧和右侧可用的车道数量。我们还分别训练了自动驾驶系统和 PilotNet(每次一个任务)以估计车道信息。表6显示,自动驾驶系统和PilotNet在车道信息估计方面表现均相当出色。另一方面,所提出的模型被训练为同时预测两个任务。共享道路和车道的基本特征提升了该模型的性能,并使其超过了所有单任务模型。我们在GTA‐V和Sully Chen的 100%数据集上获得了准确率,在Comma.ai和 Udacity数据集上获得了超过99:9%的准确率(见表6)。 BDD数据集包含高速公路以及具有挑战性场景的街景图像,这使得该数据集在车道参数估计方面较为困难(见图11)。我们在BDD数据集上分别获得了97:4%和96:6%的准确率(见表6)。
为了进一步验证我们的假设,即多任务学习更适合于统计相关的任务,我们使用单一的多任务学习网络同时估计了相关任务和不相关任务。在本实验中,我们同时估算了五个不同的任务,包括转向角、加速度、制动、左侧车道和右侧车道。尽管进行了严格的训练,但我们观察到与前三个任务和后两个任务分别学习相比,性能有所下降。这是因为在我们的数据集中,左侧和右侧的车道数量与前三个任务不相关。该实验
| 表4 | 在Comma.ai数据集上转向角估计的比较[34] |
|---|---|
| 模型 | MAE SD |
| 卷积神经网络?全卷积网络[24] | 2.54 3.19 |
| 卷积神经网络?长短期记忆网络[24] | 2.58 3.44 |
| 卷积神经网络?注意力(k ¼ 0)[24] | 2.52 3.205 |
| 卷积神经网络?注意力(k ¼ 10)[24] | 2.56 3.51 |
| 卷积神经网络?注意力(k ¼ 20)[24] | 2.44 3.20 |
| 卷积神经网络 [11] | 2.42 3.26 |
| 提出的 | 1.106 1.65 |
关键术语:MAE平均绝对误差,SD标准差,FCN全卷积网络, Att.注意力
| 表5 | 转向角估计评估,使用均方根误差(RMSE)在Udacity数据集上与当前方法的比较 |
|---|---|
| 模型 | RMSE |
| 预测为零[15] | 0.2076 |
| 三维长短期记忆网络[15] | 0.1123 |
| 迁移[15] | 0.0709 |
| 预测为零[12] | 0.2077 |
| 预测均值[12] | 0.2098 |
| AlexNet[12] | 0.1299 |
| VGG‐16[12] | 0.0948 |
| 深度转向(LSTM)[12] | 0.0609 |
| PilotNet[4] | 0.0986 |
| 自动驾驶系统[34] | 0.0831 |
| 提出的 | 0.0595 |
零和均值模型[12]始终对训练数据集预测零值和均值
神经计算与应用
123
表明如果在不相关任务上进行多任务学习,性能实际上可能会下降。这是因为在共享层中学到的共同特征对于任何任务都不是最优的。
4.7定性评估
从Comma.ai数据集中选取了包含高速公路上不同程度转弯的少量片段。对于这些选定的片段,我们评估了提出的模型、PilotNet和自动驾驶系统在转向角估计方面的表现。图13和图12显示,提出的模型具有在这些场景中,表现优于自动驾驶系统和PilotNet。
我们还在Comma.ai数据集上评估了提出的模型在不同光照条件下的车道信息,包括曝光不足、过度曝光以及车道标线不清的情况,以检验模型的鲁棒性(图 11)。在具有挑战性的场景中,该提出的模型正确预测了车辆左侧和右侧的车道数量。
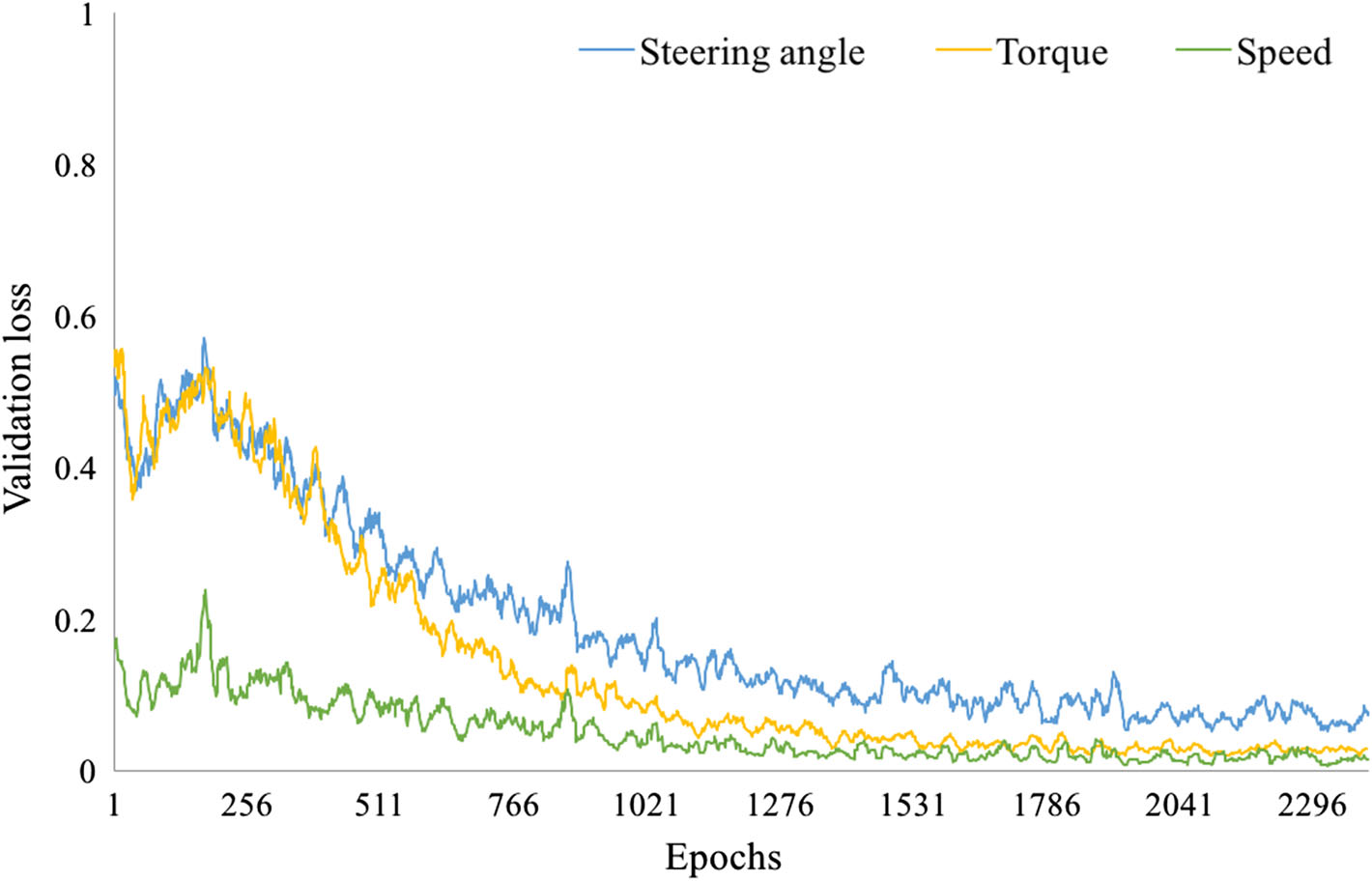
我们还在GTA‐V环境中的以下参数上评估了提出的模型:转向角、速度、制动和车道信息(见图14和 15)。从图15可以看出,预测转向角(橙色)跟随实际转向角(蓝色),误差较小,且可通过平滑滤波器进一步减小。图14还表明,提出的模型能够在具有挑战性的场景中正确估计车道信息。
5结论与未来工作
本文提出了一种用于统计相关任务多任务学习( MTL)的深度学习架构。所提出的架构包含若干共享层,用于学习多个任务之间的共同特征。这些共享层之后接有任务特定分支,用于学习各任务独有的特征。为了处理不同任务之间的范围差异,还研究了三种归一化方案,其中逆验证误差加权方案表现最佳。所提出的统计相关多任务学习(SCMTL)相比单任务学习(STL)具有更少的网络参数,同时实现了更好的性能。这是因为多任务
 )
)
| 表6 | 在Comma.ai[34],Udacity[38], BDD[41], SullyChen的[10],和 GTA‐V数据集上进行的车道位置估计评估,其中使用百分比准确率为评估指标 |
|---|---|
| 数据集参数多任务模型 | 自动驾驶系统[34] PilotNet[4] Ours |
| Comma.ai Left | 99.4 99.6 99.9 |
| 右 | 99.3 99.5 99.8 |
| Udacity Left | 97.23 98.4 99.4 |
| 右 | 98.8 99.2 99.7 |
| BDD Left | 87.2 92.7 97.4 |
| 右 | 88.4 89.1 96.6 |
| 苏利·陈 Left | 98.9 99.5 100 |
| 右 | 99.4 99.2 100 |
| GTA‐V Left | 98.9 99.4 100 |
| 右 | 99.4 99.1 100 |
(关键词:lL:车辆左侧车道,lR:车辆右侧车道)
神经计算与应用
123
加强联合学习,实现比单任务学习更好的网络训练。 SCMTL方法被用于同时估计驾驶控制参数,包括转向角、制动和加速度。该估计基于单个前视摄像头捕获的数据进行。使用了四个公开可用数据集,包括 Comma.ai[34],Udacity[38],伯克利深度驾驶( BDD)[41],以及SullyChen的[10],以展示所提出解决方案的有效性。此外,还提出了一种使用 GTA‐V游戏环境获得的新数据集。在这些数据集上,SCMTL的性能与另外三种架构进行了比较,包括早期分离(ES)、带注意力的早期分离(ESA)和无分离(NS)。SCMTL的表现优于STL、 ES、ESA、NS以及其他对比方法。
使用相同的架构,还估计了当前所占车道左侧和右侧的车道数量。对于车道数量估计网络的训练,在来自五个数据集的360,000帧上进行了额外的标注。提出的算法在此任务上取得了优异的性能。
 )
)
 )
)
神经计算与应用
123
提出的SCMTL方法的实现、新开发的GTA‐V数据集以及车道标注将通过 https://cvla‐b.lums.edu.pk/scmtl/公开提供。 未来,我们旨在将此项工作的范围从自动驾驶汽车扩展到自主无人机,特别是通过认知多智能体实现的协作式无人机[43],其中我们将研究无人机控制与导航参数中的统计相关性[39]。我们还计划扩展合成GTA‐V数据集,加入密集城市场景。此外,我们计划增加立体或PTZ摄像头(例如安装在警车上的摄像头),并致力于估计用于自动化提取三维信息的相机内参和外参。这将用于改进驾驶控制和车道参数的估计,因为它们自然地与三维场景结构以及场景中存在的动态物体相关联。


















 1787
1787

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









